---
title: "Diagnóstico Completo de Supuestos en Regresión Lineal (OLS)"
author: "Paulo Villarroel / Hazla con Datos"
date: "2026-03-18"
format:
html:
theme: cosmo
toc: true
toc-depth: 3
toc-title: "Contenidos"
code-fold: false
code-tools: true
code-line-numbers: true
number-sections: true
smooth-scroll: true
highlight-style: github
df-print: kable
lang: es
license: "CC BY 4.0"
bibliography: referencias.bib
nocite: '@*'
---
## Introducción
Este documento cubre el diagnóstico de los **5 supuestos clásicos** de la regresión lineal por mínimos cuadrados ordinarios (OLS):
1. **Linealidad** — la relación entre $Y$ y cada predictor es lineal.
2. **Normalidad de residuos** — los errores se distribuyen $\varepsilon \sim N(0, \sigma^2)$.
3. **Homocedasticidad** — la varianza del error es constante: $\text{Var}(\varepsilon_i) = \sigma^2$.
4. **Independencia** — no hay autocorrelación: $\text{Cov}(\varepsilon_i, \varepsilon_j) = 0$ para $i \neq j$.
5. **No multicolinealidad** — los predictores no son combinaciones lineales entre sí.
Para cada supuesto se presenta el test formal, el diagnóstico visual, las consideraciones prácticas y las referencias bibliográficas correspondientes.
::: {.callout-tip}
## Regla general
Los tests formales son orientativos. Con muestras grandes ($n > 100$), tienden a rechazar $H_0$ por desviaciones triviales e irrelevantes en la práctica. **Siempre complementar con diagnósticos visuales.**
:::
### Referencias generales
@fox2016; @wooldridge2020; @faraway2015; @taubes2010.
## ¿Por qué validar los supuestos? {#sec-por-que}
Antes de entrar en los tests y gráficos, vale la pena detenerse en una pregunta fundamental: **¿por qué deberíamos dedicar tiempo a evaluar los supuestos de un modelo de regresión?** La respuesta corta es que sin esta validación, los resultados de un modelo pueden parecer correctos y, sin embargo, ser profundamente engañosos.
### El modelo OLS y sus promesas
Cuando ajustamos un modelo de regresión lineal por mínimos cuadrados ordinarios (OLS), el software siempre nos entregará coeficientes, errores estándar, p-values e intervalos de confianza. Nada en la mecánica computacional impide que `lm()` produzca resultados incluso cuando los supuestos están completamente rotos. La función no lanza un error ni una advertencia. Simplemente entrega números.
El problema es que esos números tienen una **interpretación estadística válida solo bajo ciertas condiciones**. Esas condiciones son precisamente los supuestos. Si no se cumplen, los coeficientes pueden estar sesgados, los errores estándar pueden ser incorrectos, los p-values pueden ser engañosos, y las predicciones pueden ser inútiles.
### El Teorema de Gauss-Markov: la promesa de OLS
La razón teórica por la que usamos OLS (y no cualquier otro método de estimación) es el **Teorema de Gauss-Markov** [@gauss1809; @markov1912; formalizado por @aitken1935]. Este teorema establece que:
> Si se cumplen los supuestos de linealidad, media condicional cero de los errores ($E[\varepsilon|X] = 0$), homocedasticidad y no autocorrelación ($\text{Cov}(\varepsilon_i, \varepsilon_j) = 0$ para $i \neq j$), entonces los estimadores OLS son **BLUE**: *Best Linear Unbiased Estimators*.
Nótese que Gauss-Markov requiere **incorrelación** de los errores, no independencia completa (condición más fuerte). Independencia implica incorrelación, pero no al revés.
En términos simples: si se cumplen las reglas del juego, OLS es el mejor método posible para estimar los coeficientes. Específicamente, garantiza tres cosas:
- **Insesgados (*Unbiased*):** En promedio, los coeficientes estimados coinciden con los verdaderos valores poblacionales: $E[\hat{\beta}] = \beta$. Dicho de otro modo: si repitieras el estudio muchas veces con muestras distintas, el promedio de tus estimaciones sería el valor correcto.
- **Lineales (*Linear*):** Los estimadores son combinaciones lineales de las observaciones de $Y$. (Esto es una propiedad técnica; en la práctica significa que la fórmula de OLS es una suma ponderada de los datos.)
- **De mínima varianza (*Best*):** Entre todos los estimadores lineales e insesgados posibles, OLS tiene la **menor varianza**. Es decir, es el más preciso: sus estimaciones fluctúan menos de muestra a muestra.
Si alguno de los supuestos falla, OLS pierde al menos una de estas propiedades. El modelo sigue produciendo números, pero ya no son los "mejores" posibles — y en algunos casos, ni siquiera son correctos.
::: {.callout-note}
## Sobre el nombre "BLUE"
Es frecuente encontrar la sigla BLUE sin explicación. Viene del inglés: **B**est **L**inear **U**nbiased **E**stimator. "Best" se refiere específicamente a la eficiencia (mínima varianza), no a una noción vaga de "mejor". La normalidad de errores **no es necesaria** para Gauss-Markov. Sin embargo, sí es necesaria para que los tests $t$, $F$ y los intervalos de confianza sean exactos (no solo aproximados).
:::
::: {.callout-warning}
## La violación más común: endogeneidad
La condición $E[\varepsilon|X] = 0$ (exogeneidad estricta) es probablemente el supuesto más violado en la práctica. Las causas más frecuentes son:
- **Sesgo por variable omitida (OVB):** Si una variable relevante se omite del modelo y está correlacionada con los predictores incluidos, el término de error absorbe su efecto. Los estimadores resultantes son **sesgados e inconsistentes**. La magnitud del sesgo es: $\text{sesgo}(\hat{\beta}_1) = \beta_2 \cdot \delta$, donde $\beta_2$ es el efecto de la variable omitida y $\delta$ la relación entre la omitida y el predictor incluido. **Ejemplo:** si queremos medir el efecto del peso (`weight`) en el rendimiento (`mpg`) pero omitimos la cilindrada del motor, parte del efecto de la cilindrada se "cuela" en el coeficiente de peso, distorsionándolo.
- **Simultaneidad:** $X$ causa $Y$, pero $Y$ también causa $X$ (e.g., precio y cantidad en equilibrio de mercado).
- **Error de medición:** Si un predictor se mide con error, el error de medición se incorpora a $\varepsilon$, correlacionándolo con $X$.
Ningún test de diagnóstico estándar detecta directamente la endogeneidad. Su identificación requiere razonamiento teórico sobre el proceso generador de datos [@wooldridge2020, Cap. 3].
:::
**Referencias:** @gauss1809; @aitken1935; @greene2018 [Cap. 4].
### No todos los supuestos son iguales
Un error pedagógico frecuente es presentar los cinco supuestos como una lista de igual importancia. En la práctica, las consecuencias de violar cada uno son cualitativamente distintas. La siguiente tabla organiza los supuestos por la **gravedad de sus consecuencias**:
| Supuesto violado | ¿Coeficientes sesgados? | ¿Errores estándar incorrectos? | ¿Inferencia inválida? | Gravedad |
|---|:---:|:---:|:---:|:---:|
| **Linealidad** | Sí | Sí | Sí | Crítica |
| **Independencia** | No | Sí (subestimados) | Sí | Alta |
| **Homocedasticidad** | No | Sí | Sí | Alta (corregible) |
| **Normalidad** | No | No (con $n$ grande) | Parcial | Baja–Media |
| **Multicolinealidad** | No | Inflados | Parcial | Contextual |
| **Endogeneidad (OVB)** | Sí | Sí | Sí | Crítica |
Otra forma de organizar los supuestos es por **qué propiedad garantizan**:
| Objetivo | Supuestos necesarios |
|---|---|
| **OLS insesgado** | Linealidad, exogeneidad ($E[\varepsilon|X]=0$) |
| **OLS eficiente (BLUE)** | + Homocedasticidad, no autocorrelación |
| **Inferencia exacta** ($t$, $F$, IC) | + Normalidad de errores |
Esta jerarquía tiene implicaciones directas para la práctica:
**Linealidad es el supuesto más crítico.** Si la relación real entre $Y$ y los predictores no es lineal, los coeficientes $\hat{\beta}$ están sesgados. No hay corrección posible sin reformular el modelo (agregar transformaciones, polinomios, o cambiar de método). Un modelo no lineal con buen $R^2$ puede seguir produciendo predicciones sistemáticamente erróneas en ciertas regiones.
**Independencia y homocedasticidad afectan la inferencia pero no el sesgo.** Cuando estos supuestos fallan, los $\hat{\beta}$ siguen siendo insesgados, pero los errores estándar son incorrectos. Esto significa que los p-values y los intervalos de confianza no son confiables: podríamos declarar significativas variables que no lo son, o viceversa. La buena noticia es que para homocedasticidad existe una corrección directa (errores estándar robustos HC), y para autocorrelación existen los errores HAC (Newey-West).
**Normalidad es el supuesto menos crítico en muestras grandes.** Como se detalla en la @sec-tcl, el Teorema Central del Límite garantiza que la inferencia sobre los $\hat{\beta}$ es aproximadamente válida con $n$ suficientemente grande, incluso sin normalidad de errores. Sin embargo, los **intervalos de predicción** (no de confianza) sí dependen directamente de la distribución de $\varepsilon$, por lo que la normalidad importa si el objetivo es predecir observaciones individuales.
**Multicolinealidad no sesga ni invalida, pero desestabiliza.** Los coeficientes son insesgados pero tienen varianza inflada, lo que los hace sensibles a pequeños cambios en los datos. Si el objetivo es predicción, la multicolinealidad puede ser tolerable. Si el objetivo es interpretar coeficientes individuales, puede ser un problema serio.
**Referencia:** @wooldridge2020 [Cap. 3–5].
### Un ejemplo motivador: cuando el modelo miente
Para ilustrar por qué la validación de supuestos es imprescindible, consideremos un caso donde un modelo parece excelente por sus métricas pero produce conclusiones inválidas:
```{r}
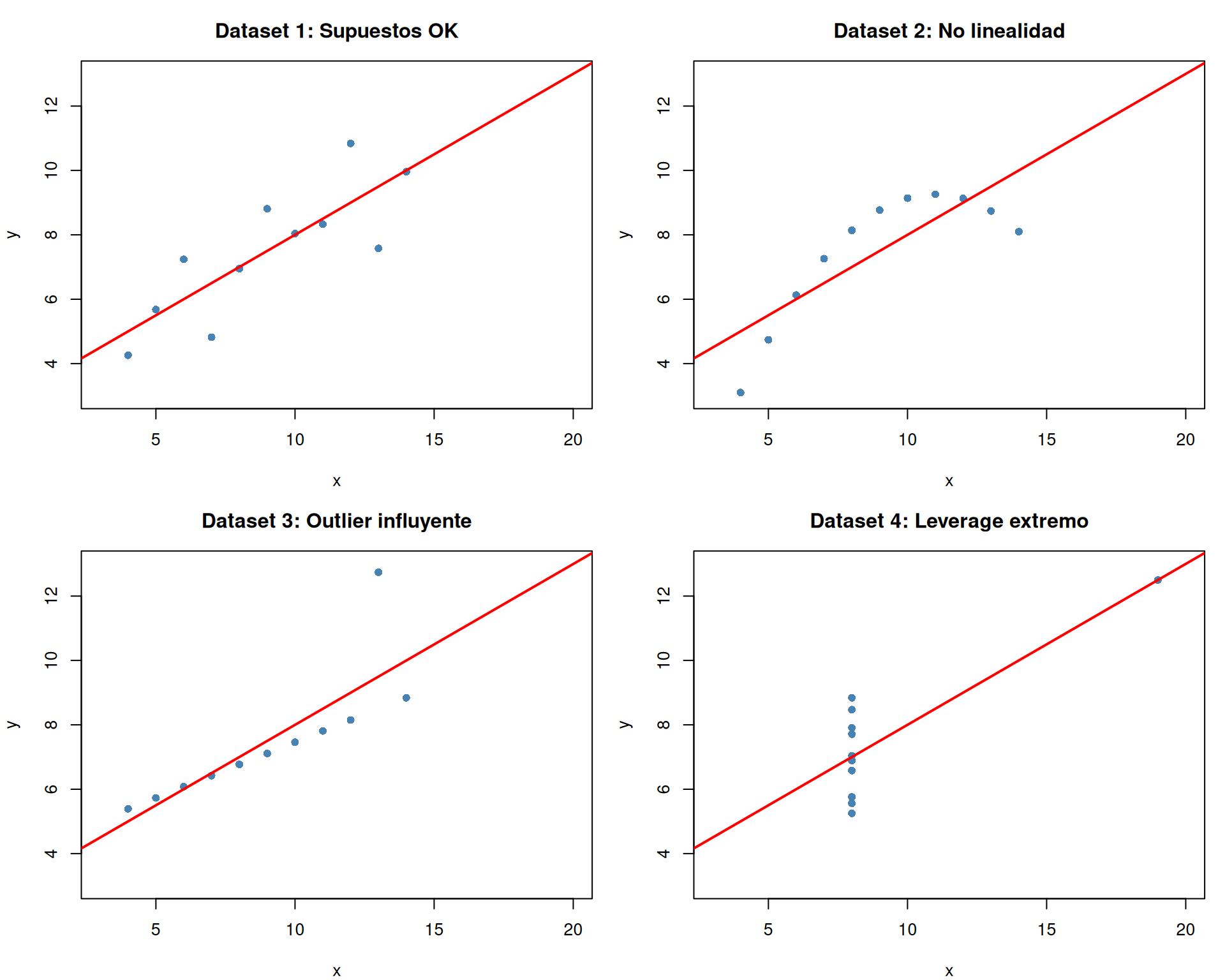
#| label: fig-ejemplo-motivador
#| fig-cap: "Cuatro datasets del Cuarteto de Anscombe. Todos tienen la misma recta de regresión (Y = 3 + 0.5X), el mismo R² (0.67), y los mismos errores estándar. Sin embargo, solo el primero cumple razonablemente los supuestos de OLS."
#| fig-width: 10
#| fig-height: 8
#| code-fold: true
#| code-summary: "Ver código del ejemplo"
data(anscombe)
par(mfrow = c(2, 2), mar = c(4, 4, 3, 1))
# Dataset 1: cumple supuestos razonablemente
plot(
anscombe$x1,
anscombe$y1,
pch = 16,
col = "steelblue",
xlab = "x",
ylab = "y",
main = "Dataset 1: Supuestos OK",
xlim = c(3, 20),
ylim = c(3, 13)
)
abline(lm(y1 ~ x1, data = anscombe), col = "red", lwd = 2)
# Dataset 2: relación no lineal (viola linealidad)
plot(
anscombe$x2,
anscombe$y2,
pch = 16,
col = "steelblue",
xlab = "x",
ylab = "y",
main = "Dataset 2: No linealidad",
xlim = c(3, 20),
ylim = c(3, 13)
)
abline(lm(y2 ~ x2, data = anscombe), col = "red", lwd = 2)
# Dataset 3: outlier influyente
plot(
anscombe$x3,
anscombe$y3,
pch = 16,
col = "steelblue",
xlab = "x",
ylab = "y",
main = "Dataset 3: Outlier influyente",
xlim = c(3, 20),
ylim = c(3, 13)
)
abline(lm(y3 ~ x3, data = anscombe), col = "red", lwd = 2)
# Dataset 4: leverage extremo
plot(
anscombe$x4,
anscombe$y4,
pch = 16,
col = "steelblue",
xlab = "x",
ylab = "y",
main = "Dataset 4: Leverage extremo",
xlim = c(3, 20),
ylim = c(3, 13)
)
abline(lm(y4 ~ x4, data = anscombe), col = "red", lwd = 2)
par(mfrow = c(1, 1))
```
Este es el famoso **Cuarteto de Anscombe** (1973), diseñado específicamente para demostrar que las estadísticas resumidas no son suficientes para evaluar un modelo. Los cuatro datasets producen resultados idénticos en `summary()`:
```{r}
#| label: anscombe-summary
#| code-fold: true
#| code-summary: "Ver comparación numérica"
modelos_anscombe <- list(
lm(y1 ~ x1, data = anscombe),
lm(y2 ~ x2, data = anscombe),
lm(y3 ~ x3, data = anscombe),
lm(y4 ~ x4, data = anscombe)
)
comparacion <- data.frame(
Dataset = paste("Dataset", 1:4),
Intercepto = sapply(modelos_anscombe, function(m) round(coef(m)[1], 2)),
Pendiente = sapply(modelos_anscombe, function(m) round(coef(m)[2], 2)),
R2 = sapply(modelos_anscombe, function(m) round(summary(m)$r.squared, 3)),
p_pendiente = sapply(modelos_anscombe, function(m) {
format.pval(summary(m)$coefficients[2, 4], digits = 3)
})
)
rownames(comparacion) <- NULL
comparacion
```
A pesar de tener los mismos coeficientes, $R^2$ y p-values, solo el Dataset 1 es un caso donde OLS es razonable. En los demás, las conclusiones del modelo son engañosas:
- **Dataset 2** viola linealidad: la relación real es curvilínea y la recta es una aproximación pobre.
- **Dataset 3** contiene un outlier que arrastra la recta; sin él, la pendiente sería muy diferente.
- **Dataset 4** tiene un punto de leverage extremo que define por sí solo toda la relación.
La lección es clara: **`summary()` no reemplaza al diagnóstico de supuestos**. Un $R^2$ alto y p-values significativos no garantizan que el modelo sea válido.
::: {.callout-important}
## El mensaje central
Validar supuestos no es un trámite burocrático ni un ejercicio académico. Es lo que separa un análisis estadístico confiable de uno que puede llevar a decisiones erróneas. En contextos como salud pública, donde las decisiones basadas en datos afectan directamente a las personas, omitir esta validación no es solo una mala práctica estadística — es una responsabilidad ética.
:::
**Referencia:** @anscombe1973.
### ¿Qué hacer cuando un supuesto falla?
Detectar una violación es solo el primer paso. Lo que importa es **qué decisión tomar**. La siguiente tabla resume las acciones recomendadas según el supuesto que falla y la severidad de la violación:
| Supuesto violado | Acción si la violación es leve | Acción si la violación es severa |
|---|---|---|
| **Linealidad** | Agregar términos polinómicos o interacciones | Transformar variables ($\log$, $\sqrt{}$) o usar modelos no lineales (GAM, splines) |
| **Normalidad** | Generalmente ignorable con $n$ grande | Transformar $Y$ (Box-Cox) o usar bootstrap para la inferencia |
| **Homocedasticidad** | Usar errores estándar robustos (HC3) | Usar Weighted Least Squares (WLS) o modelos de varianza explícita |
| **Independencia** | Reportar errores HAC (Newey-West) | Usar modelos para datos correlacionados (GLS, modelos mixtos, series de tiempo) |
| **Multicolinealidad** | Tolerable si el objetivo es predicción | Eliminar predictores redundantes, usar PCA o regularización (Ridge, Lasso) |
| **Endogeneidad (OVB)** | Agregar variables de control o proxy | Variables instrumentales (IV/2SLS), diseños experimentales, diff-in-diff |
::: {.callout-tip}
## Criterio práctico
La pregunta clave al encontrar una violación no es "¿el test rechazó?", sino: **¿la violación es lo suficientemente severa como para cambiar mis conclusiones?** Esto se evalúa comparando los resultados del modelo original con los del modelo corregido. Si los coeficientes y p-values cambian sustancialmente, la violación es relevante. Si apenas se mueven, el modelo original es robusto a esa desviación.
:::
**Referencias:** @fox2016 [Cap. 12–13]; @lumley2002; @zeileis2004.
## Marco conceptual: Pruebas de hipótesis {#sec-marco}
Antes de evaluar los supuestos de OLS, es necesario entender el marco inferencial que sustenta todos los tests que se presentan en este documento. Cada test estadístico sigue una lógica común que, si no se comprende bien, puede llevar a interpretaciones mecánicas e incorrectas de los resultados.
### ¿Qué es una prueba de hipótesis?
Una prueba de hipótesis es un procedimiento formal para decidir si los datos observados son compatibles con una afirmación teórica sobre la población. La estructura es siempre la misma:
- **Hipótesis nula ($H_0$):** La afirmación que asumimos como verdadera *hasta que los datos la contradigan*. En el contexto de diagnóstico OLS, $H_0$ generalmente afirma que el supuesto se cumple (por ejemplo, "los errores son normales", "la varianza es constante").
- **Hipótesis alternativa ($H_1$):** Lo que concluiríamos si los datos contradicen $H_0$.
La idea central es similar a un juicio legal: $H_0$ es la "presunción de inocencia" del modelo. No se busca *probar* que $H_0$ es verdadera, sino evaluar si los datos proveen suficiente evidencia *en su contra*.
**Referencia:** @neyman1933.
### El p-value: qué es y qué no es
El **p-value** (valor p) es la probabilidad de observar un resultado *tan extremo o más* que el obtenido, **asumiendo que $H_0$ es verdadera**. Es decir:
$$p = P(\text{observar algo tan extremo como los datos} \mid H_0 \text{ es cierta})$$
**Ejemplo concreto:** Supongamos que estamos testeando si los errores de nuestro modelo son normales (Shapiro-Wilk). La $H_0$ dice "los errores son normales". Si obtenemos un p-value de 0.42, significa: "si los errores fueran realmente normales, habría un 42% de probabilidad de ver datos como los nuestros". Eso no es sorprendente, así que no tenemos razón para dudar de la normalidad. Si el p-value fuera 0.002, sería como decir: "si los errores fueran normales, solo habría un 0.2% de probabilidad de ver datos así". Eso *sí* es sorprendente, y nos lleva a sospechar que la normalidad no se cumple.
::: {.callout-important}
## Interpretaciones correctas e incorrectas del p-value
**El p-value NO es:**
- La probabilidad de que $H_0$ sea verdadera.
- La probabilidad de estar cometiendo un error.
- Una medida del tamaño del efecto.
**El p-value SÍ es:**
- Una medida de *compatibilidad* entre los datos y $H_0$.
- Un indicador de cuán sorprendentes serían los datos si $H_0$ fuera cierta.
Un p-value de 0.03 no significa que hay un 3% de probabilidad de que el supuesto se cumpla. Significa que, *si el supuesto se cumpliera*, habría solo un 3% de probabilidad de ver datos tan extremos como los observados.
:::
La confusión sobre la interpretación del p-value es tan generalizada que la American Statistical Association publicó un comunicado formal al respecto [@wasserstein2016], enfatizando que el p-value no mide la probabilidad de que la hipótesis sea verdadera ni la importancia práctica de un resultado.
### El umbral de significancia ($\alpha$) y su arbitrariedad
El nivel de significancia $\alpha$ es el umbral que fijamos *antes* de realizar el test para decidir cuándo rechazar $H_0$. Por convención, se usa $\alpha = 0.05$, lo que significa que aceptamos un 5% de riesgo de rechazar $H_0$ cuando es verdadera.
**En la práctica, la regla de decisión es simple:** si el p-value < $\alpha$ (típicamente 0.05), rechazamos $H_0$; si el p-value $\geq$ $\alpha$, no la rechazamos. Piénsalo como un "nivel de sorpresa mínimo": solo concluimos que algo raro pasa si los datos serían bastante improbables bajo $H_0$.
Este umbral es una convención histórica popularizada por R.A. Fisher en los años 1920, no un principio matemático fundamental. Fisher propuso originalmente el 5% como un punto de referencia práctico, no como un criterio rígido de decisión. @taubes2010 lo expresa de forma directa: la elección del 5% como punto de corte entre lo significativo y lo que no lo es resulta bastante arbitraria, pero así funciona la convención establecida.
::: {.callout-caution}
## Sobre la "significancia estadística"
Un resultado puede ser **estadísticamente significativo** (p < 0.05) pero **prácticamente irrelevante**. Con muestras suficientemente grandes, cualquier desviación mínima del supuesto producirá un p-value pequeño. Por esta razón, en diagnóstico de regresión **el juicio visual importa tanto o más que el test formal**.
@benjamin2018 propusieron redefinir la significancia estadística a $\alpha = 0.005$ para resultados "nuevos", argumentando que el umbral de 0.05 produce demasiados falsos positivos. Esta propuesta, aunque no adoptada universalmente, refuerza la idea de que los umbrales fijos son herramientas imperfectas.
:::
**Referencias:** @fisher1925; @taubes2010; @benjamin2018.
### Errores Tipo I y Tipo II
Al tomar una decisión basada en un test, podemos equivocarnos de dos formas:
| | $H_0$ es verdadera | $H_0$ es falsa |
|---|---|---|
| **No rechazar $H_0$** | Decisión correcta | Error Tipo II ($\beta$) |
| **Rechazar $H_0$** | Error Tipo I ($\alpha$) | Decisión correcta |
- **Error Tipo I (falso positivo):** Concluir que un supuesto se viola cuando en realidad se cumple. La probabilidad de este error es exactamente $\alpha$.
- **Error Tipo II (falso negativo):** No detectar una violación que sí existe. La probabilidad de este error es $\beta$, y depende del tamaño muestral y de la magnitud de la violación.
**Ejemplo concreto en diagnóstico OLS:** Si corremos un test de Breusch-Pagan con $\alpha = 0.05$ y este rechaza $H_0$ (homocedasticidad), pueden pasar dos cosas: (1) efectivamente hay heterocedasticidad (decisión correcta), o (2) los errores sí son homocedásticos pero tuvimos "mala suerte" con la muestra — esto es un Error Tipo I, y ocurre el 5% de las veces. A la inversa, si el test *no* rechaza, puede ser que realmente hay homocedasticidad, o que hay heterocedasticidad pero el test no fue capaz de detectarla (Error Tipo II).
La **potencia** de un test es $1 - \beta$: la capacidad de detectar una violación real. Un test con alta potencia detecta violaciones incluso pequeñas. Paradójicamente, esto puede ser un problema: con $n$ grande, los tests se vuelven tan potentes que detectan desviaciones mínimas que no tienen consecuencias prácticas.
::: {.callout-note}
## Implicación para el diagnóstico OLS
Esta es la razón fundamental por la que este documento insiste en complementar tests con gráficos. Los tests controlan el Error Tipo I (su $\alpha$ lo fija el investigador), pero con muestras grandes su potencia es tan alta que casi siempre rechazan. El gráfico permite evaluar si la desviación detectada es *prácticamente relevante*.
@cohen1988 propuso que además del p-value se reporte siempre el **tamaño del efecto**, una medida de la magnitud práctica de la desviación. Esta recomendación aplica directamente al diagnóstico de regresión: no basta saber que el test rechaza; hay que evaluar *cuánto* se desvía del supuesto.
:::
**Referencias:** @cohen1988; @neyman1933.
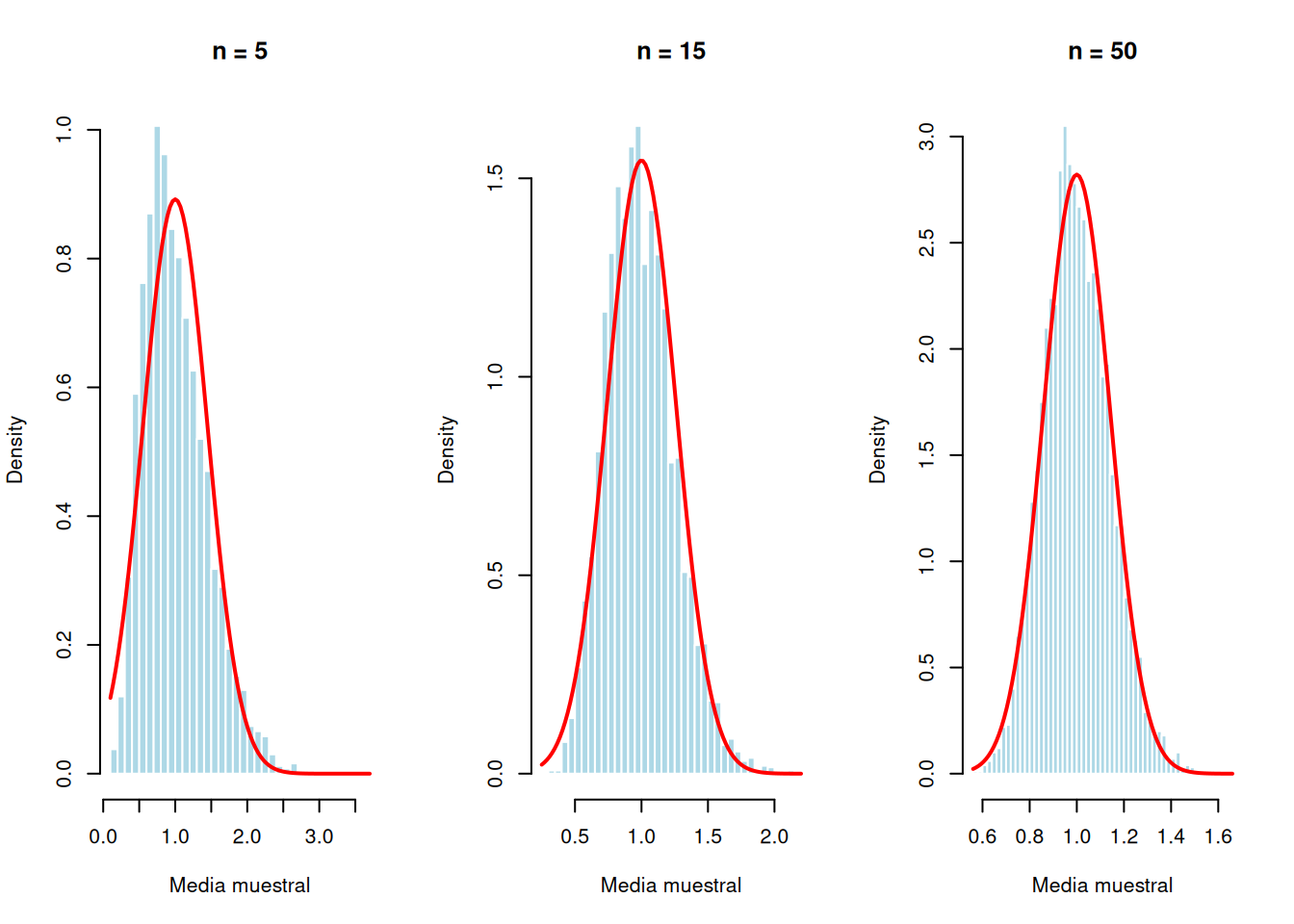
### El Teorema Central del Límite y su rol en OLS {#sec-tcl}
El **Teorema Central del Límite** (TCL) es quizás el resultado más importante de la estadística y tiene implicaciones directas sobre cómo interpretamos los supuestos de OLS.
La idea intuitiva del TCL es poderosa: **si promedias muchas cosas, el resultado tiende a ser normal** — sin importar cómo se distribuyan las cosas individuales. Es como si al mezclar muchos ingredientes distintos, el promedio siempre convergiera a la misma forma predecible.
Formalmente, el TCL establece que, dada una secuencia de variables aleatorias independientes $X_1, X_2, \ldots, X_n$ con media $\mu$ y varianza finita $\sigma^2$, la distribución de la media muestral se aproxima a una distribución normal conforme $n$ crece:
$$\frac{\bar{X}_n - \mu}{\sigma / \sqrt{n}} \xrightarrow{d} N(0, 1) \quad \text{cuando } n \to \infty$$
Este resultado es notable porque **no requiere que las $X_i$ individuales sean normales**. Pueden seguir cualquier distribución con varianza finita, y aun así la media muestral convergerá a una normal.
**¿Qué tiene que ver esto con regresión?** Los estimadores OLS $\hat{\beta}$ son combinaciones lineales de las observaciones de $Y$, y por tanto de los errores $\varepsilon_i$. Dicho de forma simple: cada coeficiente $\hat{\beta}$ es un "promedio ponderado" de muchos datos, y el TCL nos dice que los promedios tienden a ser normales aunque los datos individuales no lo sean. Por eso, incluso si los errores no son normales, los $\hat{\beta}$ serán *aproximadamente* normales con $n$ suficientemente grande. Esto significa que:
- Los tests $t$ y $F$ siguen siendo **aproximadamente válidos** con muestras grandes, aunque los errores no sean normales.
- Los intervalos de confianza para los $\hat{\beta}$ mantienen una cobertura aproximadamente correcta.
- La normalidad de los errores es **más crítica** para: muestras pequeñas ($n < 30$), intervalos de predicción (que dependen directamente de la distribución de $\varepsilon$), y tests exactos (no asintóticos).
```{r}
#| label: fig-tcl-demo
#| fig-cap: "Demostración del TCL: medias de muestras de tamaño 5, 15 y 50 extraídas de una distribución exponencial (muy asimétrica). Con n = 50, la distribución de medias ya es aproximadamente normal."
#| code-fold: true
#| code-summary: "Ver código de la simulación"
set.seed(42)
n_sim <- 5000
medias_5 <- replicate(n_sim, mean(rexp(5, rate = 1)))
medias_15 <- replicate(n_sim, mean(rexp(15, rate = 1)))
medias_50 <- replicate(n_sim, mean(rexp(50, rate = 1)))
par(mfrow = c(1, 3))
hist(
medias_5,
breaks = 40,
freq = FALSE,
main = "n = 5",
xlab = "Media muestral",
col = "lightblue",
border = "white"
)
curve(dnorm(x, mean = 1, sd = 1 / sqrt(5)), add = TRUE, col = "red", lwd = 2)
hist(
medias_15,
breaks = 40,
freq = FALSE,
main = "n = 15",
xlab = "Media muestral",
col = "lightblue",
border = "white"
)
curve(dnorm(x, mean = 1, sd = 1 / sqrt(15)), add = TRUE, col = "red", lwd = 2)
hist(
medias_50,
breaks = 40,
freq = FALSE,
main = "n = 50",
xlab = "Media muestral",
col = "lightblue",
border = "white"
)
curve(dnorm(x, mean = 1, sd = 1 / sqrt(50)), add = TRUE, col = "red", lwd = 2)
par(mfrow = c(1, 1))
```
::: {.callout-tip}
## Regla práctica
- Con $n \geq 30$, la aproximación normal suele ser razonable para distribuciones unimodales.
- Con distribuciones muy asimétricas o con colas pesadas, puede requerirse $n \geq 50$ o más.
- El TCL **no** aplica si la varianza de los errores es infinita (distribuciones de colas extremadamente pesadas como la Cauchy).
:::
**Referencias:** @taubes2010 [Cap. 13]; @wasserman2004 [Cap. 5]; @lumley2002.
## Paquetes necesarios
::: {.callout-note}
## Entorno de desarrollo
Este documento fue desarrollado y probado en **WSL2 con Ubuntu 24.04**, usando **Positron** como IDE y **R** gestionado vía `rig`. Si estás en Windows, se recomienda ejecutar R dentro de WSL para evitar problemas de compatibilidad con paquetes que dependen de librerías del sistema.
:::
Si no tienes los paquetes instalados, puedes hacerlo con [`pak`](https://pak.r-lib.org/) (recomendado) o con `install.packages()`:
```{r}
#| label: instalacion
#| eval: false
# Opción 1: Con pak (recomendado)
# pak resuelve dependencias de forma más rápida y robusta que install.packages()
# Instalar pak si no lo tienes: install.packages("pak")
pak::pak(c("lmtest", "car", "nortest", "tseries", "sandwich", "ISLR2"))
# Opcional: para diagnóstico avanzado de multicolinealidad (colldiag)
# pak::pak("perturb")
# Opción 2: Con install.packages()
install.packages(c("lmtest", "car", "nortest", "tseries", "sandwich", "ISLR2"))
```
```{r}
#| label: setup
#| message: false
#| warning: false
library(lmtest) # Breusch-Pagan, Breusch-Godfrey, Durbin-Watson, RESET
library(car) # VIF, ncvTest, crPlots
library(nortest) # Lilliefors, Anderson-Darling
library(tseries) # Jarque-Bera
library(sandwich) # Errores robustos (HC)
library(ISLR2) # Dataset Auto (n = 392)
```
## Datos y modelo de ejemplo
Usamos el dataset `Auto` del paquete `ISLR2` ($n = 392$ autos), que contiene información sobre rendimiento, peso, año de fabricación y origen de vehículos producidos entre 1970 y 1982. Este tamaño muestral es adecuado tanto para tests exactos como asintóticos.
**Modelo:** $\text{mpg} = \beta_0 + \beta_1 \cdot \text{weight} + \beta_2 \cdot \text{year} + \beta_3 \cdot \text{origin} + \varepsilon$
```{r}
#| label: modelo
datos <- Auto
modelo <- lm(mpg ~ weight + year + origin, data = datos)
summary(modelo)
```
## Orden recomendado de diagnóstico {#sec-orden}
El diagnóstico de supuestos no es una checklist que se recorre en cualquier orden. Algunos problemas pueden enmascarar o amplificar otros, por lo que el orden importa:
1. **Linealidad** — Si la forma funcional es incorrecta, todos los demás diagnósticos se basan en residuos distorsionados.
2. **Outliers / leverage / influencia** — Un punto influyente puede distorsionar los residuos y hacer que otros tests (BP, Shapiro-Wilk) den resultados engañosos.
3. **Homocedasticidad** — Una vez confirmada la forma funcional y descartados puntos influyentes.
4. **Independencia** — Relevante si los datos tienen estructura temporal, espacial o de cluster.
5. **Multicolinealidad** — Afecta la interpretación de coeficientes individuales, no la validez global del modelo.
6. **Normalidad** — Al final, porque es el supuesto menos crítico con $n$ grande (TCL).
Nótese que la **endogeneidad** — la violación más grave (ver @sec-por-que) — no aparece en esta lista porque **no tiene un test de diagnóstico estándar** basado en residuos. Su detección requiere razonamiento teórico sobre el proceso generador de datos: ¿hay variables omitidas correlacionadas con los predictores? ¿Existe simultaneidad? Si la respuesta es sí, ningún diagnóstico de residuos lo revelará [@wooldridge2020, Cap. 3].
::: {.callout-tip}
## ¿Por qué este orden?
Los problemas de las primeras etapas pueden enmascarar los de las siguientes. Por ejemplo, un outlier puede crear heterocedasticidad aparente, o una forma funcional incorrecta puede producir residuos no normales. Diagnosticar de arriba hacia abajo evita perseguir problemas que son síntomas de otro más fundamental.
:::
## Linealidad {#sec-linealidad}
**Supuesto:** La relación entre $Y$ y los predictores es **lineal en los parámetros**.
Esto significa que $Y = X\beta + \varepsilon$, donde $\beta$ aparece linealmente. Modelos como $Y = \beta_0 + \beta_1 \log(X) + \varepsilon$ o $Y = \beta_0 + \beta_1 X + \beta_2 X^2 + \varepsilon$ **sí son lineales** (en $\beta$), aunque la relación con $X$ no lo sea. Lo que viola linealidad es, por ejemplo, $Y = \beta_0 \cdot e^{\beta_1 X} + \varepsilon$.
**Si se viola:** Los coeficientes estimados estarán sesgados y las predicciones serán incorrectas.
### Test RESET de Ramsey
$H_0$: El modelo está correctamente especificado (linealidad adecuada).
$H_1$: Existen términos no lineales omitidos.
**Idea intuitiva:** si el modelo lineal es correcto, los valores predichos elevados al cuadrado o al cubo no deberían aportar información adicional. El test agrega $\hat{Y}^2$ y $\hat{Y}^3$ como regresores auxiliares y verifica exactamente eso. Si son significativos, hay evidencia de no linealidad.
```{r}
#| label: reset-test
resettest(modelo, power = 2:3, type = "fitted")
```
::: {.callout-warning}
## Consideraciones
- Es un test **general**: detecta no linealidad pero no indica cuál variable es la problemática.
- Sensible al tamaño muestral: con $n$ grande, puede rechazar por desviaciones triviales.
:::
**Referencia:** @ramsey1969.
### Residuos vs Valores Ajustados
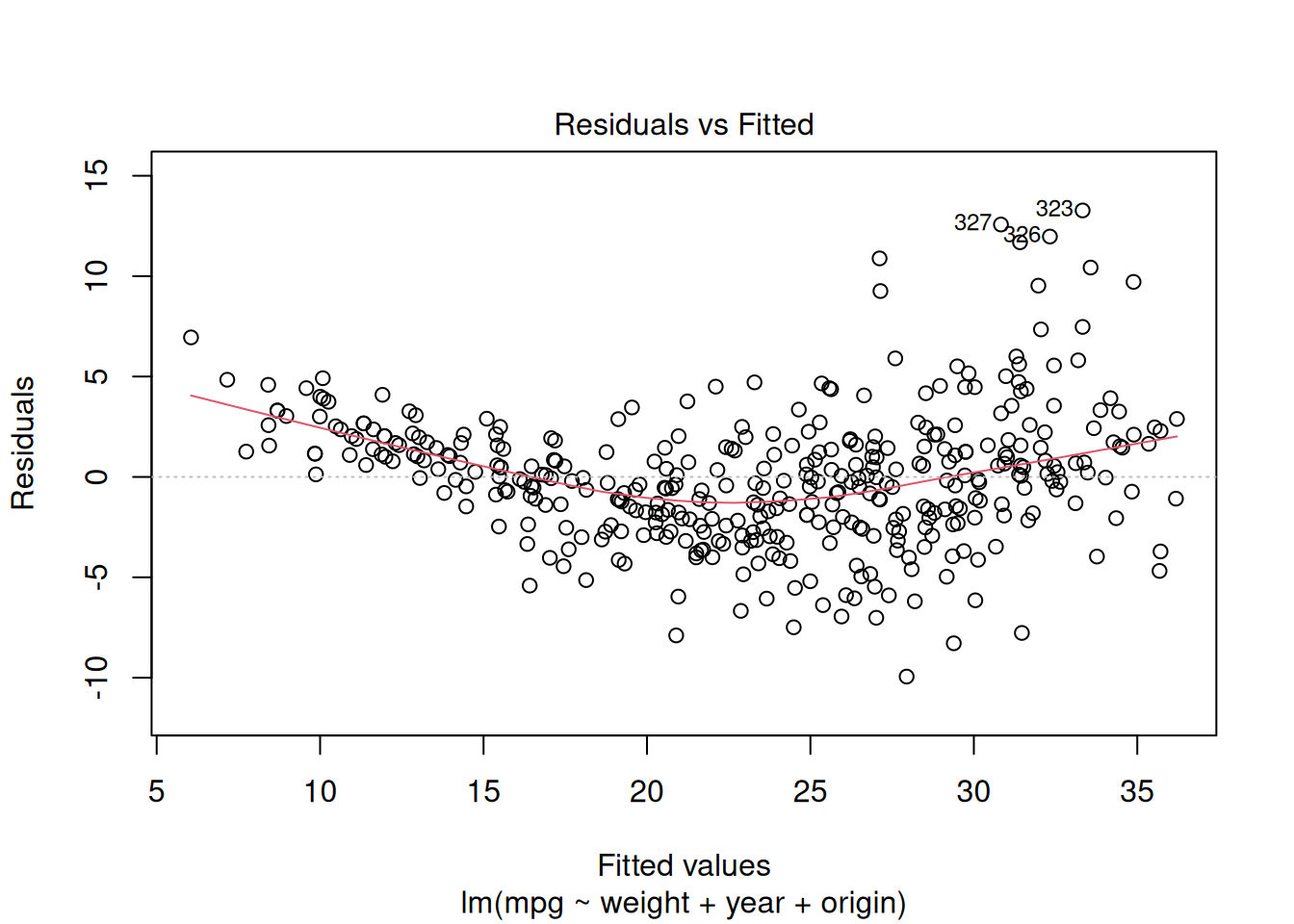
El patrón ideal es una banda horizontal aleatoria alrededor de 0. Curvatura (forma de U o parábola) indica no linealidad.
```{r}
#| label: fig-residuos-ajustados
#| fig-cap: "Si la línea roja (loess) se desvía de la horizontal, hay indicios de no linealidad."
plot(modelo, which = 1)
```
### Component + Residual Plots (CR plots)
Más informativo que el gráfico anterior: muestra la relación parcial de **cada predictor** con $Y$, permitiendo identificar cuál variable tiene un efecto no lineal.
```{r}
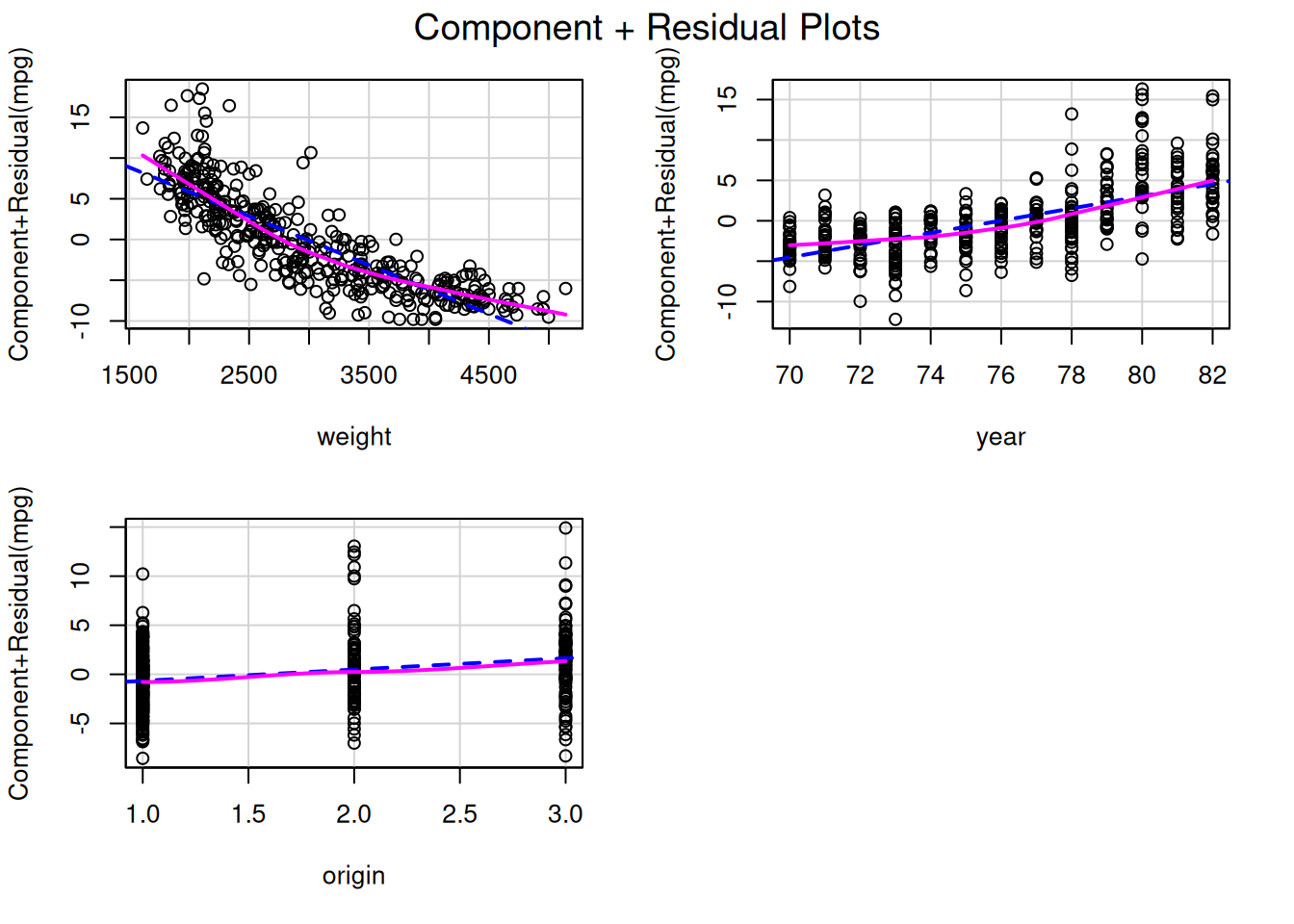
#| label: fig-crplots
#| fig-cap: "La línea rosa (componente) debería coincidir con la línea azul discontinua (ajuste lineal). Desviaciones indican no linealidad en esa variable."
crPlots(modelo)
```
**Referencia:** @cook1982.
## Normalidad de residuos {#sec-normalidad}
**Supuesto:** $\varepsilon \sim N(0, \sigma^2)$.
::: {.callout-important}
## ¿Cuándo importa realmente?
Como se explica en la @sec-tcl, por el **Teorema Central del Límite** los estimadores OLS son aproximadamente normales con $n$ suficientemente grande, **incluso si los errores no lo son**. Esto significa que:
- Con $n \geq 30$, los tests $t$ y $F$ sobre los coeficientes mantienen validez aproximada.
- La normalidad es **crítica** en muestras pequeñas, para intervalos de predicción, y cuando se usan tests exactos (no asintóticos).
- Errores con colas pesadas o asimetría extrema pueden requerir $n$ mucho mayor para que la aproximación funcione [@lumley2002].
En la práctica, esto implica que si su muestra es grande, un rechazo en Shapiro-Wilk no necesariamente invalida su análisis. Lo que importa es *cuánto* se desvía la distribución de la normal, y eso se evalúa visualmente.
**Regla clave:** La normalidad importa más para **intervalos de predicción** (predecir $y_{nuevo}$) que para **intervalos de confianza** de los coeficientes (estimar $\beta$). Si su objetivo es solo estimar efectos, el TCL le cubre con $n$ grande. Si necesita predecir observaciones individuales, la normalidad sí es crítica porque el intervalo de predicción depende directamente de la distribución de $\varepsilon$.
:::
```{r}
#| label: residuos
residuos <- resid(modelo)
```
### Shapiro-Wilk
Considerado el test más potente para muestras pequeñas y medianas.
```{r}
#| label: shapiro
shapiro.test(residuos)
```
| Aspecto | Detalle |
|---|---|
| Rango válido | $n$ entre 3 y 5000 (en R; con $n > 5000$ usar QQ-plot) |
| Fortaleza | Mayor potencia que KS y Lilliefors |
| Limitación | Con $n > 100$, detecta desviaciones mínimas que pueden ser irrelevantes |
| Recomendación | Usar como complemento visual, no como veredicto único |
**Referencia:** @shapiro1965.
### Lilliefors (KS corregido)
```{r}
#| label: lilliefors
lillie.test(residuos)
```
::: {.callout-caution}
## Sobre `ks.test()` de base R
`ks.test(resid, "pnorm")` compara contra una normal con parámetros **fijos**. Sin especificar media y desviación estándar, compara contra $N(0, 1)$, lo cual es **incorrecto** si los residuos no están estandarizados.
`lillie.test()` del paquete `nortest` **corrige esto**: estima $\mu$ y $\sigma$ internamente antes de comparar (corrección de Lilliefors).
Si insistes en usar `ks.test()`:
```r
ks.test(residuos, "pnorm", mean = mean(residuos), sd = sd(residuos))
```
Pero esto es **anticonservador** — es decir, produce p-values más altos de lo que deberían ser, haciendo que el test rechace *menos* de lo que corresponde y nos dé una falsa sensación de normalidad.
:::
**Referencia:** @lilliefors1967.
### Jarque-Bera
Basado en asimetría (*skewness*) y curtosis (*kurtosis*). En términos simples: mide si la distribución de los residuos es simétrica (skewness $\approx 0$) y si tiene la "forma de campana" adecuada (kurtosis $\approx 3$). Si alguna de estas dos propiedades falla, el test rechaza normalidad.
```{r}
#| label: jarque-bera
jarque.bera.test(residuos)
```
| Aspecto | Detalle |
|---|---|
| Base teórica | Asintótico: estadístico $\chi^2$ con 2 g.l. |
| Requisito | $n \geq 30$ para ser confiable |
| Normalidad implica | Skewness $\approx 0$ y kurtosis $\approx 3$ |
| Limitación | No recomendado para muestras pequeñas |
::: {.callout-tip}
## Nota sobre el tamaño muestral
Con $n = `r nrow(datos)`$, los tests asintóticos como Jarque-Bera tienen **potencia adecuada**. En muestras más pequeñas ($n < 50$), Shapiro-Wilk es preferible por su mayor potencia en muestras finitas (ver tabla comparativa más adelante).
:::
**Referencia:** @jarque1987.
### Anderson-Darling
Similar a Kolmogorov-Smirnov pero da **más peso a las colas** de la distribución — es decir, es especialmente bueno para detectar si hay valores extremos más frecuentes de lo que una distribución normal permitiría. Más potente que KS/Lilliefors para detectar desviaciones en colas pesadas.
```{r}
#| label: anderson-darling
ad.test(residuos)
```
**Referencia:** @anderson1952.
### Comparación de potencia entre tests
@razali2011 compararon la potencia de estos tests:
| Test | Muestras pequeñas | Muestras medianas | Muestras grandes |
|---|:---:|:---:|:---:|
| Shapiro-Wilk | ★★★ | ★★★ | ★★ |
| Anderson-Darling | ★★ | ★★ | ★★★ |
| Lilliefors | ★★ | ★★ | ★★ |
| Jarque-Bera | ★ | ★★ | ★★★ |
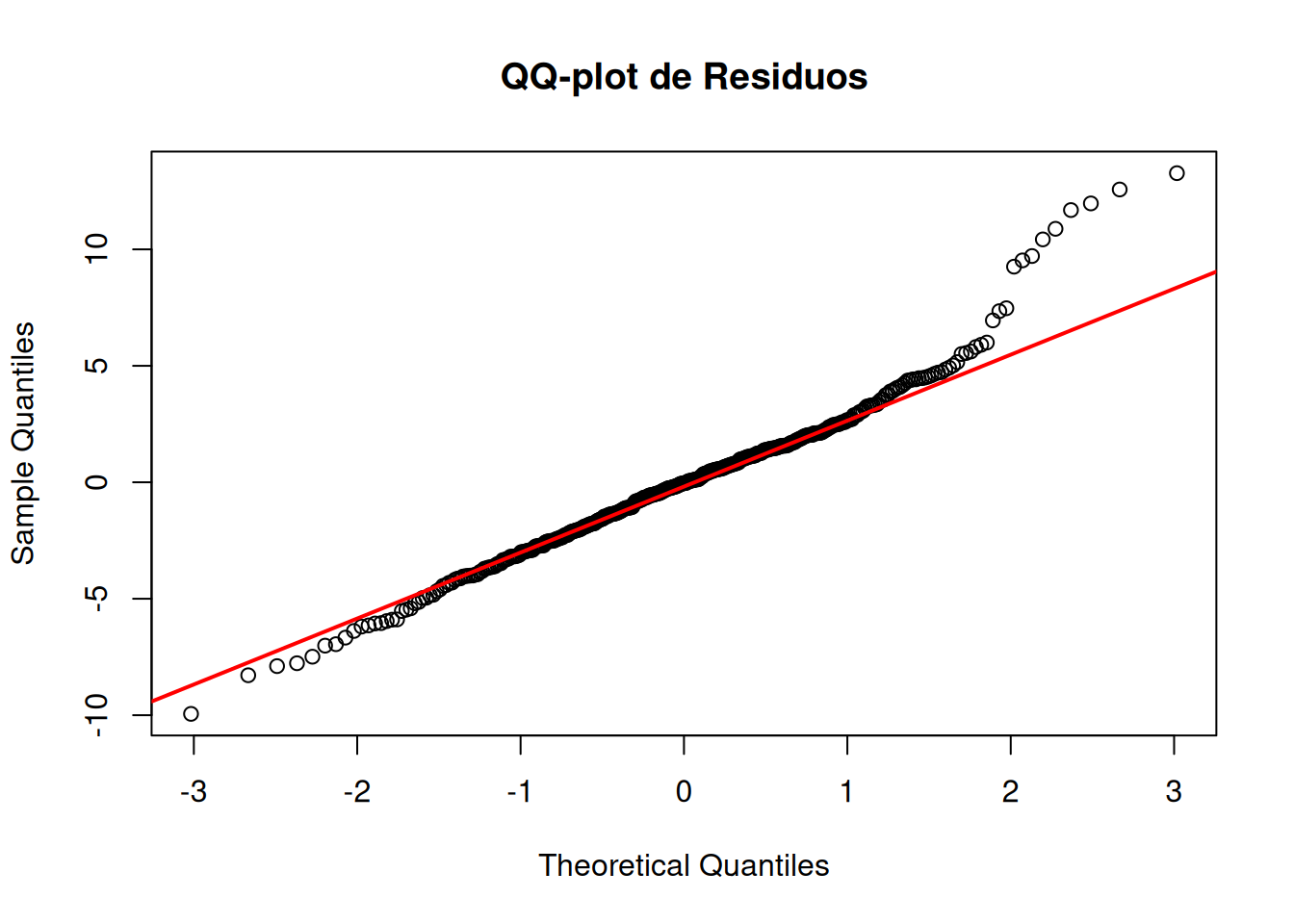
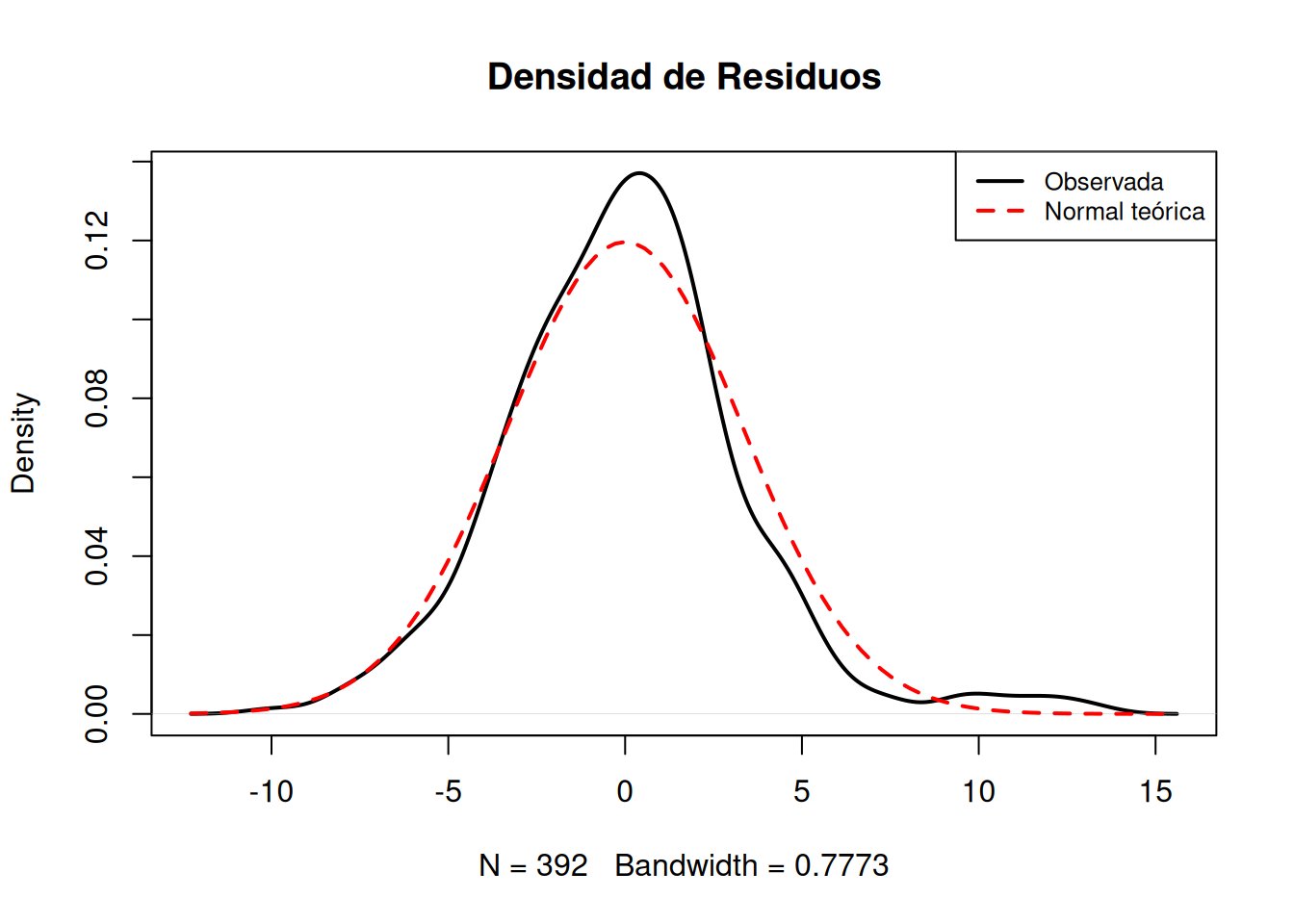
### Diagnóstico visual: QQ-plot y densidad
::: {.callout-tip}
## El QQ-plot es el gráfico más importante
*"En la práctica, la inspección visual de un QQ-plot es más informativa que cualquier test formal, especialmente con muestras grandes."* — @faraway2015
:::
```{r}
#| label: fig-normalidad
#| fig-cap: "Izquierda: QQ-plot (puntos sobre la línea = normalidad). Derecha: Densidad observada vs teórica."
#| layout-ncol: 2
# QQ-plot
qqnorm(residuos, main = "QQ-plot de Residuos")
qqline(residuos, col = "red", lwd = 2)
# Densidad
plot(density(residuos), main = "Densidad de Residuos", lwd = 2)
curve(
dnorm(x, mean = mean(residuos), sd = sd(residuos)),
add = TRUE,
col = "red",
lwd = 2,
lty = 2
)
legend(
"topright",
c("Observada", "Normal teórica"),
col = c("black", "red"),
lty = c(1, 2),
lwd = 2,
cex = 0.8
)
```
**¿Cómo leer un QQ-plot?** La idea es simple: si los residuos fueran perfectamente normales, todos los puntos caerían exactamente sobre la línea roja diagonal. Las desviaciones de la línea nos dicen *cómo* difiere la distribución de la normal.
| Patrón observado | Interpretación | En simple |
|---|---|---|
| Puntos sobre la línea | Normalidad | Todo bien |
| Curva en forma de S | Colas pesadas (leptocurtosis) | Hay más valores extremos de lo esperado |
| Curva en S invertida | Colas livianas (platicurtosis) | Los datos son "demasiado concentrados" en el centro |
| Desviación sistemática hacia arriba | Asimetría positiva | Hay una cola larga hacia valores altos |
| Desviación sistemática hacia abajo | Asimetría negativa | Hay una cola larga hacia valores bajos |
## Homocedasticidad {#sec-homocedasticidad}
**Supuesto:** $\text{Var}(\varepsilon_i) = \sigma^2$ constante para todo $i$.
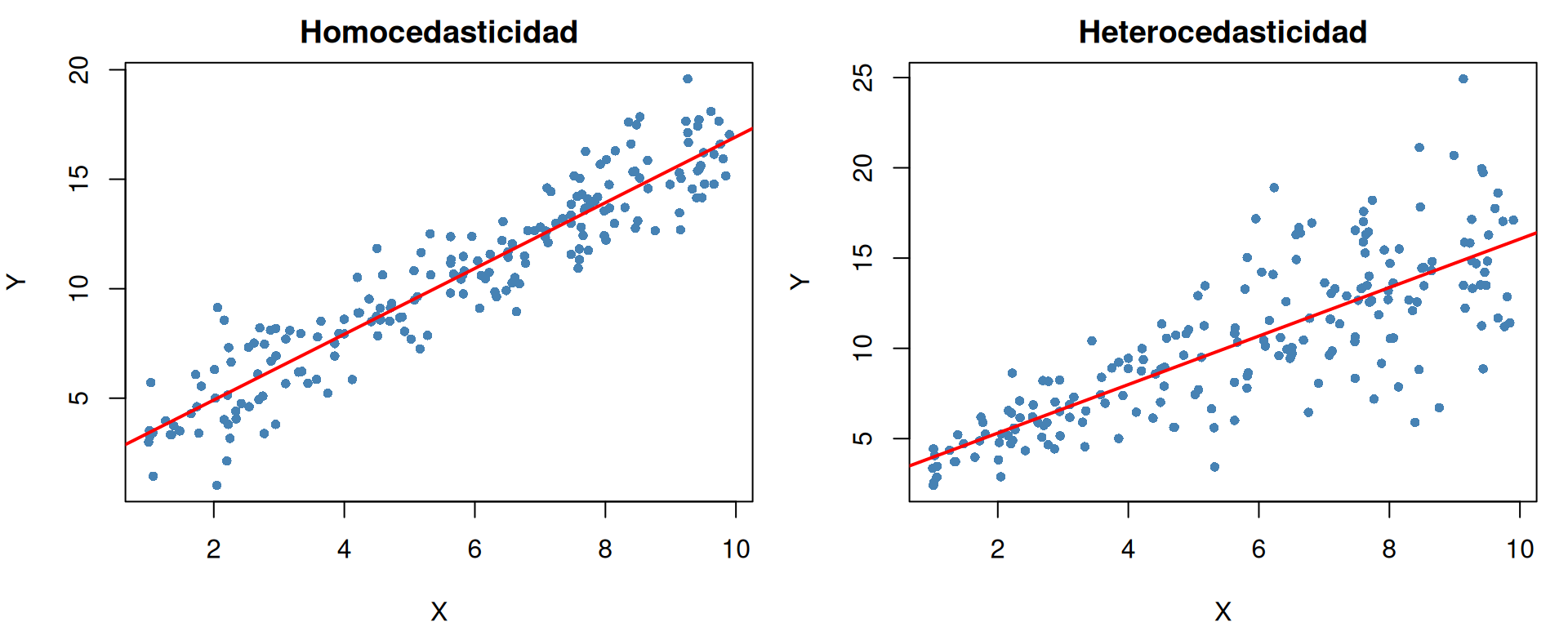
**En palabras simples:** la "dispersión" o "ruido" alrededor de la recta de regresión debe ser parejo en todo el rango de datos. Si el modelo predice bien los valores bajos pero "se desparrama" en los valores altos (o viceversa), hay heterocedasticidad.
**Si se viola (heterocedasticidad):** Los errores estándar OLS son incorrectos, lo que invalida tests $t$, $F$ e intervalos de confianza. OLS sigue siendo insesgado, pero ya no es eficiente (no es BLUE).
**¿Por qué ocurre en la práctica?** La heterocedasticidad es ubicua en datos reales. Ejemplos comunes: la variabilidad del gasto crece con el ingreso (los hogares ricos tienen más opciones de consumo), los errores de medición son proporcionales a la magnitud medida, o la dispersión de precios de vivienda aumenta en barrios de mayor valor. Como regla general, cuando la respuesta $Y$ es estrictamente positiva y varía en órdenes de magnitud, es probable que haya heterocedasticidad.
```{r}
#| label: fig-concepto-heterocedasticidad
#| fig-cap: "Izquierda: varianza constante (homocedasticidad). Derecha: varianza creciente (heterocedasticidad, forma de embudo)."
#| fig-width: 10
#| fig-height: 4
set.seed(42)
n_sim <- 200
x_sim <- runif(n_sim, 1, 10)
par(mfrow = c(1, 2), mar = c(4, 4, 2, 1))
# Homocedasticidad
y_homo <- 2 + 1.5 * x_sim + rnorm(n_sim, sd = 1.5)
plot(
x_sim,
y_homo,
pch = 16,
col = "steelblue",
cex = 0.8,
xlab = "X",
ylab = "Y",
main = "Homocedasticidad"
)
abline(lm(y_homo ~ x_sim), col = "red", lwd = 2)
# Heterocedasticidad
y_hetero <- 2 + 1.5 * x_sim + rnorm(n_sim, sd = 0.5 * x_sim)
plot(
x_sim,
y_hetero,
pch = 16,
col = "steelblue",
cex = 0.8,
xlab = "X",
ylab = "Y",
main = "Heterocedasticidad"
)
abline(lm(y_hetero ~ x_sim), col = "red", lwd = 2)
par(mfrow = c(1, 1))
```
### Breusch-Pagan (versión studentized / Koenker)
$H_0$: Los errores son homocedásticos.
$H_1$: La varianza de los errores depende de los predictores.
```{r}
#| label: breusch-pagan
bptest(modelo)
```
::: {.callout-note}
`lmtest::bptest()` usa por defecto la versión *studentized* [@koenker1981], que es más robusta ante no normalidad de los errores que la versión original de @breusch1979.
:::
### Score Test (ncvTest)
Similar a Breusch-Pagan. Permite especificar contra qué variable testear la heterocedasticidad.
```{r}
#| label: ncvtest
ncvTest(modelo)
```
### Test de White
Más general que Breusch-Pagan: incluye términos cuadráticos y cruzados, por lo que detecta formas **no lineales** de heterocedasticidad.
```{r}
#| label: white-test
white_data <- data.frame(yhat = fitted(modelo))
bptest(modelo, ~ yhat + I(yhat^2), data = white_data)
```
**Referencia:** @white1980.
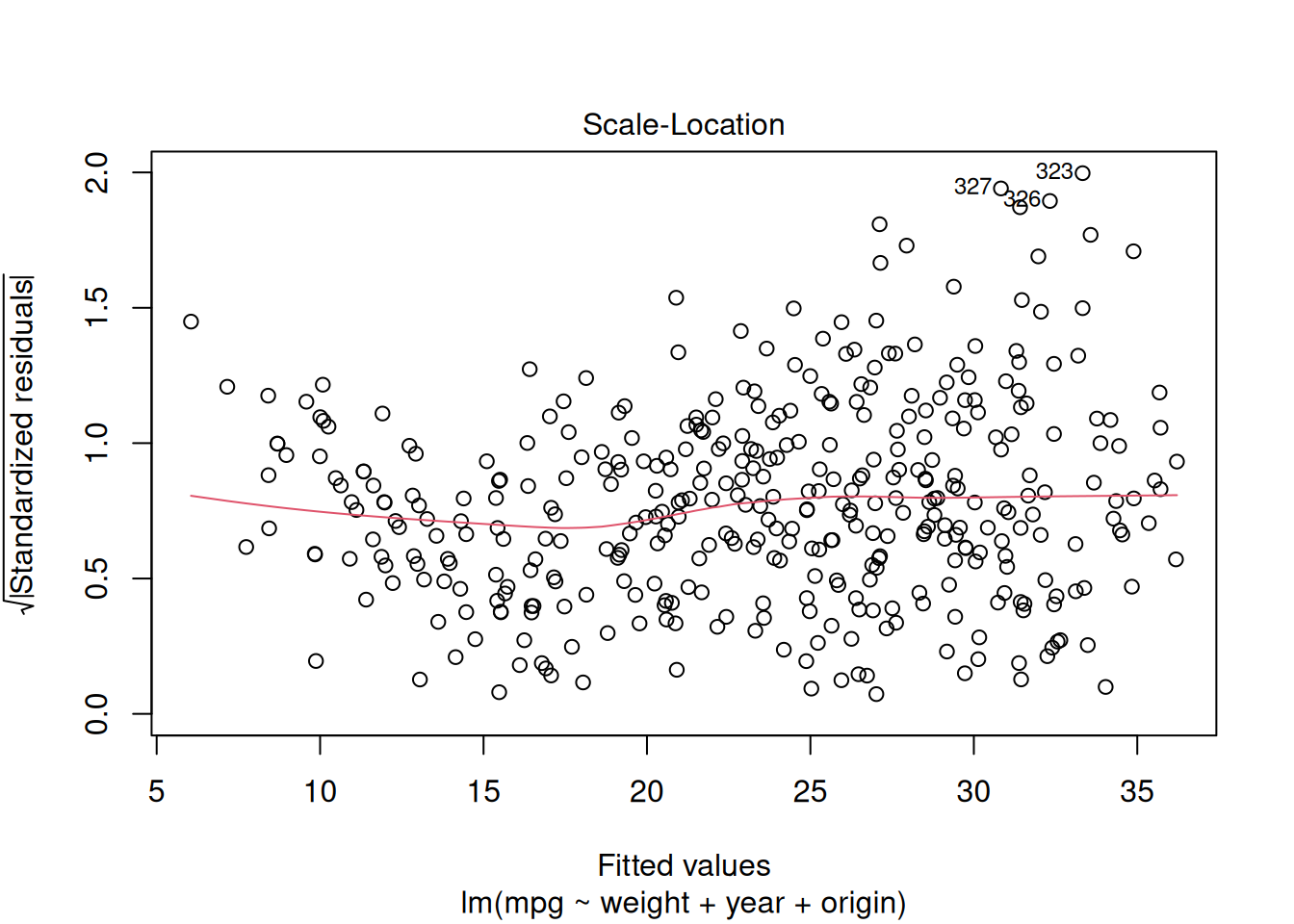
### Scale-Location plot
Muestra $\sqrt{|\text{residuos estandarizados}|}$ vs valores ajustados. Patrón ideal: banda horizontal.
```{r}
#| label: fig-scale-location
#| fig-cap: "Si la línea roja sube hacia la derecha, hay evidencia de heterocedasticidad."
plot(modelo, which = 3)
```
### Solución: Errores estándar robustos (HC)
Si hay heterocedasticidad, no es necesario abandonar OLS. Se pueden usar **errores estándar robustos**, que recalculan la incertidumbre de los coeficientes teniendo en cuenta que la varianza no es constante. Los coeficientes $\hat{\beta}$ no cambian — lo que cambia son los errores estándar, los p-values y los intervalos de confianza:
```{r}
#| label: errores-robustos
coeftest(modelo, vcov = vcovHC(modelo, type = "HC3"))
```
| Variante | Descripción | Recomendación |
|---|---|---|
| HC0 | @white1980, el clásico | Puede subestimar con $n$ pequeño |
| HC1 | Corrección por g.l.: $n/(n-k)$ | Mejora marginal sobre HC0 |
| HC2 | Usa leverage ($h_{ii}$) | Mejor para diseños desbalanceados |
| **HC3** | **Más conservador** | **Recomendado para muestras pequeñas** |
| HC4 | MacKinnon & White | Más robusto con puntos influyentes |
**Referencias:** @zeileis2004; @long2000.
## Independencia de residuos {#sec-independencia}
**Supuesto:** $\text{Cov}(\varepsilon_i, \varepsilon_j) = 0$ para todo $i \neq j$.
**En palabras simples:** el error de una observación no debe estar relacionado con el error de otra. Si el modelo sobreestima un dato, eso no debería darnos información sobre si sobreestimará o subestimará el siguiente. Cuando los datos están ordenados en el tiempo, esto puede fallar: si hoy el modelo sobreestima, es probable que mañana también lo haga (los errores se "arrastran").
**Si se viola:** Subestima errores estándar y produce inferencias demasiado optimistas.
::: {.callout-important}
## Dato clave
En datos de **corte transversal** con muestreo aleatorio, la independencia se garantiza por **diseño muestral**, no por un test. Los tests de autocorrelación son relevantes cuando los datos tienen ordenamiento temporal, estructura espacial o de cluster.
**Salvedad importante:** Esto asume observaciones i.i.d. (independientes e idénticamente distribuidas). En la práctica, muchos cortes transversales presentan **estructuras jerárquicas** (estudiantes dentro de escuelas, pacientes dentro de hospitales) o **espaciales** (encuestados en la misma región). En estos casos, los errores dentro de un mismo grupo están correlacionados, violando la independencia. La solución estándar es usar **errores estándar agrupados** (*clustered standard errors*) con `vcovCL()` del paquete `sandwich`.
:::
### Durbin-Watson
$H_0$: No hay autocorrelación de orden 1.
```{r}
#| label: durbin-watson
dwtest(modelo)
```
| Valor DW | Interpretación |
|:---:|---|
| $\approx 2$ | Sin autocorrelación |
| $< 2$ | Autocorrelación positiva |
| $> 2$ | Autocorrelación negativa |
::: {.callout-warning}
## Limitaciones de Durbin-Watson
- Solo detecta autocorrelación de **orden 1** (AR(1)).
- Requiere que los datos estén **ordenados temporalmente**.
- **No válido** si hay variable dependiente rezagada como regresor.
- En esos casos, usar Breusch-Godfrey.
:::
**Referencia:** @durbin1950.
### Breusch-Godfrey (LM test)
Más general que DW: puede testear autocorrelación de **orden $p > 1$** y es válido incluso con variables dependientes rezagadas. Se recomienda sobre Durbin-Watson en la mayoría de los casos.
```{r}
#| label: breusch-godfrey
bgtest(modelo, order = 1)
bgtest(modelo, order = 2)
bgtest(modelo, order = 4) # útil para datos trimestrales
```
**Referencias:** @breusch1978; @godfrey1978.
::: {.callout-warning}
## Interpretación en el dataset Auto
El dataset `Auto` está ordenado por año de fabricación (1970–1982), un período con cambios estructurales importantes: regulaciones CAFE de eficiencia, crisis del petróleo de 1973 y 1979, y cambios tecnológicos en motores. El DW bajo (~1.27) y el BG significativo probablemente reflejan **tendencias temporales no modeladas**, no autocorrelación serial clásica.
Incluir `year` como predictor lineal captura la tendencia general, pero no los cambios discretos (un shock petrolero no es lineal). La "autocorrelación" detectada puede ser un síntoma de **variables omitidas con estructura temporal** — es decir, hay factores que cambian a lo largo del tiempo y que el modelo no incluye. Posibles soluciones serían variables dummy para períodos regulatorios o splines en `year`, aunque para los fines de este ejercicio basta con reconocer esta limitación.
:::
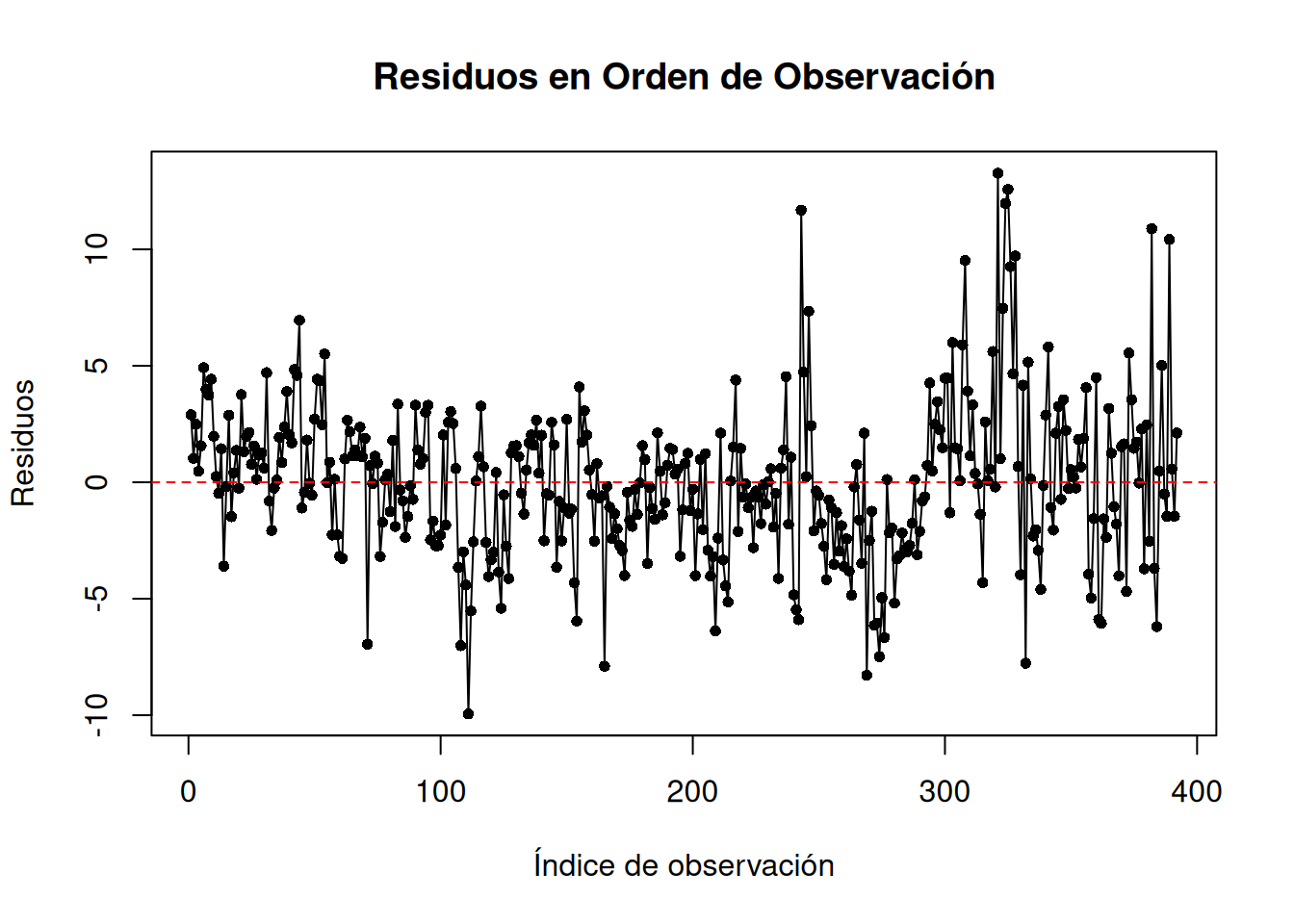
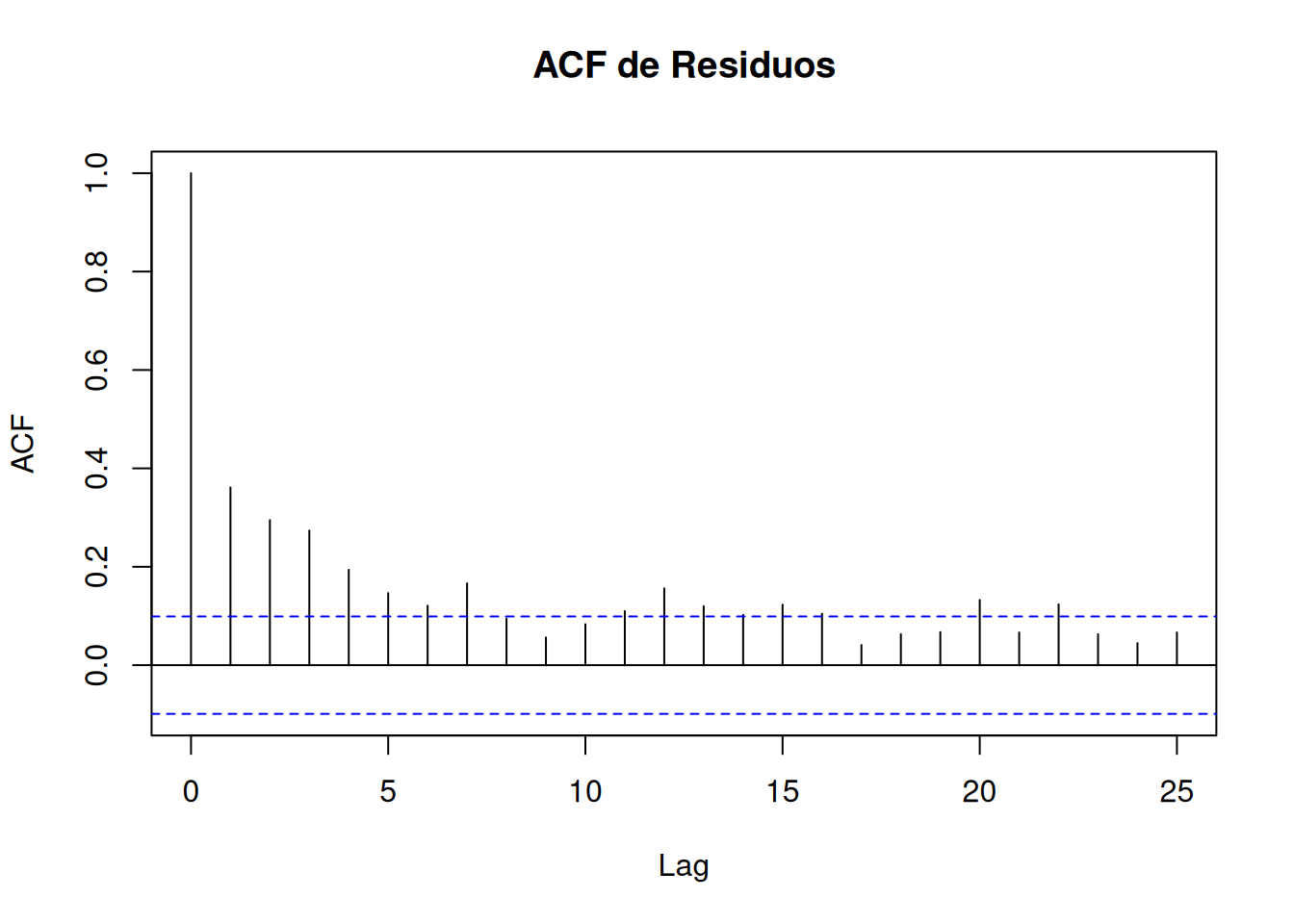
### Diagnóstico visual
```{r}
#| label: fig-independencia
#| fig-cap: "Izquierda: serie de residuos (no debería haber patrones). Derecha: ACF (barras dentro de las bandas azules = sin autocorrelación)."
#| layout-ncol: 2
# Residuos en secuencia
plot(
residuos,
type = "o",
pch = 16,
cex = 0.8,
main = "Residuos en Orden de Observación",
ylab = "Residuos",
xlab = "Índice de observación"
)
abline(h = 0, col = "red", lty = 2)
# ACF
acf(residuos, main = "ACF de Residuos")
```
## Multicolinealidad {#sec-multicolinealidad}
**Definición:** Los predictores están altamente correlacionados entre sí.
::: {.callout-note}
## ¿Es un supuesto de OLS?
Técnicamente, no. OLS solo requiere que no haya colinealidad **perfecta** (una variable no sea combinación lineal exacta de otras). Con multicolinealidad alta, OLS sigue siendo BLUE. Sin embargo, causa problemas prácticos severos: coeficientes con signos inesperados, errores estándar inflados y estimaciones inestables.
En resumen: **la multicolinealidad no es un problema del modelo, sino del objetivo analítico.** Si el objetivo es predicción, puede ser tolerable. Si es interpretar coeficientes individuales, requiere acción.
:::
### VIF (Variance Inflation Factor)
$$\text{VIF}_j = \frac{1}{1 - R^2_j}$$
donde $R^2_j$ es el $R^2$ de regresar $X_j$ contra todos los demás predictores. **En simple:** el VIF responde a la pregunta "¿cuánto se infla la incertidumbre de este coeficiente por culpa de la correlación con otros predictores?". Un VIF de 5 significa que el error estándar es $\sqrt{5} \approx 2.2$ veces más grande que si el predictor fuera independiente de los demás.
```{r}
#| label: vif
vif(modelo)
```
| VIF | Interpretación |
|:---:|---|
| 1 | Sin colinealidad |
| 1–5 | Moderada (generalmente aceptable) |
| 5–10 | Alta (revisar) |
| $> 10$ | Severa (acción recomendada) |
::: {.callout-caution}
@obrien2007 argumenta que **no hay un umbral universal** para el VIF. El impacto de la multicolinealidad depende del tamaño muestral, la magnitud de los efectos y el propósito del modelo.
:::
**Referencias:** @belsley1980; @obrien2007; @dormann2013.
### Matriz de correlaciones
La correlación de Pearson entre dos variables aleatorias $X$ y $Z$ se define como:
$$\rho_{XZ} = \frac{\text{Cov}(X, Z)}{\sigma_X \cdot \sigma_Z}$$
donde $\rho = 1$ indica relación lineal perfecta positiva, $\rho = -1$ negativa, y $\rho = 0$ ausencia de relación lineal. La **matriz de correlaciones** de los predictores organiza estos coeficientes en una estructura simétrica donde cada entrada $(i, j)$ es $\rho_{X_i X_j}$.
**Limitación importante:** La correlación de Pearson solo captura relaciones **bivariadas** (de a pares) y **lineales**. Puede haber multicolinealidad severa que involucre 3+ variables simultáneamente sin que ninguna correlación bivariada sea alta. **Ejemplo numérico:** suponga que $X_3 \approx 2X_1 - X_2$. La correlación entre $X_1$ y $X_2$ podría ser solo 0.4, y entre $X_1$ y $X_3$ quizás 0.5 — nada alarmante por separado. Pero $X_3$ es casi completamente predecible a partir de las otras dos, lo que dispararía el VIF. Moraleja: mirar solo la matriz de correlaciones puede dar una falsa sensación de seguridad.
```{r}
#| label: correlaciones
predictores <- datos[, c("weight", "year", "origin")]
round(cor(predictores), 3)
```
**Referencia:** @taubes2010 [Cap. 6.7].
### Condition Number (Índice de Condición)
El Condition Number aborda una limitación del VIF: este solo mide la colinealidad de cada predictor contra los demás de forma individual. Sin embargo, puede existir multicolinealidad que involucre tres o más variables simultáneamente sin que ningún VIF individual sea alarmante. El Condition Number detecta estas dependencias más complejas.
#### ¿Por qué eigenvalores?
**Intuición antes de la matemática:** Imagina que tienes tres predictores. Si cada uno aporta información "nueva" y diferente, el modelo puede separar claramente el efecto de cada uno — esto se refleja en eigenvalores todos grandes y similares. Pero si dos predictores dicen casi lo mismo (por ejemplo, peso en kilos y peso en libras), una de esas "direcciones de información" se colapsa — un eigenvalor se vuelve cercano a cero. El Condition Number mide precisamente esa disparidad: ¿cuánto difiere la dirección más informativa de la menos informativa?
Formalmente, la matriz $X'X$ (donde $X$ es la matriz de diseño) es central en OLS porque los coeficientes estimados son $\hat{\beta} = (X'X)^{-1}X'Y$. La estabilidad numérica de esta inversión depende de los **eigenvalores** (valores propios) de $X'X$.
Los eigenvalores $\lambda_1 \geq \lambda_2 \geq \ldots \geq \lambda_p$ de $X'X$ representan la cantidad de "información independiente" que aporta cada dirección del espacio de predictores. Si un eigenvalor es muy pequeño relativo a los demás, significa que existe una dirección en la que los predictores casi no varían de forma independiente — es decir, hay una combinación lineal de predictores que es casi constante. Esto es exactamente lo que ocurre cuando hay multicolinealidad.
El **Condition Number** cuantifica esta disparidad:
$$\kappa = \sqrt{\frac{\lambda_{\max}}{\lambda_{\min}}}$$
Cuando $\lambda_{\min} \to 0$ (algún predictor es casi combinación lineal de otros), $\kappa \to \infty$, lo que señala que la inversión de $X'X$ es numéricamente inestable y los coeficientes $\hat{\beta}$ pueden cambiar drásticamente ante pequeñas perturbaciones en los datos.
@belsley1980 propusieron además examinar la **descomposición de la proporción de varianza**: no solo mirar el Condition Number global, sino identificar cuáles pares de coeficientes comparten un eigenvalor pequeño, lo que permite localizar cuáles variables están involucradas en la colinealidad. Este diagnóstico más fino está disponible en R con `colldiag()` del paquete `perturb`.
```{r}
#| label: condition-number
X <- model.matrix(modelo)
valores_propios <- eigen(t(X) %*% X)$values
cat("Eigenvalores de X'X:\n")
print(round(valores_propios, 2))
cat(
"\nCondition Number:",
round(sqrt(max(valores_propios) / min(valores_propios)), 2),
"\n"
)
```
::: {.callout-warning}
## ¿Por qué el CN es tan alto si los VIF son bajos?
Si el CN resulta muy elevado (e.g., > 1000) pero todos los VIF son bajos (< 5), la explicación más probable **no es multicolinealidad real** sino un **artefacto de escala**. El cálculo del CN usa la matriz de diseño completa $X$, que incluye la columna de intercepto (todos 1s). Cuando un predictor opera en escala de miles (como `weight` ≈ 2000–5000) mientras el intercepto vale 1, la disparidad en magnitudes infla enormemente el ratio $\lambda_{\max}/\lambda_{\min}$ sin que exista dependencia lineal real entre predictores.
@belsley1980 [Cap. 3] recomienda **centrar y escalar** las columnas de $X$ (excluyendo el intercepto) antes de calcular el CN para obtener un diagnóstico limpio:
:::
```{r}
#| label: condition-number-scaled
# CN con matriz centrada y escalada (sin intercepto)
X_scaled <- scale(model.matrix(modelo)[, -1])
ev_scaled <- eigen(t(X_scaled) %*% X_scaled)$values
cat(
"CN (centrado/escalado):",
round(sqrt(max(ev_scaled) / min(ev_scaled)), 2),
"\n"
)
```
**Regla práctica:** cuando VIF < 5 y CN > 30, compare siempre con el CN escalado. Si el CN escalado cae dentro del rango aceptable, el problema es de escala, no de multicolinealidad.
| Condition Number | Interpretación |
|:---:|---|
| $< 10$ | Sin problemas |
| $10 - 30$ | Colinealidad moderada |
| $> 30$ | Colinealidad severa [@belsley1980] |
::: {.callout-note}
## Conexión con matrices simétricas
$X'X$ es una **matriz simétrica** (y semidefinida positiva), lo que garantiza que todos sus eigenvalores son reales y no negativos. Esta propiedad permite interpretarlos geométricamente como las longitudes de los ejes de la elipsoide de confianza de los coeficientes. **En términos más simples:** piense en la "nube de incertidumbre" sobre los coeficientes como un balón de rugby. Si la información de los predictores está bien distribuida, el balón es casi esférico (incertidumbre similar en todas las direcciones). Si hay colinealidad, el balón se estira mucho en una dirección — eso es el eigenvalor pequeño, indicando gran incertidumbre. @taubes2010 [Cap. 19] desarrolla esta conexión entre matrices simétricas, eigenvalores y análisis de datos.
:::
**Referencias:** @belsley1980 [Cap. 3]; @taubes2010 [Cap. 19].
## Outliers, leverage y observaciones influyentes {#sec-influencia}
Además de los cinco supuestos clásicos, ISLR2 [@james2023, Sec. 3.3.3] destaca tres problemas prácticos que pueden distorsionar severamente los resultados de una regresión: **outliers**, **puntos de alto leverage** y **observaciones influyentes**.
### Outliers y residuos studentizados
Un **outlier** es una observación cuyo valor de respuesta $y_i$ está lejos del valor predicho por el modelo. En términos simples: es un dato cuyo $Y$ "no encaja" con lo que el modelo espera. Aunque un solo outlier puede no afectar mucho los coeficientes, sí puede inflar el RSE y distorsionar $R^2$, intervalos de confianza y p-values.
Para identificar outliers se usan los **residuos studentizados** (externamente). La idea es sencilla: tomamos el error de predicción de cada dato y lo "estandarizamos" dividiéndolo por una estimación de su variabilidad. Crucialmente, esa estimación se calcula *sin usar el dato en cuestión*, para que un dato extremo no "enmascare" su propia anomalía. La fórmula es:
$$t_i = \frac{e_i}{S_{(i)}\sqrt{1 - h_i}}$$
donde $S_{(i)}$ es el error estándar estimado sin la observación $i$ y $h_i$ es el leverage.
**Regla práctica:** $|t_i| > 3$ sugiere un outlier potencial (ISLR2, p. 98).
```{r}
#| label: studentized-residuals
stud_res <- rstudent(modelo)
sort(abs(stud_res), decreasing = TRUE)[1:5]
```
::: {.callout-warning}
## Cuidado con la eliminación mecánica
Un outlier no siempre es un error de medición. Puede revelar una deficiencia del modelo (predictor omitido, forma funcional incorrecta). Investigar la causa antes de eliminar observaciones.
:::
### Puntos de alto leverage (hat values)
Un punto de **alto leverage** tiene valores inusuales en los predictores ($X$). **Analogía:** imagina una regla apoyada sobre un punto de apoyo (pivote). Un dato en el centro de la distribución de $X$ es como un peso cerca del pivote — moverlo un poco no cambia mucho la inclinación. Pero un dato en el extremo de $X$ es como un peso al borde de la regla — un pequeño cambio en su valor de $Y$ puede girar toda la recta. Eso es leverage: la *capacidad* de un dato para "tirar" de la recta hacia sí mismo.
El **estadístico de leverage** $h_i$ (diagonal de la hat matrix $\mathbf{H} = \mathbf{X}(\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{X}^\top$) cuantifica cuánta influencia potencial tiene cada observación:
- Siempre se cumple $1/n \leq h_i \leq 1$
- El leverage promedio es $(p + 1)/n$
**Regla práctica:** $h_i > 2(p+1)/n$ merece inspección.
```{r}
#| label: hat-values
h <- hatvalues(modelo)
p <- length(coef(modelo)) - 1
n <- nobs(modelo)
umbral_h <- 2 * (p + 1) / n
cat("Umbral de leverage: 2(p+1)/n =", round(umbral_h, 3), "\n\n")
cat("Observaciones con alto leverage:\n")
h[h > umbral_h]
```
### Distancia de Cook
La **distancia de Cook** combina la información de outlier (residuo grande) y leverage (posición extrema en predictores) en una sola métrica. **En términos simples:** responde a la pregunta "¿cuánto cambiarían *todas* las predicciones del modelo si eliminara esta observación?". Un dato con distancia de Cook alta es como un jugador cuya ausencia cambiaría el resultado del partido — no es simplemente raro, sino que está *moviendo* los resultados del modelo. Formalmente, mide cuánto cambian *todos* los coeficientes estimados si se elimina la observación $i$:
$$D_i = \frac{(\hat{\mathbf{y}} - \hat{\mathbf{y}}_{(i)})^\top (\hat{\mathbf{y}} - \hat{\mathbf{y}}_{(i)})}{(p+1) \cdot \text{MSE}}$$
Puede expresarse también como:
$$D_i = \frac{e_i^2}{(p+1) \cdot \text{MSE}} \cdot \frac{h_i}{(1 - h_i)^2}$$
| Umbral | Criterio |
|---|---|
| $D_i > 4/n$ | Regla conservadora, identifica más observaciones |
| $D_i > 1$ | Regla clásica [@cook1982] |
```{r}
#| label: cooks-distance
cd <- cooks.distance(modelo)
umbral_cook <- 4 / n
cat("Umbral Cook (4/n):", round(umbral_cook, 3), "\n\n")
cat("Observaciones influyentes (D > 4/n):\n")
sort(cd[cd > umbral_cook], decreasing = TRUE)
```
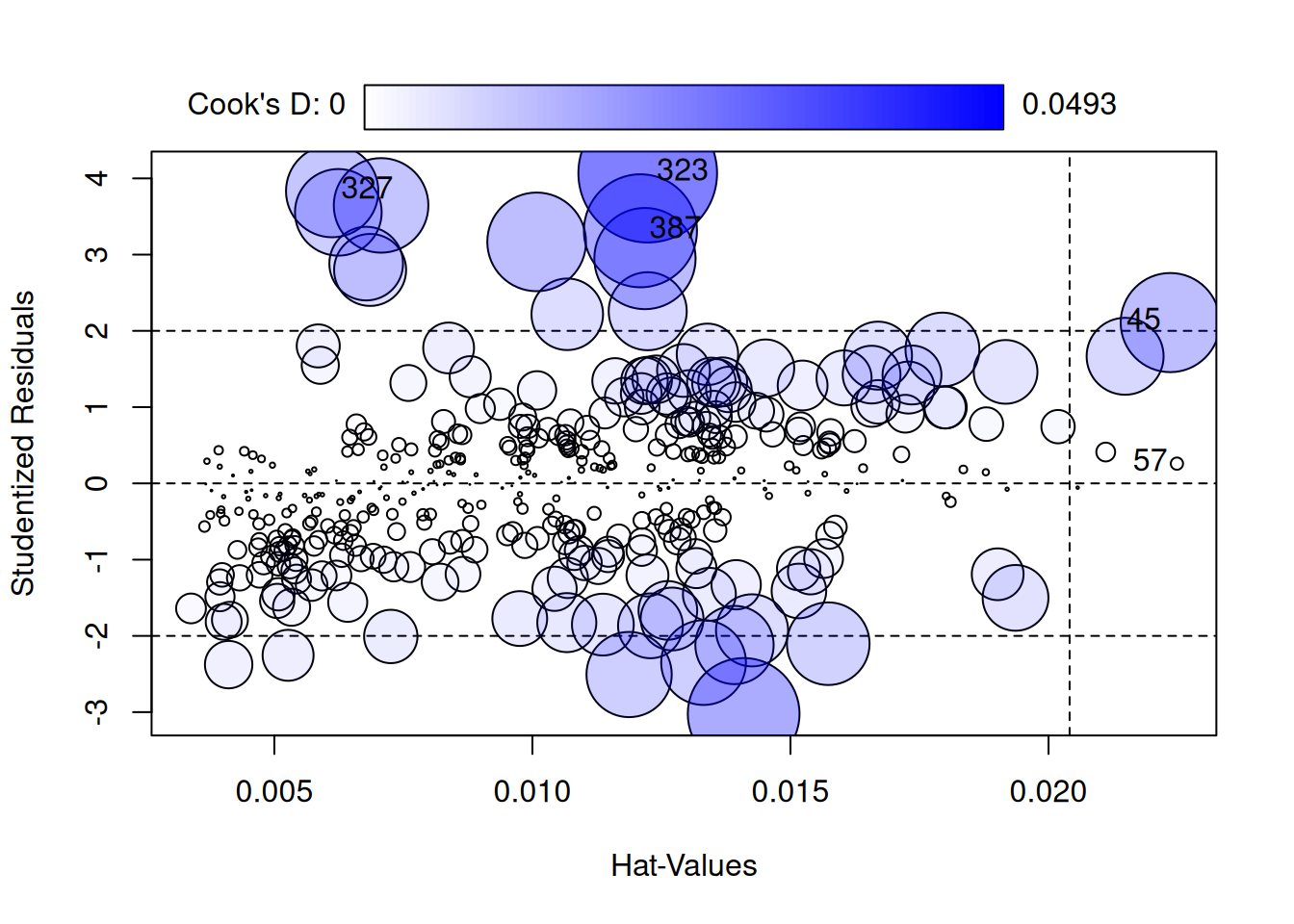
### Gráfico de influencia
El `influencePlot()` del paquete `car` resume los tres diagnósticos en un solo gráfico: el eje X muestra el leverage ($h_i$), el eje Y los residuos studentizados, y el tamaño de cada punto es proporcional a la distancia de Cook.
```{r}
#| label: fig-influence-plot
#| fig-cap: "Gráfico de influencia. Las líneas horizontales marcan ±2 en residuos studentizados. Las líneas verticales marcan leverage = 2(p+1)/n. Puntos grandes = alta distancia de Cook."
influencePlot(modelo)
```
**Referencias:** @james2023 [Sec. 3.3.3]; @cook1982; @belsley1980.
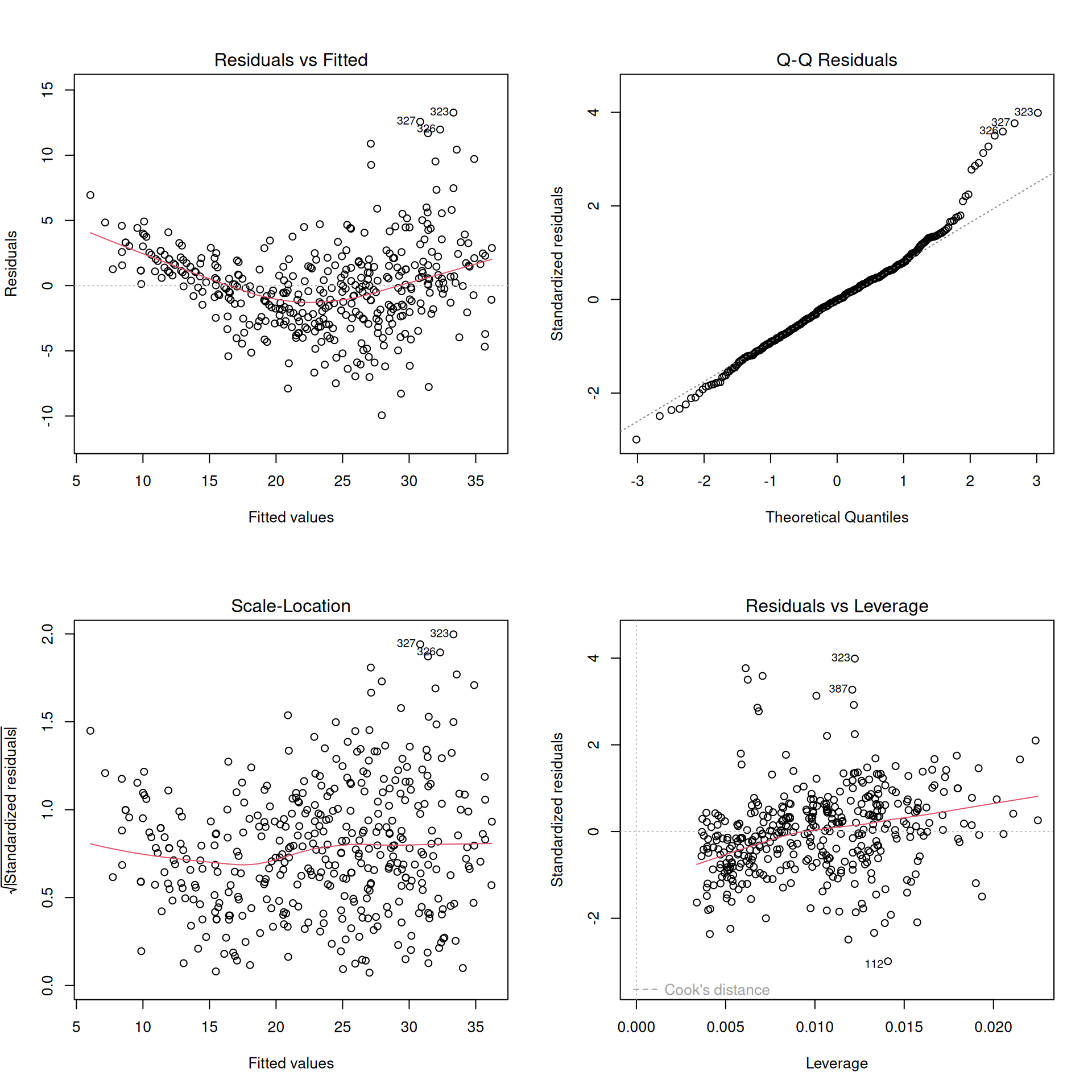
## Diagnóstico visual completo
`plot(modelo)` genera los 4 gráficos canónicos de diagnóstico:
| Gráfico | Evalúa |
|---|---|
| Residuos vs Ajustados | Linealidad + homocedasticidad |
| QQ-plot | Normalidad |
| Scale-Location | Homocedasticidad |
| Residuos vs Leverage | Observaciones influyentes (las líneas punteadas marcan umbrales de Cook's distance) |
```{r}
#| label: fig-diagnostico-completo
#| fig-cap: "Panel completo de diagnóstico. Observaciones etiquetadas son potencialmente influyentes."
#| fig-width: 10
#| fig-height: 10
par(mfrow = c(2, 2))
plot(modelo)
par(mfrow = c(1, 1))
```
## Función resumen: `diagnostico_ols()`
Función que consolida todos los tests en un reporte de consola:
```{r}
#| label: funcion-diagnostico
#| code-fold: true
#| code-summary: "Ver código de la función"
diagnostico_ols <- function(mod, alpha = 0.05) {
pkgs <- c("lmtest", "car", "sandwich")
falta <- pkgs[!vapply(pkgs, requireNamespace, logical(1), quietly = TRUE)]
if (length(falta) > 0) {
stop(
"Paquete(s) requerido(s) no instalado(s): ",
paste(falta, collapse = ", "),
"\n Instalar con: install.packages(c(\"",
paste(falta, collapse = "\", \""),
"\"))",
call. = FALSE
)
}
cat("\n")
cat("================================================================\n")
cat(" DIAGNÓSTICO DE SUPUESTOS OLS - RESUMEN\n")
cat("================================================================\n")
cat("Nivel de significancia:", alpha, "\n")
res <- resid(mod)
n <- length(res)
k <- length(coef(mod)) - 1
cat("n =", n, "| k =", k, "predictores\n")
cat("----------------------------------------------------------------\n\n")
# 1. Normalidad (con guard para n > 5000)
sw <- NULL
cat("1. NORMALIDAD\n")
if (n <= 5000) {
sw <- shapiro.test(res)
cat(
" Shapiro-Wilk: W =",
round(sw$statistic, 4),
"| p =",
format.pval(sw$p.value, digits = 4),
"\n"
)
cat(
" Decisión:",
ifelse(
sw$p.value < alpha,
"Rechaza H0 → Evidencia de no normalidad",
"No rechaza H0 → Compatible con normalidad"
),
"\n\n"
)
} else {
cat(" Shapiro-Wilk: No aplicable (n > 5000). Usar QQ-plot.\n\n")
}
# 2. Homocedasticidad
bp <- lmtest::bptest(mod)
cat("2. HOMOCEDASTICIDAD\n")
cat(
" Breusch-Pagan: BP =",
round(bp$statistic, 4),
"| p =",
format.pval(bp$p.value, digits = 4),
"\n"
)
cat(
" Decisión:",
ifelse(
bp$p.value < alpha,
"Rechaza H0 → Evidencia de heterocedasticidad",
"No rechaza H0 → Compatible con homocedasticidad"
),
"\n\n"
)
# 3. Linealidad (RESET)
rs <- lmtest::resettest(mod, power = 2:3, type = "fitted")
cat("3. ESPECIFICACIÓN (RESET de Ramsey)\n")
cat(
" RESET: F =",
round(rs$statistic, 4),
"| p =",
format.pval(rs$p.value, digits = 4),
"\n"
)
cat(
" Decisión:",
ifelse(
rs$p.value < alpha,
"Rechaza H0 → Posible mala especificación (no linealidad u omisión)",
"No rechaza H0 → Compatible con especificación correcta"
),
"\n\n"
)
# 4. Independencia
bg <- lmtest::bgtest(mod, order = 1)
cat("4. INDEPENDENCIA (no autocorrelación)\n")
cat(
" Breusch-Godfrey (orden 1): LM =",
round(bg$statistic, 4),
"| p =",
format.pval(bg$p.value, digits = 4),
"\n"
)
cat(
" Decisión:",
ifelse(
bg$p.value < alpha,
"Rechaza H0 → Evidencia de autocorrelación",
"No rechaza H0 → Compatible con independencia"
),
"\n"
)
cat(" (Nota: relevante solo si los datos tienen orden temporal)\n\n")
# 5. Multicolinealidad (con manejo de GVIF y k=1)
vif_vals <- NULL
max_vif <- NA
max_name <- NA
cat("5. MULTICOLINEALIDAD\n")
if (k < 2) {
cat(" No aplicable (modelo con un solo predictor).\n\n")
} else {
vif_vals <- car::vif(mod)
if (is.matrix(vif_vals)) {
cat(" (GVIF — variables categóricas detectadas)\n")
gvif_adj <- vif_vals[, "GVIF^(1/(2*Df))"]
max_vif <- max(gvif_adj^2)
max_name <- rownames(vif_vals)[which.max(gvif_adj)]
} else {
max_vif <- max(vif_vals)
max_name <- names(which.max(vif_vals))
}
cat(
" VIF máximo:",
round(max_vif, 2),
"(variable:",
max_name,
")\n"
)
cat(
" Decisión:",
ifelse(
max_vif > 5,
"VIF > 5 → Posible multicolinealidad problemática",
"VIF <= 5 → Sin multicolinealidad severa"
),
"\n\n"
)
}
# 6. Diagnóstico de influencia
cd <- cooks.distance(mod)
umbral_cook <- 4 / n
influyentes <- sum(cd > umbral_cook, na.rm = TRUE)
max_cook <- which.max(cd)
cat("6. DIAGNÓSTICO DE INFLUENCIA\n")
cat(
" Obs. con Cook's D > 4/n:",
influyentes,
"de",
n,
"\n"
)
cat(
" Más influyente:",
names(max_cook),
"(D =",
round(cd[max_cook], 4),
")\n"
)
cat(
" Decisión:",
ifelse(
any(cd > 1, na.rm = TRUE),
"D > 1 → Observación(es) altamente influyente(s)",
ifelse(
influyentes > 0,
paste0(influyentes, " obs. superan 4/n → Revisar manualmente"),
"Sin observaciones altamente influyentes"
)
),
"\n\n"
)
# 7. Comparación OLS vs errores robustos (HC3)
cat("7. COMPARACIÓN: OLS vs ERRORES ROBUSTOS (HC3)\n")
ols_se <- coef(summary(mod))[, "Std. Error"]
rob_ct <- lmtest::coeftest(mod, vcov = sandwich::vcovHC(mod, type = "HC3"))
rob_se <- rob_ct[, "Std. Error"]
cambio_pct <- ifelse(
ols_se > .Machine$double.eps,
round((rob_se / ols_se - 1) * 100, 1),
NA_real_
)
cat(" Cambio en errores estándar (HC3 vs OLS):\n")
for (i in seq_along(cambio_pct)) {
valor <- if (is.na(cambio_pct[i])) {
"SE ≈ 0 (no comparable)"
} else {
sprintf("%+.1f%%", cambio_pct[i])
}
cat(
" ",
names(cambio_pct)[i],
":",
valor,
"\n"
)
}
cat(
" Decisión:",
ifelse(
any(abs(cambio_pct) > 20, na.rm = TRUE),
"Cambios > 20% → heterocedasticidad afecta la inferencia",
"Cambios menores → inferencia OLS estándar es razonable"
),
"\n\n"
)
# Resumen tipo semáforo
cat("================================================================\n")
cat("RESUMEN DE DIAGNÓSTICO\n")
cat("----------------------------------------------------------------\n")
flags <- c(
"No normalidad" = if (!is.null(sw)) unname(sw$p.value < alpha) else NA,
"Heterocedasticidad" = unname(bp$p.value < alpha),
"Mala especificación" = unname(rs$p.value < alpha),
"Autocorrelación" = unname(bg$p.value < alpha),
"Multicolinealidad" = if (!is.na(max_vif)) max_vif > 5 else NA,
"Alta influencia" = any(cd > 1, na.rm = TRUE)
)
for (nm in names(flags)) {
estado <- if (is.na(flags[nm])) {
"[ ? ]"
} else if (flags[nm]) {
"[REVISAR]"
} else {
"[ OK ]"
}
cat(" ", estado, nm, "\n")
}
cat("----------------------------------------------------------------\n")
cat("NOTA: Tests orientativos. SIEMPRE complementar con gráficos.\n")
cat("================================================================\n")
# Dataframe resumen para integración con tidyverse
resumen <- data.frame(
supuesto = c(
"Normalidad",
"Homocedasticidad",
"Especificación",
"Independencia",
"Multicolinealidad",
"Influencia"
),
test = c(
if (!is.null(sw)) "Shapiro-Wilk" else "No aplicable (n > 5000)",
"Breusch-Pagan",
"RESET (Ramsey)",
"Breusch-Godfrey",
if (!is.na(max_vif)) {
paste0("VIF max: ", max_name)
} else {
"No aplicable (k=1)"
},
"Cook's D"
),
estadistico = round(
c(
if (!is.null(sw)) sw$statistic else NA,
bp$statistic,
rs$statistic,
bg$statistic,
max_vif,
max(cd, na.rm = TRUE)
),
4
),
p_value = c(
if (!is.null(sw)) sw$p.value else NA,
bp$p.value,
rs$p.value,
bg$p.value,
NA,
NA
),
decision = c(
if (!is.null(sw)) {
ifelse(sw$p.value < alpha, "Rechaza H0", "No rechaza H0")
} else {
"N/A"
},
ifelse(bp$p.value < alpha, "Rechaza H0", "No rechaza H0"),
ifelse(rs$p.value < alpha, "Rechaza H0", "No rechaza H0"),
ifelse(bg$p.value < alpha, "Rechaza H0", "No rechaza H0"),
if (!is.na(max_vif)) ifelse(max_vif > 5, "VIF > 5", "OK") else "N/A",
ifelse(
any(cd > 1, na.rm = TRUE),
"D > 1",
ifelse(influyentes > 0, "Revisar", "OK")
)
),
stringsAsFactors = FALSE
)
rownames(resumen) <- NULL
# Retornar resultados invisiblemente
invisible(list(
resumen = resumen,
shapiro = sw,
breusch_pagan = bp,
reset = rs,
breusch_godfrey = bg,
vif = vif_vals,
cooks = cd,
robust_se_cambio_pct = cambio_pct,
flags = flags
))
}
```
```{r}
#| label: ejecutar-diagnostico
dx <- diagnostico_ols(modelo)
dx$resumen
```
### Visualización de diagnósticos
```{r}
#| label: plot-diagnostico-ols
#| code-fold: true
plot_diagnostico_ols <- function(mod) {
opar <- par(mfrow = c(2, 2), mar = c(4.5, 4.5, 3, 1))
on.exit(par(opar))
res <- rstandard(mod)
fit <- fitted(mod)
n <- length(res)
k <- length(coef(mod)) - 1
cd <- cooks.distance(mod)
hv <- hatvalues(mod)
# 1. Residuos vs Fitted
plot(
fit,
res,
xlab = "Valores ajustados",
ylab = "Residuos estandarizados",
main = "Residuos vs Ajustados",
pch = 20,
col = "steelblue"
)
abline(h = 0, lty = 2, col = "red")
lines(lowess(fit, res), col = "darkred", lwd = 2)
# 2. QQ-plot
qqnorm(res, main = "QQ-Plot de residuos", pch = 20, col = "steelblue")
qqline(res, col = "red", lwd = 2)
# 3. Leverage vs Residuos
plot(
hv,
res,
xlab = "Leverage (hat value)",
ylab = "Residuos estandarizados",
main = "Leverage vs Residuos",
pch = 20,
col = "steelblue"
)
abline(h = 0, lty = 2, col = "grey50")
abline(v = 2 * (k + 1) / n, lty = 2, col = "red")
legend(
"topright",
legend = paste0("Umbral: 2(k+1)/n = ", round(2 * (k + 1) / n, 3)),
col = "red",
lty = 2,
cex = 0.8,
bty = "n"
)
# 4. Cook's Distance
plot(
seq_along(cd),
cd,
type = "h",
xlab = "Observación",
ylab = "Distancia de Cook",
main = "Distancia de Cook",
col = ifelse(cd > 4 / n, "red", "steelblue"),
lwd = 1.5
)
abline(h = 4 / n, lty = 2, col = "red")
legend(
"topright",
legend = paste0("Umbral: 4/n = ", round(4 / n, 4)),
col = "red",
lty = 2,
cex = 0.8,
bty = "n"
)
}
```
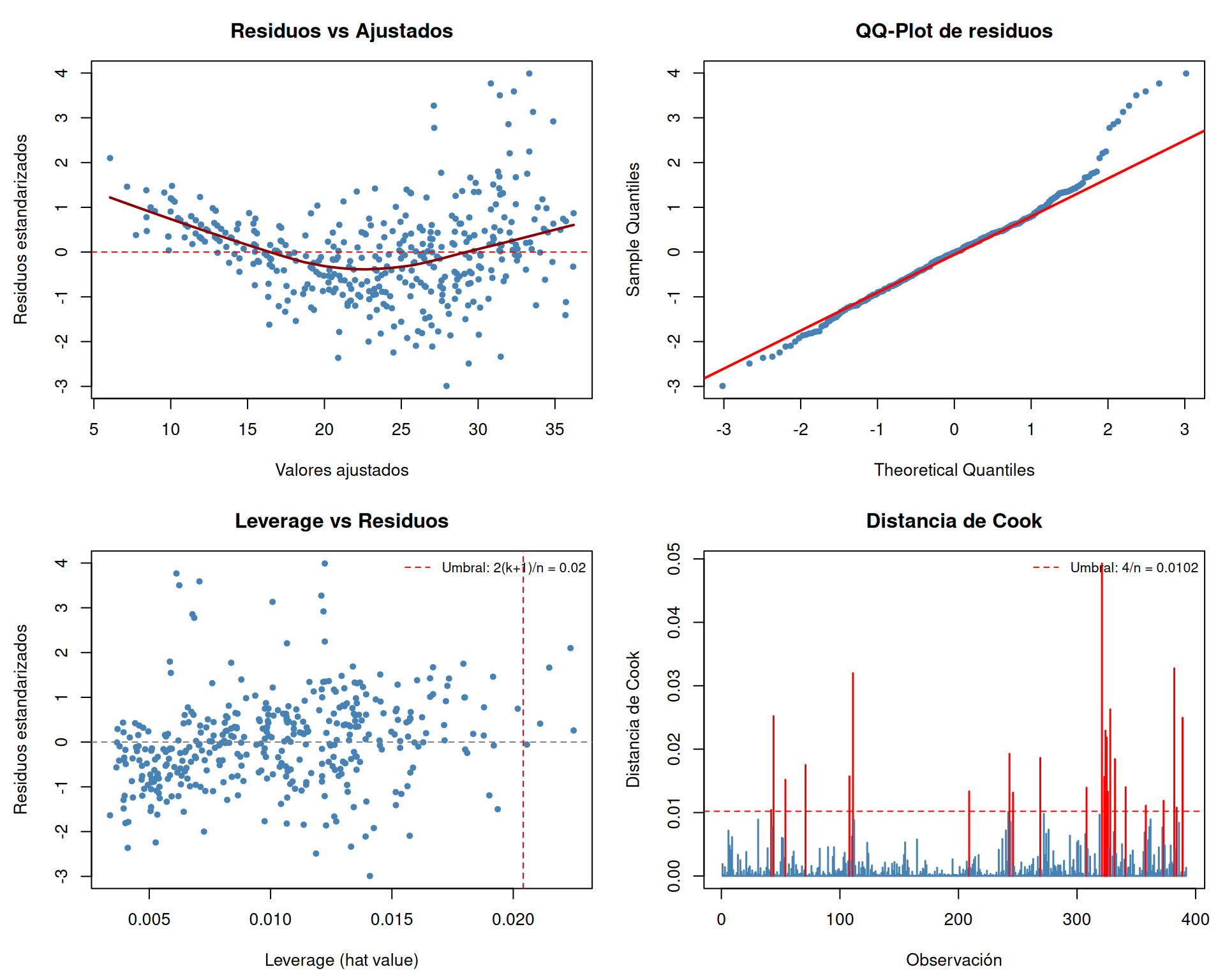
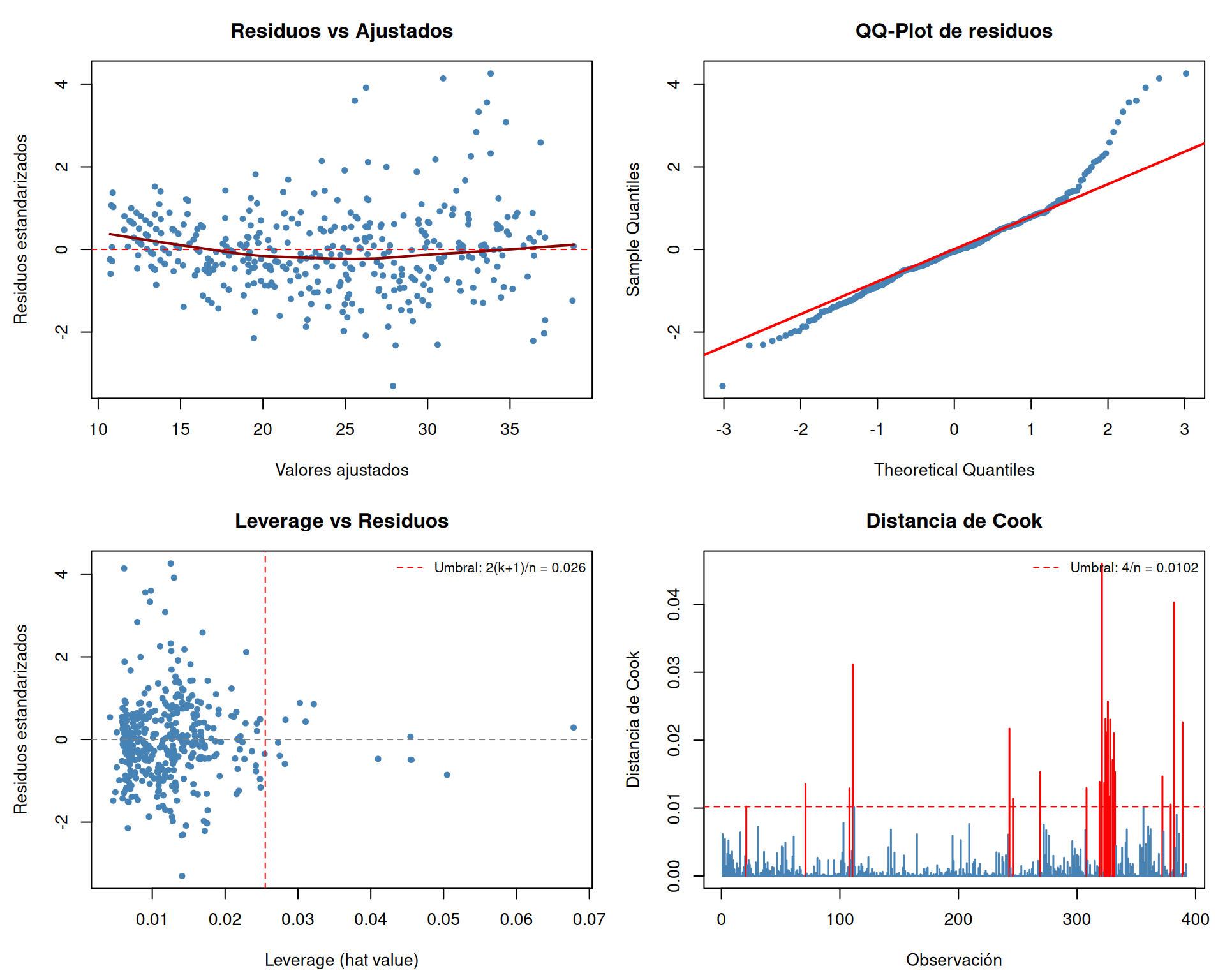
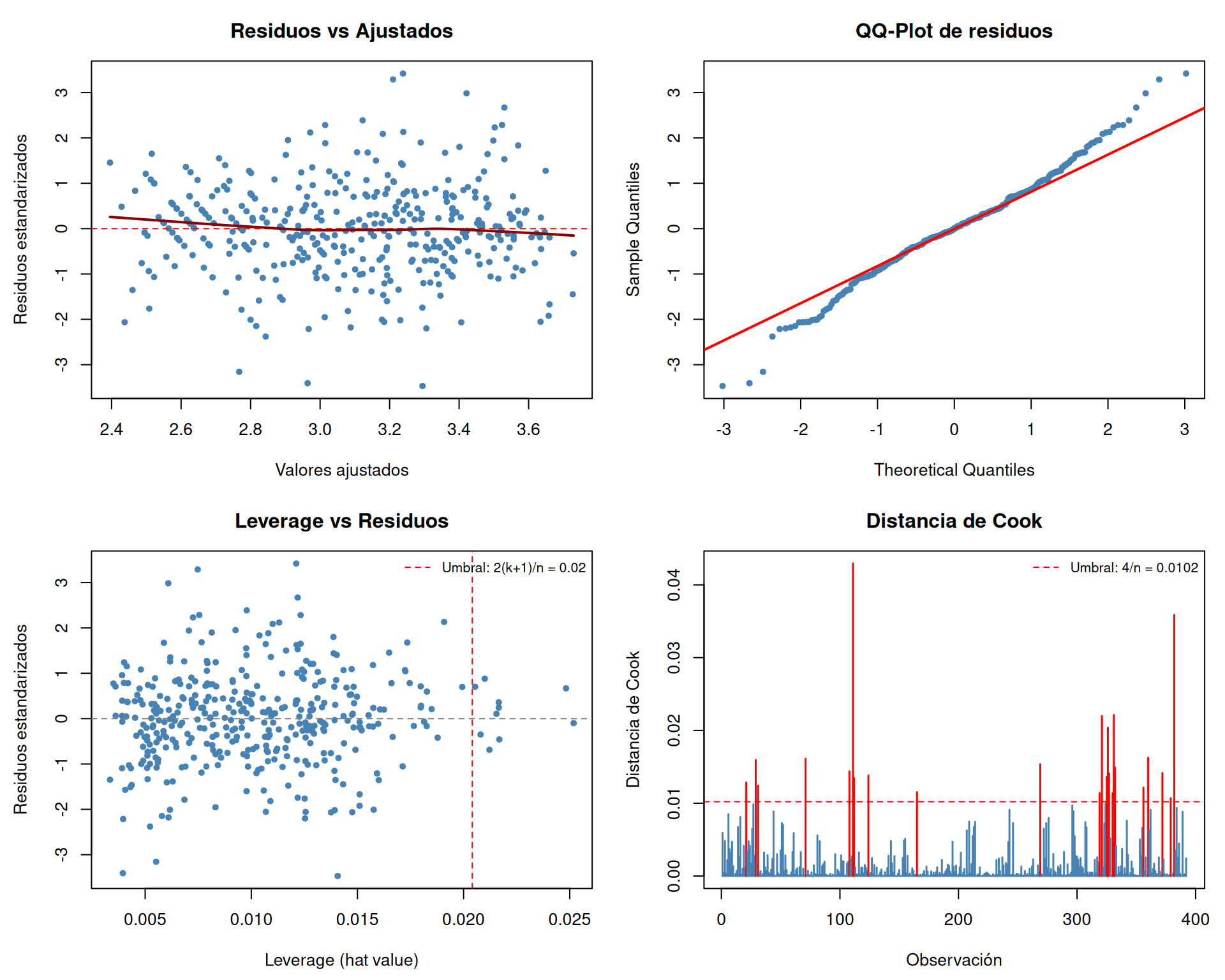
Los gráficos complementan el diagnóstico numérico. El panel muestra cuatro visualizaciones clave: (1) residuos vs valores ajustados para detectar heterocedasticidad y no-linealidad, (2) QQ-plot para evaluar normalidad, (3) leverage para identificar puntos con alta influencia potencial, y (4) distancia de Cook para localizar observaciones que realmente alteran las estimaciones.
```{r}
#| label: ejecutar-plot-diagnostico
#| fig-width: 10
#| fig-height: 8
plot_diagnostico_ols(modelo)
```
## Re-especificación del modelo: antes vs después
### ¿Qué nos dicen los diagnósticos?
El diagnóstico del modelo original (`mpg ~ weight + year + origin`) revela un patrón claro: **la mayoría de los supuestos fallan simultáneamente**. Esto no es coincidencia — cuando un modelo está mal especificado, los problemas se propagan en cascada:
1. **Especificación** (RESET, p ≈ 0): la relación entre `weight` y `mpg` no es lineal. La curva lowess en el gráfico de residuos vs ajustados lo confirma visualmente: hay un patrón cuadrático que el modelo lineal no captura.
2. **Homocedasticidad** (Breusch-Pagan, p ≈ 2.6e-05): la varianza de los residuos crece con los valores ajustados. Pero cuidado: parte de esta "heterocedasticidad" puede ser **espuria** — un artefacto de la mala especificación. Al no capturar la curvatura, los residuos heredan estructura que infla artificialmente la varianza en ciertos rangos.
3. **Normalidad** (Shapiro-Wilk, p ≈ 3e-07): los residuos no son normales. Las colas pesadas en el QQ-plot son, nuevamente, consecuencia de que el modelo no captura la forma funcional correcta.
**Lección clave**: antes de preocuparte por heterocedasticidad o normalidad, **corrige la especificación**. Muchos "problemas" desaparecen solos cuando el modelo captura adecuadamente la relación entre las variables.
### Dos estrategias de corrección
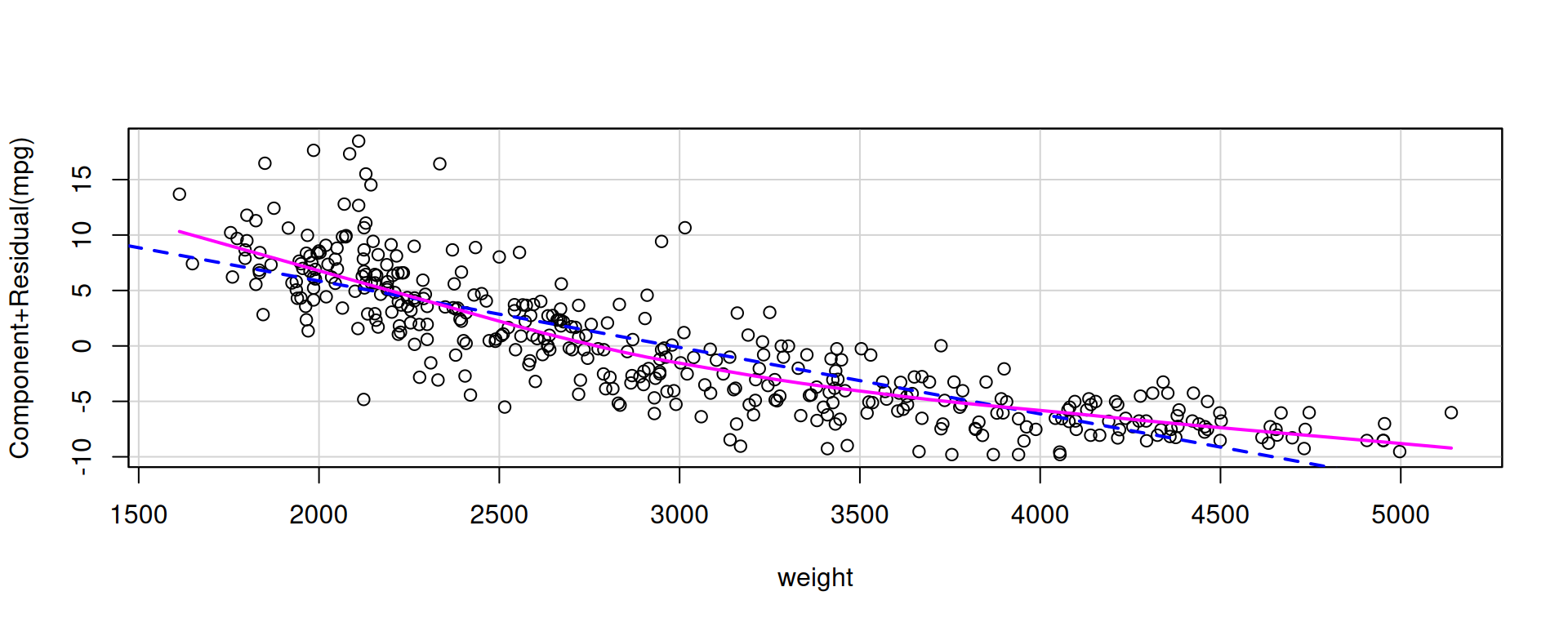
El gráfico de componente + residuos (CR-plot) nos permite ver la forma funcional de cada predictor individualmente:
```{r}
#| label: crplots-modelo-original
#| fig-width: 10
#| fig-height: 4
car::crPlots(modelo, terms = ~weight)
```
La línea punteada (componente lineal) y la línea suave (relación real estimada) divergen claramente para `weight`: la relación es curva. Hay dos formas estándar de corregir esto [para una cobertura completa de transformaciones, ver @wooldridge2020, Cap. 6; @fox2016, Cap. 4 y 12].
#### Opción A: Término cuadrático — `I(weight^2)` con centrado
Agregar `weight^2` al modelo permite que la relación tenga curvatura:
$$\text{mpg} = \beta_0 + \beta_1 \cdot \text{weight}_c + \beta_2 \cdot \text{weight}_c^2 + \beta_3 \cdot \text{year} + \beta_4 \cdot \text{origin} + \varepsilon$$
donde $\text{weight}_c = \text{weight} - \overline{\text{weight}}$ es la variable centrada en su media.
- **Cuándo usarlo**: cuando el gráfico (o la teoría) sugiere una relación cuadrática — es decir, el efecto de `weight` cambia de dirección o se atenúa a medida que `weight` aumenta.
- **Interpretación**: el efecto marginal de `weight` ya **no es constante**. Depende del nivel de `weight`: $\frac{\partial \, \text{mpg}}{\partial \, \text{weight}} = \beta_1 + 2\beta_2 \cdot \text{weight}_c$. Si $\beta_2 < 0$, el efecto negativo del peso sobre el rendimiento se intensifica en autos más pesados.
- **Ventaja**: sigue siendo OLS (lineal en parámetros). Los coeficientes se interpretan en las unidades originales de `mpg`.
- **¿Por qué centrar?** Sin centrar, `weight` y `weight^2` están altamente correlacionados (r > 0.99), lo que infla artificialmente el VIF. Centrar la variable (`weight - mean(weight)`) elimina esta multicolinealidad estructural sin cambiar la curvatura ni los residuos del modelo.
- **Nota**: en R, `I(weight^2)` protege el operador `^` para que R lo interprete como "elevar al cuadrado" y no como interacción de fórmula.
#### Opción B: Transformación log-log — `log(mpg) ~ log(weight)`
Transformar tanto la variable dependiente como el predictor problemático lineariza relaciones de tipo potencia:
$$\log(\text{mpg}) = \beta_0 + \beta_1 \cdot \log(\text{weight}) + \beta_2 \cdot \text{year} + \beta_3 \cdot \text{origin} + \varepsilon$$
- **Cuándo usarlo**: cuando la relación es multiplicativa (un cambio porcentual en peso produce un cambio porcentual constante en rendimiento) o cuando la varianza crece proporcionalmente con el nivel de Y (abanico en residuos vs fitted).
- **Interpretación**: $\beta_1$ es una **elasticidad** — un cambio de 1% en `weight` se asocia con un cambio de $\beta_1$% en `mpg`. Por ejemplo, $\beta_1 = -1.0$ significa que duplicar el peso reduce el rendimiento a la mitad.
- **¿Por qué `log(weight)` también?** Usar solo `log(mpg) ~ weight` (semi-log) asume que cada unidad *absoluta* de peso tiene el mismo efecto porcentual en mpg. Pero un kilo extra no impacta igual a un auto de 900 kg que a uno de 2000 kg. La transformación log-log captura esta proporcionalidad.
- **Ventaja**: ataca dos problemas a la vez — no-linealidad *y* heterocedasticidad tipo abanico.
- **Cuidado**: ya no se puede comparar directamente el $R^2$ con el modelo original (la variable dependiente es diferente). Para una tabla resumen de las 4 combinaciones (level-level, log-level, level-log, log-log) y su interpretación, ver @benoit2011.
#### ¿Cuál elegir?
No hay una respuesta universal. La idea de transformar variables para mejorar el ajuste tiene una larga tradición en estadística [ver @tukey1977, Cap. 3 sobre "re-expresión"]. La familia de transformaciones Box-Cox [@box1964] formaliza esta idea: busca la transformación potencia óptima de Y, donde $\lambda = 1$ es el modelo lineal y $\lambda = 0$ es el logaritmo. En la práctica:
- Si el CR-plot muestra curvatura clara (parábola) → probar `I(weight_c^2)` (centrado para evitar multicolinealidad)
- Si además hay heterocedasticidad tipo abanico → `log(mpg) ~ log(weight)` puede resolver ambos
- **La mejor estrategia**: probar ambas y comparar los diagnósticos
### Ajuste de los modelos corregidos
```{r}
#| label: modelos-corregidos
# Modelo A: término cuadrático con weight centrado
datos$weight_c <- datos$weight - mean(datos$weight)
modelo_quad <- lm(mpg ~ weight_c + I(weight_c^2) + year + origin, data = datos)
# Modelo B: log-log (log en respuesta y en weight)
modelo_log <- lm(log(mpg) ~ log(weight) + year + origin, data = datos)
```
### Diagnóstico del modelo cuadrático
```{r}
#| label: diagnostico-modelo-quad
cat(
"MODELO CUADRÁTICO (centrado): mpg ~ weight_c + I(weight_c²) + year + origin\n\n"
)
dx_quad <- diagnostico_ols(modelo_quad)
dx_quad$resumen
```
```{r}
#| label: plot-diagnostico-quad
#| fig-width: 10
#| fig-height: 8
plot_diagnostico_ols(modelo_quad)
```
### Diagnóstico del modelo log-log
```{r}
#| label: diagnostico-modelo-log
cat("MODELO LOG-LOG: log(mpg) ~ log(weight) + year + origin\n\n")
dx_log <- diagnostico_ols(modelo_log)
dx_log$resumen
```
```{r}
#| label: plot-diagnostico-log
#| fig-width: 10
#| fig-height: 8
plot_diagnostico_ols(modelo_log)
```
### ¿Qué aprendimos?
Compare las tres tablas `resumen` lado a lado. El patrón debería ser revelador:
```{r}
#| label: comparacion-resumen
comparacion <- data.frame(
supuesto = dx$resumen$supuesto,
original = dx$resumen$decision,
cuadratico = dx_quad$resumen$decision,
log = dx_log$resumen$decision,
stringsAsFactors = FALSE
)
names(comparacion) <- c(
"Supuesto",
"Original",
"Cuadrático (centrado)",
"Log-Log"
)
comparacion
```
#### Comparación formal: AIC corregido
El criterio de información de Akaike [AIC; @akaike1974] penaliza la complejidad del modelo y permite comparar ajustes: **menor AIC = mejor balance entre ajuste y parsimonia** [ver @burnham2002, para reglas de interpretación de delta-AIC]. Sin embargo, `AIC()` solo es comparable entre modelos con la *misma variable dependiente*. Comparar directamente el AIC de un modelo con Y contra uno con log(Y) es un error frecuente — las escalas son distintas y las log-verosimilitudes no son comparables.
Para hacer la comparación válida, hay que ajustar el AIC del modelo log por el **Jacobiano de la transformación**. El cambio de variable de Y a log(Y) introduce un factor $1/y_i$ en la densidad de cada observación, lo que se traduce en restar $\sum \log(y_i)$ de la log-verosimilitud. En términos de AIC:
$$\text{AIC}_{\text{corregido}} = \text{AIC}_{\log} + 2 \sum_{i=1}^{n} \log(y_i)$$
```{r}
#| label: comparacion-aic
# AIC de modelos con misma variable dependiente (mpg) → comparables directamente
aic_original <- AIC(modelo)
aic_quad <- AIC(modelo_quad)
# AIC del modelo log → requiere corrección por Jacobiano
aic_log_crudo <- AIC(modelo_log)
aic_log_corregido <- aic_log_crudo + 2 * sum(log(datos$mpg))
data.frame(
modelo = c(
"Original (lineal)",
"Cuadrático (centrado)",
"Log-Log (corregido)"
),
AIC = round(c(aic_original, aic_quad, aic_log_corregido), 1),
delta_AIC = round(
c(aic_original, aic_quad, aic_log_corregido) -
min(c(aic_original, aic_quad, aic_log_corregido)),
1
),
stringsAsFactors = FALSE
)
```
La columna `delta_AIC` muestra la diferencia respecto al mejor modelo (delta = 0). Los resultados son claros:
- El modelo **log-log** tiene el menor AIC (delta = 0) — es el que mejor equilibra ajuste y parsimonia.
- El modelo **cuadrático centrado** mejora respecto al original, pero queda a más de 100 unidades del log-log. El término cuadrático captura algo de la curvatura, pero no la naturaleza multiplicativa de la relación.
- El modelo **original lineal** es el peor con diferencia (delta ≈ 198). La forma funcional lineal simplemente no describe estos datos.
Reglas prácticas para interpretar `delta_AIC`: un delta < 2 indica modelos esencialmente equivalentes; entre 4 y 7 hay evidencia moderada a favor del mejor; un delta > 10 indica que el modelo es **sustancialmente peor**. Con deltas de 118 y 198, no hay ambigüedad: el modelo log-log es claramente superior.
Nótese que esta conclusión converge con los diagnósticos de supuestos: el único modelo que pasa especificación (RESET) y homocedasticidad (Breusch-Pagan) es también el que tiene menor AIC. **Los tests y el AIC cuentan la misma historia** — la forma funcional correcta importa más que cualquier corrección post-hoc.
::: {.callout-important}
## Conclusión: modelo seleccionado
El modelo seleccionado es el **log-log**:
$$\log(\text{mpg}) = \beta_0 + \beta_1 \cdot \log(\text{weight}) + \beta_2 \cdot \text{year} + \beta_3 \cdot \text{origin} + \varepsilon$$
porque:
- **Corrige la mala especificación** (RESET no significativo) — la relación mpg-peso es multiplicativa, no aditiva.
- **Elimina la heterocedasticidad** (Breusch-Pagan no significativo) — el logaritmo estabiliza la varianza.
- **Mantiene interpretabilidad** — los coeficientes son elasticidades: un cambio de 1% en peso se asocia con un cambio de $\beta_1$% en rendimiento.
:::
Ahora analicemos qué pasó y por qué.
#### 1. La especificación es el supuesto más importante — y el primero que hay que corregir
El modelo original fallaba en normalidad, homocedasticidad *y* especificación. Pero al corregir la forma funcional con el modelo log-log, la homocedasticidad se resolvió sola. No eran dos problemas independientes — la heterocedasticidad era un *síntoma* de la mala especificación.
#### 2. No toda corrección funciona igual
El término cuadrático centrado (`weight_c + I(weight_c^2)`) eliminó la multicolinealidad artificial, pero no capturó adecuadamente la relación mpg-peso. El modelo log-log sí, porque la relación es multiplicativa: un kilo extra no impacta igual a un auto liviano que a uno pesado. La elección de transformación debe estar guiada por la naturaleza de los datos, no por ensayo y error ciego.
#### 3. Los rechazos restantes no invalidan el modelo
El modelo log-log aún rechaza normalidad (Shapiro-Wilk) e independencia (Breusch-Godfrey), pero ninguno compromete la inferencia en este contexto:
- **Normalidad**: con n = 392 observaciones, la inferencia es válida por resultados asintóticos (consistencia de los estimadores y convergencia de la distribución). Además, los errores estándar robustos (HC3) no difieren sustancialmente de los OLS — lo que confirma que la heterocedasticidad residual, si existe, es menor.
- **Independencia**: el test de Breusch-Godfrey detecta dependencia en el *orden* de los datos. Dado que el dataset `Auto` no tiene estructura temporal ni de panel explícita, este resultado no se interpreta como evidencia relevante de autocorrelación. Si hubiera preocupación por clustering (e.g., autos del mismo fabricante), la solución sería errores agrupados, no una re-especificación.
#### 4. El diagnóstico es iterativo, no binario
Un modelo que rechaza Shapiro-Wilk con n = 392 pero pasa especificación y homocedasticidad es **más confiable** para inferencia que uno que "pasa" normalidad pero está mal especificado. El objetivo no es "pasar todos los tests" sino entender qué problemas son reales, cuáles son síntomas, y cuáles son irrelevantes en tu contexto.
::: {.callout-tip}
## Framework de trabajo
Este análisis sigue un flujo estándar que puedes replicar con cualquier modelo:
1. Ajustar el modelo → `lm()`
2. Ejecutar diagnóstico completo → `diagnostico_ols()`
3. Identificar problemas **estructurales** (especificación, no síntomas)
4. Corregir la especificación → transformaciones, términos adicionales
5. Re-ejecutar `diagnostico_ols()` y comparar
La función no reemplaza el análisis: **lo estructura**.
:::
> *En regresión, la mayoría de los problemas no se corrigen con tests — se corrigen con mejores modelos.*
## Checklist interpretativa final
Una vez completado el diagnóstico, la pregunta definitiva no es "¿pasaron todos los tests?" sino: **¿las conclusiones del análisis son robustas a los problemas detectados?**
Para responder, compare los resultados del modelo original con los del modelo corregido:
| Pregunta | Si la respuesta es "sí" |
|---|---|
| ¿Los coeficientes cambian sustancialmente al corregir los problemas? | La violación es relevante |
| ¿Los p-values cruzan el umbral de significancia (de significativo a no, o viceversa)? | La inferencia depende del supuesto |
| ¿Las predicciones son estables ante la eliminación de observaciones influyentes? | Hay dependencia de puntos específicos |
| ¿Las conclusiones cambian al usar errores robustos (HC3) en lugar de los estándar? | La heterocedasticidad afecta la inferencia |
Si las respuestas son mayoritariamente "no cambia mucho", el modelo original es **robusto** a las desviaciones encontradas y las conclusiones son confiables. Si alguna respuesta es "sí", la corrección correspondiente no es opcional.
::: {.callout-tip}
## Criterio final
El objetivo del diagnóstico no es lograr un modelo "perfecto" que pase todos los tests. Es **entender las limitaciones del modelo y cuantificar su impacto en las conclusiones**. Un modelo con heterocedasticidad moderada y errores robustos puede ser más útil que uno que "pasa" todos los tests pero omite un predictor importante.
:::
## Apéndice: Referencias {.appendix}
::: {#refs}
:::