Curso de SQL y PostgreSQL
Aprende a consultar bases de datos desde cero. Un curso practico y progresivo que te llevara desde tu primera query SELECT hasta optimizar consultas con indices y EXPLAIN.
Enfocado en pensar en SQL y en el rendimiento de tus queries. No necesitas experiencia previa con bases de datos.
El timer Pomodoro te ayuda a estudiar en bloques cortos de concentracion (25 min) con descansos. Esta demostrado que mejora el aprendizaje y reduce la fatiga mental.
Parte de Hazla con Datos
Este curso es un recurso complementario de Hazla con Datos, una comunidad enfocada en programacion y ciencia de datos en salud. Encuentra mas cursos, recursos y herramientas para tu camino profesional.
Visitar hazlacondatos.com →Introduccion a SQL y PostgreSQL
¿Que es una base de datos?
Imagina que tienes un negocio y llevas el registro de tus clientes en una libreta. Al principio funciona bien, pero cuando tienes 500 clientes y necesitas encontrar a todos los de Santiago que compraron el mes pasado… la libreta se queda corta.
Una base de datos es exactamente eso: un sistema organizado para almacenar, buscar y manipular informacion de forma eficiente. En lugar de una libreta, tienes un software optimizado que puede buscar entre millones de registros en milisegundos.
Las bases de datos relacionales (las que vamos a usar en este curso) organizan la informacion en tablas con filas y columnas, como una hoja de calculo pero con superpoderes:
- Pueden manejar millones de registros sin perder velocidad
- Garantizan que los datos sean consistentes
- Permiten relacionar datos entre distintas tablas
- Multiples usuarios pueden acceder a la vez sin problemas
¿Que es SQL?
SQL (Structured Query Language) es el lenguaje que usamos para comunicarnos con bases de datos relacionales. Nacio en los anos 70 en IBM y hoy en dia es uno de los lenguajes mas usados del mundo.
SQL se pronuncia...
Hay dos formas aceptadas: “ese-cu-ele” (letra por letra) o “sequel” (como en ingles). Ambas estan bien. En este curso usaremos “SQL” como sigla.
El paradigma declarativo
Antes de ver codigo, necesitas entender algo fundamental: SQL pertenece al paradigma declarativo. Esto cambia completamente la forma en que piensas al programar.
En programacion existen dos grandes familias de paradigmas:
-
Imperativo: tu escribes los pasos exactos que la computadora debe seguir. Le dices como hacer algo. Es lo que hacen lenguajes como Python, JavaScript, Java o C. Tu controlas el flujo: bucles, condicionales, variables que van cambiando paso a paso.
-
Declarativo: tu describes el resultado que quieres y el sistema decide como obtenerlo. No te preocupas por el orden de ejecucion, ni por los algoritmos internos, ni por como se recorren los datos. Solo defines que necesitas.
SQL es declarativo. Esto significa que cuando escribes una consulta, no estas dando instrucciones paso a paso. Estas haciendo una declaracion de lo que quieres obtener:
-- Tu describes lo que quieres:SELECT nombre, emailFROM clientesWHERE ciudad = 'Santiago';Con esa consulta le estas diciendo: “dame el nombre y email de los clientes que viven en Santiago”. No le dices como buscar, en que orden recorrer los datos ni que algoritmo usar. La base de datos se encarga de eso.
¿Por que esto importa? Porque libera al programador de pensar en la implementacion. PostgreSQL tiene un planificador de consultas (query planner) que analiza tu consulta y decide la estrategia mas eficiente para ejecutarla. Puede usar indices, paralelismo, distintos algoritmos de ordenamiento… todo sin que tu lo pidas. Tu trabajo es describir bien lo que necesitas; el trabajo del motor es encontrar la mejor forma de darlo.
Otros lenguajes declarativos
SQL no es el unico lenguaje declarativo. HTML describe la estructura de una pagina (no como renderizarla). CSS describe estilos (no como pintarlos). Las expresiones regulares describen patrones (no como buscarlos). Si ya usaste alguno de estos, ya tienes experiencia con el paradigma declarativo.
¿Que es PostgreSQL?
PostgreSQL (o simplemente “Postgres”) es un sistema de gestion de bases de datos relacional, gratuito y de codigo abierto. Es uno de los mas potentes y populares del mundo, usado por empresas como Apple, Instagram, Spotify y Netflix.
¿Por que aprender PostgreSQL?
- Es gratis y open source: sin licencias ni costos ocultos
- Es potente: soporta consultas complejas, datos JSON, busqueda de texto completo y mucho mas
- Es el estandar de la industria: si aprendes Postgres, puedes trabajar con casi cualquier base de datos relacional
- Gran comunidad: documentacion excelente y millones de desarrolladores que lo usan
- Cumple con el estandar SQL: lo que aprendas aqui aplica a MySQL, SQL Server, SQLite y otros
¿Y otras bases de datos?
El 90% de lo que vas a aprender en este curso funciona igual en MySQL, SQL Server, SQLite y otros motores SQL. PostgreSQL tiene algunas funciones extra, pero las bases son las mismas.
Declarativo vs imperativo: un ejemplo concreto
Para que la diferencia quede clara, veamos el mismo problema resuelto en ambos paradigmas.
En Python (imperativo), para obtener los clientes de Santiago escribirias algo asi:
# Enfoque imperativo (paso a paso)clientes_santiago = []for cliente in todos_los_clientes: if cliente.ciudad == "Santiago": clientes_santiago.append(cliente.nombre)En SQL, simplemente describes lo que quieres:
-- Enfoque declarativo (describes el resultado)SELECT nombreFROM clientesWHERE ciudad = 'Santiago';No le dices a la base de datos “recorre todos los clientes uno por uno y fijate si la ciudad es Santiago”. Le dices “quiero los nombres donde la ciudad sea Santiago” y ella decide la forma mas eficiente de hacerlo.
Por que importa esta distincion
Si vienes de Python, R, JavaScript o cualquier lenguaje de proposito general, tu cerebro esta entrenado para pensar en pasos: “primero recorro, luego filtro, luego guardo”. Esa logica no sirve en SQL. Intentar escribir SQL como si fuera un bucle es una de las principales fuentes de frustacion (y de consultas lentas) en principiantes. La forma de abordar el problema es fundamentalmente distinta: en SQL no controlas el como, solo defines el que.
La buena noticia es que no estas solo en esta transicion. Existen frameworks en lenguajes imperativos que adoptan un estilo declarativo muy similar al de SQL, lo que facilita mucho el salto mental:
- Python:
pandaspermite encadenar operaciones como.query(),.groupby(),.merge()que se parecen mucho aWHERE,GROUP BYyJOIN. SQLAlchemy va un paso mas alla y te deja construir consultas SQL con sintaxis Python. - R:
dplyr(parte del tidyverse) fue disenado explicitamente para imitar la logica de SQL. Funciones comofilter(),select(),group_by()ysummarise()son practicamente traducciones directas de clausulas SQL.
Si ya usas alguno de estos, vas a notar que aprender SQL se siente familiar. Y si aun no los conoces, aprender SQL primero te va a hacer mucho mas productivo cuando los uses despues.
Todo tiene un costo
Cada operacion SQL tiene un costo computacional. Cuando escribes SELECT * FROM clientes, la base de datos tiene que leer todas las columnas de cada fila, transferirlas por red y formatearlas para mostrartelas — aunque solo necesites el nombre y el email. Por eso, en aplicaciones reales siempre se especifican las columnas exactas que se necesitan (SELECT nombre, email FROM clientes). El SELECT * es perfecto para explorar datos o dar tus primeros pasos con una tabla, pero en produccion es un desperdicio de recursos. A lo largo de este curso vamos a ir aprendiendo como escribir consultas que hagan solo el trabajo necesario.
Ejercicios
Estos ejercicios no requieren tener PostgreSQL instalado todavia. Son para reforzar los conceptos de este modulo. En el Modulo 2 vas a preparar tu entorno y cargar la base de datos tienda que usaremos en todo el curso.
La base de datos tienda
A lo largo del curso trabajaremos con una base de datos llamada tienda que tiene 5 tablas: productos (id, nombre, precio, categoria, stock, fecha_creacion), clientes (id, nombre, email, ciudad, fecha_registro), pedidos (id, cliente_id, fecha, total, estado), detalle_pedidos (id, pedido_id, producto_id, cantidad, precio_unitario) y empleados (id, nombre, departamento, salario, fecha_contratacion, jefe_id).
Ejercicio 1: Imagina que tienes la tabla productos con las columnas: id, nombre, precio, categoria, stock y fecha_creacion. Escribe en palabras que le pedirias a SQL para obtener: (a) todos los nombres de productos, y (b) los productos con precio mayor a 100.
Ver solucion
(a) “Dame la columna nombre de la tabla productos” → SELECT nombre FROM productos;
(b) “Dame todos los productos donde el precio sea mayor a 100” → SELECT * FROM productos WHERE precio > 100;
Lo importante es que pienses en que quieres, no en como obtenerlo. SQL es declarativo: describes el resultado, no los pasos.
Ejercicio 2: Identifica cual de estos enfoques es declarativo y cual es imperativo:
- Opcion A: “Recorre cada fila de la tabla clientes. Si la ciudad es ‘Santiago’, guarda el nombre en una lista.”
- Opcion B: “Dame los nombres de la tabla clientes donde la ciudad sea Santiago.”
Ver solucion
- Opcion A es imperativa: describes los pasos (recorrer, verificar, guardar). Es como lo harias en Python o JavaScript con un bucle.
- Opcion B es declarativa: describes el resultado que quieres. Es como lo haces en SQL:
SELECT nombre FROM clientes WHERE ciudad = 'Santiago';En SQL siempre usamos el enfoque B. Le decimos a la base de datos que queremos y ella decide como obtenerlo.
Ejercicio 3: Sin ejecutar nada, lee esta consulta SQL y describe en palabras que resultado esperas:
SELECT nombre, precioFROM productosWHERE categoria = 'Electronica'ORDER BY precio DESC;Ver solucion
“Dame el nombre y precio de todos los productos que son de la categoria Electronica, ordenados de mayor a menor precio.”
El resultado seria una lista de productos electronicos mostrando solo dos columnas (nombre y precio), con el mas caro arriba y el mas barato abajo. Desglose:
SELECT nombre, precio→ solo esas dos columnasFROM productos→ de la tabla productosWHERE categoria = 'Electronica'→ solo los de esa categoriaORDER BY precio DESC→ ordenados de mayor a menor
Ejercicio 4: ¿Por que SELECT * FROM productos es menos eficiente que SELECT nombre, precio FROM productos? ¿En que situacion usarias SELECT *?
Ver solucion
SELECT * pide todas las columnas de la tabla (id, nombre, precio, categoria, stock, fecha_creacion), aunque solo necesites dos. Esto significa:
- Mas datos leidos del disco
- Mas datos transferidos por la red
- Mas memoria usada para procesar los resultados
SELECT nombre, precio solo pide las columnas que necesitas, lo cual es mas rapido y consume menos recursos.
¿Cuando usar SELECT *? Es util para explorar una tabla que no conoces, para ver su estructura y datos. Pero en consultas de produccion (aplicaciones, reportes automaticos), siempre es mejor especificar las columnas exactas.
¿Que sigue?
En el proximo modulo vas a preparar tu entorno de trabajo: instalar PostgreSQL, configurar DBeaver y cargar la base de datos de practica que usaremos a lo largo de todo el curso.
Preparando el entorno
En este modulo vas a preparar tu entorno de trabajo. Al final tendras PostgreSQL funcionando, un cliente SQL listo para usar y la base de datos de practica cargada con datos. Todo lo que necesitas para seguir el resto del curso.
Que necesitas
Dos cosas:
- Un servidor PostgreSQL — donde viven las bases de datos
- Un cliente SQL — la herramienta donde escribes y ejecutas consultas
Vamos a instalar ambos paso a paso.
Quieres probar antes de instalar?
Existen playgrounds online donde puedes ejecutar SQL directamente en el navegador sin instalar nada. Mira la seccion “Playgrounds online” mas abajo. Son utiles como primer acercamiento, pero para seguir todo el curso necesitaras un entorno local.
Paso 1: Instalar PostgreSQL
Descarga PostgreSQL desde postgresql.org/download y sigue el instalador para tu sistema operativo.
Durante la instalacion:
- Te pedira crear una contraseña para el usuario
postgres. Anotala en algun lugar seguro, la necesitaras para conectarte. - Deja el puerto en
5432(es el puerto por defecto). - No necesitas instalar componentes adicionales como Stack Builder.
Verificar la instalacion
En Windows, busca “SQL Shell (psql)” en el menu de inicio. En macOS/Linux, abre una terminal y escribe psql --version. Si ves un numero de version, la instalacion fue exitosa.
Paso 2: Instalar DBeaver Community
DBeaver es un cliente SQL gratuito y visual. Es el que vamos a usar a lo largo del curso porque tiene una interfaz amigable, soporta multiples bases de datos y funciona en Windows, macOS y Linux.
Descargalo desde dbeaver.io/download e instalalo normalmente.
Otras opciones de cliente SQL
Si ya tienes experiencia, puedes usar pgAdmin (viene con PostgreSQL), psql (terminal), o cualquier otro cliente SQL. Todo lo que veremos funciona en cualquier herramienta que pueda conectarse a PostgreSQL.
Paso 3: Conectarte a PostgreSQL desde DBeaver
Abre DBeaver y sigue estos pasos para crear tu primera conexion:
- Ve al menu Database → New Database Connection (o usa el atajo
Ctrl+Shift+N) - Selecciona PostgreSQL en la lista y click en Next
- Completa los datos de conexion:
- Host:
localhost - Port:
5432 - Database:
postgres(la base de datos por defecto) - Username:
postgres - Password: la contraseña que creaste durante la instalacion
- Host:
- Ve a la pestaña PostgreSQL (en la parte superior del dialogo) y marca la opcion Show all databases
- Click en Test Connection para verificar que funciona
- Si el test es exitoso, click en Finish
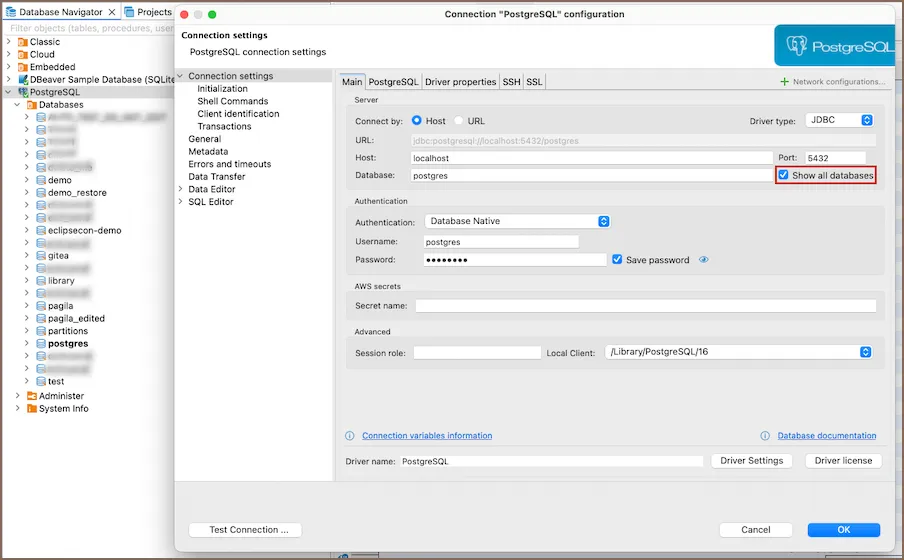
Por que activar Show all databases?
PostgreSQL en DBeaver solo muestra por defecto la base de datos a la que te conectaste (postgres). Si no activas Show all databases, cuando crees la base de datos tienda mas adelante, no la veras en el panel de navegacion. Esta opcion solo esta disponible cuando usas el tipo de conexion Host (que es el que viene por defecto).
Si la conexion falla
Verifica que: (1) PostgreSQL esta corriendo como servicio, (2) el puerto es 5432, (3) la contraseña es correcta. En Windows, busca “Servicios” y verifica que “postgresql” este en estado “Ejecutando”.
Paso 4: Conociendo DBeaver
Antes de crear la base de datos del curso, vamos a conocer las partes principales de DBeaver. Asi vas a saber exactamente donde escribir SQL, como ejecutarlo y donde ver los resultados.
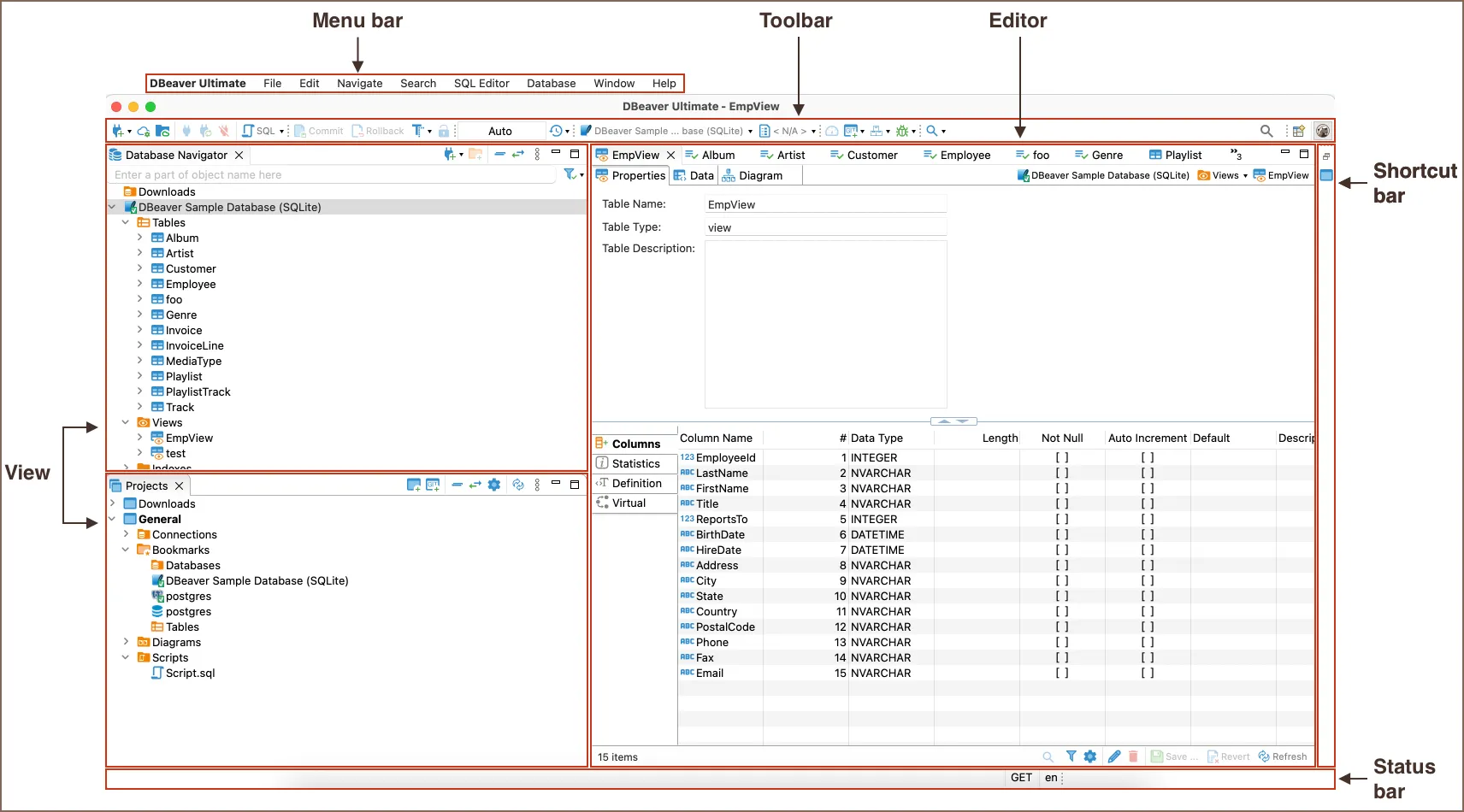
La ventana principal
Cuando abras DBeaver, vas a ver una ventana dividida en varias areas. Cada una tiene un proposito especifico:
- Menu bar (arriba): los menus File, Edit, SQL Editor, Database, Window, etc. Desde aca accedes a todas las funciones de DBeaver.
- Toolbar (debajo del menu): botones de acceso rapido para las acciones mas comunes, como crear una conexion o abrir un editor SQL.
- Views (paneles laterales): ventanas como el Database Navigator (a la izquierda) que muestran informacion de navegacion. Es como el “explorador de archivos” pero para bases de datos.
- Editor (area central): donde se abren los editores SQL, las propiedades de tablas, los datos, los diagramas, etc. Es el area donde vas a trabajar la mayor parte del tiempo.
- Status bar (abajo): muestra informacion de estado de la conexion actual.
Cada panel se puede cerrar, minimizar o maximizar usando los botones en su barra de titulo:

Se te cerro un panel?
Si cierras el Database Navigator por accidente, puedes reabrirlo desde el menu Window → Database Navigator.
Database Navigator (panel izquierdo)
El Database Navigator es el panel mas importante. Muestra un arbol jerarquico con toda la estructura de tus bases de datos, similar a un explorador de carpetas:
Conexion (PostgreSQL) └── Databases └── tienda └── Schemas └── public ├── Tables │ ├── productos │ ├── clientes │ └── ... ├── Views └── FunctionsUn Schema es como una carpeta que organiza las tablas dentro de una base de datos. PostgreSQL crea automaticamente un schema llamado public donde van tus tablas por defecto. No necesitas crear schemas adicionales para este curso.
Para navegar, haz click en la flecha (o triangulo) junto a cada elemento para expandirlo y ver su contenido. Desde aca puedes explorar tablas, columnas y relaciones sin escribir una sola linea de SQL.
Acciones utiles del Navigator:
- Click derecho en una tabla → aparece un menu con opciones como View Table (ver datos), Generate SQL (generar consultas automaticamente), Export Data (exportar datos), etc.
- Doble click en una tabla → abre sus propiedades con pestañas: Properties, Data (datos), Diagram (diagrama ER)
- Arrastrar una tabla al editor SQL → inserta el nombre de la tabla en tu consulta
Simple vs Advanced view
Haz click derecho en tu conexion → Connection view para cambiar entre Simple (muestra solo lo esencial: tablas, vistas) y Advanced (muestra todo, incluyendo objetos avanzados del sistema). Para este curso, Simple es suficiente.
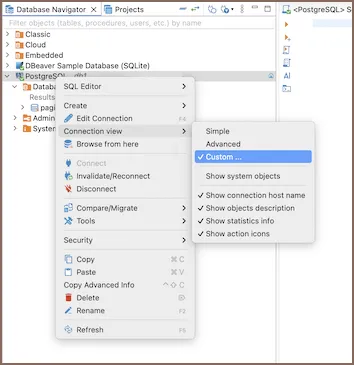
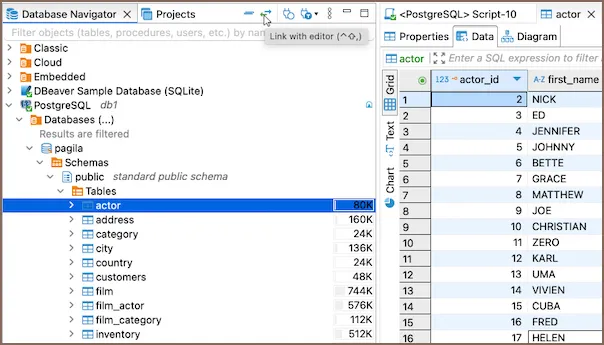
Filtrar objetos: usa la barra de busqueda en la parte superior del Navigator para encontrar tablas u objetos por nombre. Es muy util cuando una base de datos tiene muchas tablas.
Link with Editor: el boton Link with Editor en la toolbar del Navigator sincroniza la seleccion del arbol con el editor activo. Si lo activas y abres una tabla, el Navigator automaticamente la resalta en el arbol.
SQL Editor: donde escribes y ejecutas SQL
El SQL Editor es el area donde vas a escribir tus consultas SQL durante todo el curso. Piensa en el como un editor de texto, pero conectado directamente a tu base de datos.
Como abrirlo:
- Ve al menu SQL Editor → New SQL Editor
- O usa el atajo de teclado:
Ctrl+](Windows/Linux) o⌃](macOS)
Una vez abierto, simplemente escribe tu SQL en el area de texto. Los resultados apareceran en un panel debajo del editor.
Como ejecutar SQL:
Hay tres formas de ejecutar codigo SQL. Es importante conocer la diferencia:
| Que quieres hacer | Que hacer | Windows/Linux | macOS |
|---|---|---|---|
| Ejecutar una sentencia (donde esta tu cursor) | Pon el cursor en la linea y presiona el atajo | Ctrl+Enter | ⌘+Enter |
| Ejecutar todo el script completo | Presiona el atajo directamente | Alt+X | ⌥+X |
| Ejecutar solo una parte | Selecciona el texto con el mouse y presiona el atajo | Seleccionar + Ctrl+Enter | Seleccionar + ⌘+Enter |
Diferencia importante
Ctrl+Enter no ejecuta todo el contenido del editor. Solo ejecuta la sentencia donde esta tu cursor (cada sentencia termina con ;). Si tienes varias sentencias y quieres ejecutarlas todas de una vez, usa Alt+X. Esta diferencia es muy importante y la vas a usar constantemente en el curso.
Otras cosas utiles del editor:
- Puedes tener multiples pestañas de SQL abiertas al mismo tiempo (como pestañas de un navegador).
- Asegurate siempre de que el editor esta conectado a la base de datos correcta — verifica el selector de conexion/base de datos en la barra superior del editor. Si estas conectado a
postgrespero quieres trabajar contienda, cambialo ahi.
Data Editor: ver y editar datos de una tabla
Cuando haces doble click en una tabla en el Navigator y seleccionas la pestaña Data, se abre el Data Editor. Es una grilla interactiva (como una planilla de calculo) que muestra los datos de la tabla.
Que puedes hacer:
- Ver datos en formato de tabla (Grid), texto plano (Text) o registro individual (Record)
- Filtrar usando la barra de filtro en la parte superior — escribe condiciones SQL como
precio > 100 - Ordenar haciendo click en el encabezado de una columna
- Editar datos directamente: haz click en una celda, modifica el valor, y luego click en el boton Save de la toolbar inferior para guardar los cambios
- Agregar o eliminar filas usando los botones de la toolbar inferior
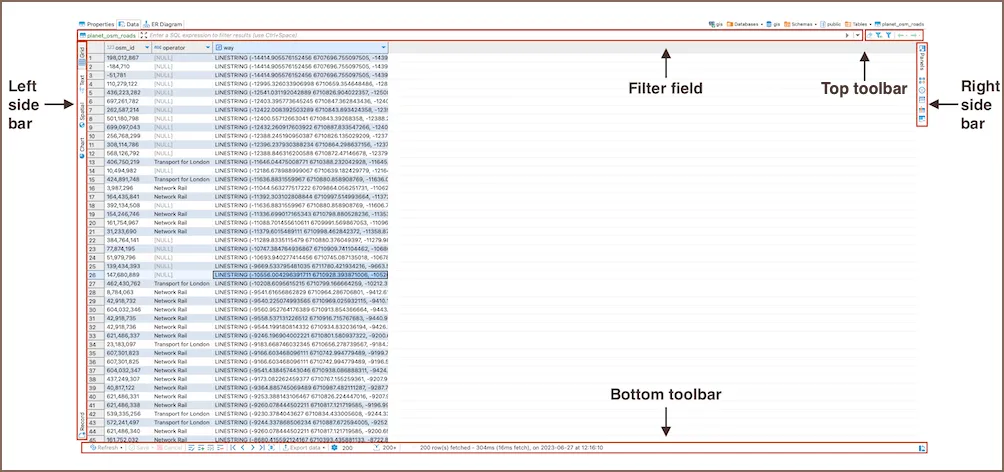
Cuidado al editar datos
Los cambios en el Data Editor se aplican directamente a la base de datos al hacer click en Save. Para tablas de practica esto esta bien, pero ten cuidado en entornos reales.
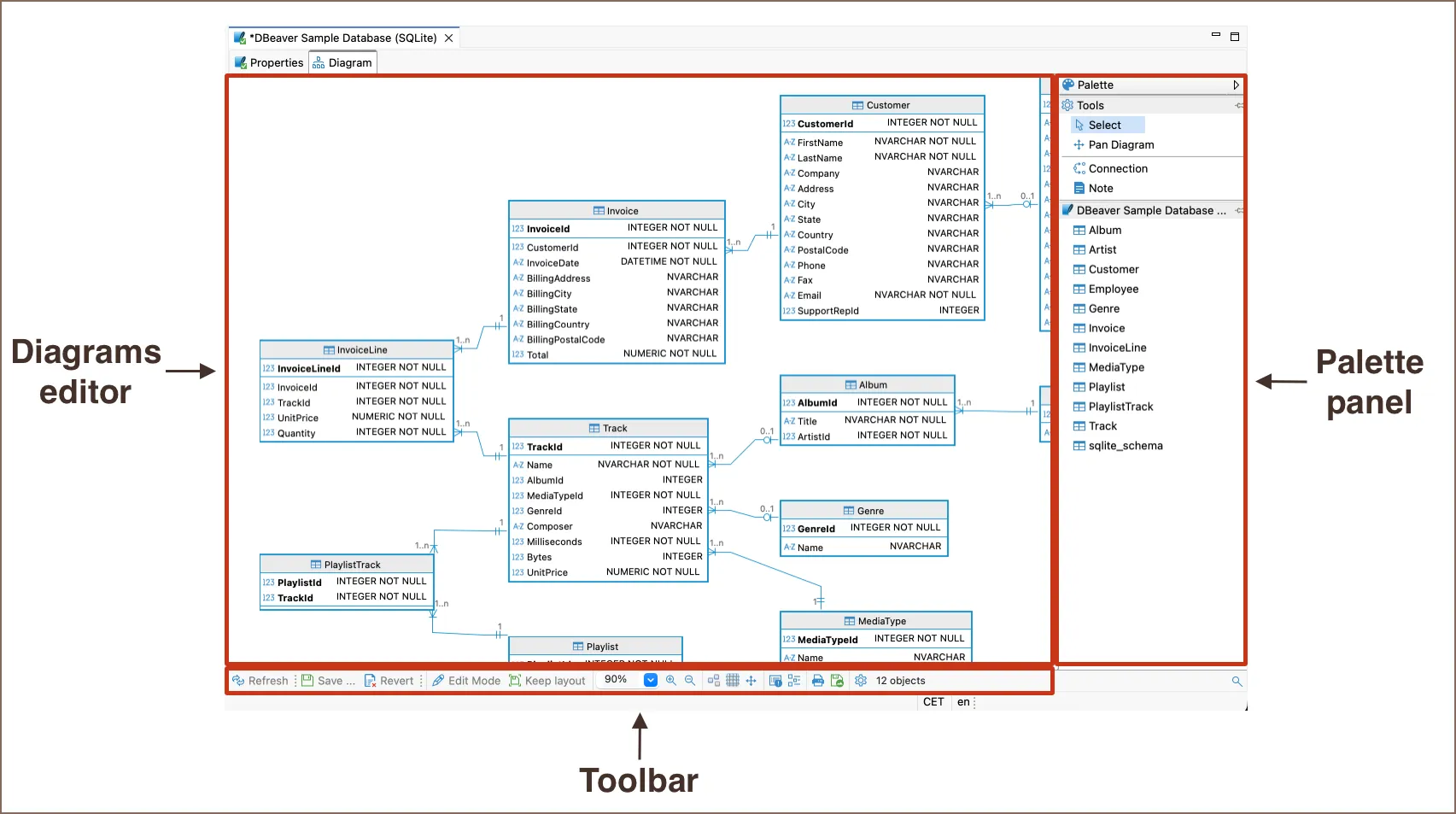
Diagramas ER: ver las relaciones entre tablas
DBeaver puede generar diagramas de entidad-relacion automaticamente, lo que te permite ver graficamente como se relacionan las tablas. Esto es muy util para entender la estructura de una base de datos.
Como verlos:
- En el Navigator, haz doble click en el schema public (o en el nodo Tables) → se abre una pestaña con el diagrama completo
- Tambien puedes ver el diagrama de una tabla individual: doble click en la tabla → pestaña Diagram
El diagrama muestra:
- Las tablas como cajas con sus columnas y tipos de datos
- Las relaciones como lineas entre tablas. Estas lineas representan las conexiones entre tablas (por ejemplo, que un pedido pertenece a un cliente)
- La direccion de las relaciones (uno-a-muchos, etc.)
Acciones utiles:
- Auto-arrange: reorganiza las tablas automaticamente para mejor legibilidad
- Zoom: acerca o aleja el diagrama
- Cambiar notacion: click derecho → Notation para cambiar el estilo visual de las relaciones
- Exportar como imagen: click derecho → Save as Image para guardar el diagrama como PNG, SVG u otro formato
Resumen de atajos de DBeaver
Estos son los atajos que mas vas a usar en el curso. No necesitas memorizarlos ahora, pero tenlos a mano:
| Accion | Windows/Linux | macOS |
|---|---|---|
| Nueva conexion | Ctrl+Shift+N | Ctrl+Shift+N |
| Nuevo SQL Editor | Ctrl+] | ⌃] |
| Ejecutar sentencia | Ctrl+Enter | ⌘+Enter |
| Ejecutar script completo | Alt+X | ⌥+X |
Para mas detalles sobre todas las funcionalidades de DBeaver, consulta la documentacion oficial.
Paso 5: Crear la base de datos de practica
Ahora que ya conoces DBeaver, vamos a crear la base de datos que usaremos durante todo el curso. Es la base de datos de una tienda ficticia con 5 tablas que simulan un sistema real de pedidos:
- productos: los articulos que vende la tienda
- clientes: las personas que compran
- pedidos: cada compra realizada
- detalle_pedidos: los productos dentro de cada pedido
- empleados: el equipo de la tienda (con jerarquia de jefes)
Diagrama de relaciones
Las tablas no estan aisladas: se conectan entre si. Por ejemplo, un pedido necesita saber a que cliente pertenece. Esa conexion se llama relacion y es fundamental en bases de datos.
clientes ──< pedidos ──< detalle_pedidos >── productosempleados (jefe_id -> empleados.id)El simbolo ──< significa “uno a muchos”: un cliente puede tener muchos pedidos, pero cada pedido pertenece a un solo cliente. Cada pedido puede tener muchos detalles, y cada detalle referencia a un producto. Los empleados pueden tener un jefe que tambien es empleado.
No te preocupes si esto no queda claro ahora. Lo vas a entender completamente cuando lleguemos al modulo de JOINs (modulo 7).
Paso 5.1: Crear la base de datos tienda
- En el Database Navigator (panel izquierdo), expande tu conexion haciendo click en la flecha junto a ella
- Haz click derecho sobre el nodo Databases → Create New Database
- Escribe
tiendacomo nombre y click en OK - Doble click en
tiendapara conectarte a ella
Paso 5.2: Crear las tablas
- Abre un nuevo editor SQL: en el menu superior haz click en SQL Editor y luego en New SQL Editor (o usa el atajo
Ctrl+]) - Verifica que en la barra superior del editor aparezca tienda como base de datos activa. Si aparece otra (como
postgres), haz click en el selector y cambiala atienda. - Copia todo el codigo SQL de abajo (selecciona todo con
Ctrl+A, luegoCtrl+C) y pegalo en el editor (Ctrl+V). En macOS usa⌘en lugar deCtrl.
No te preocupes por entender este SQL todavia
El codigo de abajo crea las tablas de la base de datos. Usa palabras como SERIAL, VARCHAR o REFERENCES que quizas no conoces. Eso es completamente normal. En los siguientes modulos vas a aprender que significa cada una. Por ahora, solo necesitas copiarlo, pegarlo y ejecutarlo.
CREATE TABLE productos ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, precio DECIMAL(10,2) NOT NULL, categoria VARCHAR(50), stock INTEGER DEFAULT 0, fecha_creacion DATE DEFAULT CURRENT_DATE);
CREATE TABLE clientes ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, email VARCHAR(100) UNIQUE, ciudad VARCHAR(50), fecha_registro DATE DEFAULT CURRENT_DATE);
CREATE TABLE pedidos ( id SERIAL PRIMARY KEY, cliente_id INTEGER REFERENCES clientes(id), fecha DATE DEFAULT CURRENT_DATE, total DECIMAL(10,2), estado VARCHAR(20) DEFAULT 'pendiente');
CREATE TABLE detalle_pedidos ( id SERIAL PRIMARY KEY, pedido_id INTEGER REFERENCES pedidos(id), producto_id INTEGER REFERENCES productos(id), cantidad INTEGER NOT NULL, precio_unitario DECIMAL(10,2) NOT NULL);
CREATE TABLE empleados ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, departamento VARCHAR(50), salario DECIMAL(10,2), fecha_contratacion DATE DEFAULT CURRENT_DATE, jefe_id INTEGER REFERENCES empleados(id));- Ejecuta todo el script presionando
Alt+X(macOS:⌥+X). Esto crea las 5 tablas de una sola vez.
Como saber si funciono?
Si todo salio bien, vas a ver mensajes de confirmacion en el panel de resultados (abajo). Luego, en el Database Navigator, expande tienda → Schemas → public → Tables y deberias ver las 5 tablas creadas. Si no aparecen, haz click derecho en Tables → Refresh.
Paso 5.3: Insertar los datos de prueba
Las tablas estan creadas pero vacias. Ahora vamos a llenarlas con datos de ejemplo para poder practicar durante todo el curso.
- Abre una nueva pestaña de SQL Editor (
Ctrl+]). Tambien puedes usar la misma pestaña si borras el contenido anterior. - Copia todo el codigo SQL de abajo (
Ctrl+Apara seleccionar,Ctrl+Cpara copiar) y pegalo en el editor (Ctrl+V):
INSERT INTO productos (nombre, precio, categoria, stock) VALUES('Laptop Pro 15', 1299.99, 'Electronica', 45),('Mouse Inalambrico', 29.99, 'Electronica', 150),('Teclado Mecanico', 89.99, 'Electronica', 80),('Monitor 27 pulgadas', 449.99, 'Electronica', 30),('Auriculares Bluetooth', 59.99, 'Electronica', 200),('Escritorio Ajustable', 399.99, 'Muebles', 25),('Silla Ergonomica', 299.99, 'Muebles', 40),('Lampara LED', 34.99, 'Muebles', 100),('Mochila para Laptop', 49.99, 'Accesorios', 120),('Hub USB-C', 39.99, 'Accesorios', 90),('Webcam HD', 79.99, 'Electronica', 60),('Cable HDMI 2m', 12.99, 'Accesorios', 300),('Soporte Monitor', 44.99, 'Muebles', 55),('Mousepad XL', 19.99, 'Accesorios', 180),('Cargador Rapido', 24.99, 'Accesorios', 250);
INSERT INTO clientes (nombre, email, ciudad) VALUES('Maria Garcia', 'maria@email.com', 'Santiago'),('Carlos Lopez', 'carlos@email.com', 'Valparaiso'),('Ana Martinez', 'ana@email.com', 'Santiago'),('Pedro Sanchez', 'pedro@email.com', 'Concepcion'),('Laura Torres', 'laura@email.com', 'Santiago'),('Diego Rivera', 'diego@email.com', 'Valparaiso'),('Carmen Ruiz', 'carmen@email.com', 'Temuco'),('Roberto Diaz', 'roberto@email.com', 'Santiago'),('Isabel Moreno', 'isabel@email.com', 'Antofagasta'),('Andres Vargas', 'andres@email.com', 'Concepcion');
INSERT INTO pedidos (cliente_id, fecha, total, estado) VALUES(1, '2024-01-15', 1389.98, 'completado'),(2, '2024-01-20', 89.99, 'completado'),(3, '2024-02-01', 499.98, 'completado'),(1, '2024-02-14', 59.99, 'completado'),(4, '2024-02-28', 1749.98, 'enviado'),(5, '2024-03-05', 149.97, 'completado'),(6, '2024-03-10', 299.99, 'pendiente'),(3, '2024-03-15', 839.98, 'enviado'),(7, '2024-03-20', 34.99, 'completado'),(8, '2024-03-25', 479.98, 'pendiente'),(2, '2024-04-01', 129.98, 'completado'),(9, '2024-04-05', 1299.99, 'enviado'),(10, '2024-04-10', 69.98, 'pendiente'),(1, '2024-04-15', 449.99, 'completado'),(5, '2024-04-20', 89.99, 'completado');
INSERT INTO detalle_pedidos (pedido_id, producto_id, cantidad, precio_unitario) VALUES(1, 1, 1, 1299.99),(1, 2, 3, 29.99),(2, 3, 1, 89.99),(3, 7, 1, 299.99),(3, 8, 2, 34.99),(3, 14, 1, 19.99),(4, 5, 1, 59.99),(5, 1, 1, 1299.99),(5, 4, 1, 449.99),(6, 9, 3, 49.99),(7, 7, 1, 299.99),(8, 4, 1, 449.99),(8, 10, 2, 39.99),(8, 3, 1, 89.99),(9, 8, 1, 34.99),(10, 11, 1, 79.99),(10, 6, 1, 399.99),(11, 2, 1, 29.99),(11, 14, 5, 19.99),(12, 1, 1, 1299.99),(13, 12, 2, 12.99),(13, 15, 1, 24.99),(14, 4, 1, 449.99),(15, 3, 1, 89.99);
INSERT INTO empleados (nombre, departamento, salario, fecha_contratacion, jefe_id) VALUES('Sofia Mendez', 'Gerencia', 85000, '2020-01-15', NULL),('Juan Perez', 'Ventas', 45000, '2021-03-01', 1),('Valentina Castro', 'Ventas', 42000, '2021-06-15', 1),('Miguel Angel Torres', 'Tecnologia', 62000, '2020-08-01', 1),('Camila Rojas', 'Tecnologia', 55000, '2022-01-10', 4),('Alejandro Vega', 'Tecnologia', 58000, '2021-11-20', 4),('Fernanda Luna', 'Ventas', 40000, '2023-02-01', 2),('Ricardo Soto', 'Soporte', 38000, '2022-07-15', 4),('Patricia Herrera', 'Soporte', 36000, '2023-05-01', 8),('Daniela Flores', 'Ventas', 41000, '2023-08-10', 2);- Ejecuta todo con
Alt+X(macOS:⌥+X).
Atajo: usa el script del repositorio
Si clonaste el repositorio del curso, el script completo esta en db/init.sql. Puedes abrirlo directamente en DBeaver con File → Open File y ejecutarlo con Alt+X (macOS: ⌥+X). Es mas rapido que copiar y pegar.
Paso 5.4: Verificar que todo funciona
Vamos a confirmar que los datos se cargaron correctamente. En el mismo editor SQL (o en una nueva pestaña), copia y pega estas consultas:
SELECT COUNT(*) FROM productos; -- Deberia devolver: 15SELECT COUNT(*) FROM clientes; -- Deberia devolver: 10SELECT COUNT(*) FROM pedidos; -- Deberia devolver: 15SELECT COUNT(*) FROM detalle_pedidos; -- Deberia devolver: 24SELECT COUNT(*) FROM empleados; -- Deberia devolver: 10Para ejecutarlas, tienes dos opciones:
- Todas a la vez: presiona
Alt+Xpara ejecutar todo el script. Los resultados de cada consulta apareceran en pestañas separadas en el panel inferior. - Una por una: pon el cursor en la linea de la consulta que quieres ejecutar y presiona
Ctrl+Enter. Esto es util para ir verificando tabla por tabla.
Si todos los numeros coinciden, tu base de datos esta lista.
Verificacion visual
Tambien puedes verificar visualmente: en el Database Navigator, expande tienda → Schemas → public → Tables, haz doble click en cualquier tabla (por ejemplo, productos) y selecciona la pestaña Data. Deberias ver los datos en formato de grilla.
Playgrounds online: practica sin instalar nada
Si quieres un primer acercamiento a SQL antes de instalar software, existen playgrounds online donde puedes escribir y ejecutar consultas directamente en el navegador:
- aprendesql.dev/playground — Recomendado. Playground en español con soporte para PostgreSQL. Ideal para empezar a experimentar.
- sqlfiddle.com — Uno de los playgrounds mas conocidos. Soporta PostgreSQL y otros motores.
- db-fiddle.com — Similar a SQL Fiddle, con interfaz limpia y soporte para PostgreSQL.
Puedes copiar el SQL de creacion de tablas e insercion de datos de la seccion anterior, pegarlo en cualquiera de estos playgrounds y empezar a practicar de inmediato.
Limitaciones de los playgrounds
Los playgrounds son excelentes para practicar consultas basicas (SELECT, WHERE, JOINs, agregaciones), pero tienen limitaciones:
- No soportan todas las funcionalidades de PostgreSQL (transacciones, vistas materializadas, permisos, etc.)
- Las sesiones son temporales: los datos no se guardan entre visitas
- No puedes usar herramientas como
EXPLAIN ANALYZEo gestionar indices realmente
Para efectos profesionales y para cubrir todo el contenido del curso (especialmente los modulos avanzados), es necesario instalar PostgreSQL en tu maquina.
¿Que sigue?
Con el entorno listo y la base de datos cargada, en el proximo modulo vas a escribir tu primera consulta con SELECT. Vamos a explorar como pedirle datos a las tablas, eligiendo columnas, creando alias y haciendo calculos simples. ¡Vamos!
Ejercicios
Ejercicio 1: Verifica que tu entorno esta correctamente configurado. Abre un SQL Editor (Ctrl+]), asegurate de estar conectado a la base de datos tienda y ejecuta:
SELECT COUNT(*) FROM clientes;SELECT COUNT(*) FROM productos;SELECT COUNT(*) FROM pedidos;Ejecuta cada consulta poniendo el cursor en la linea y presionando Ctrl+Enter. ¿Cuantos registros tiene cada tabla?
Ejercicio 2: Ejecuta esta consulta y observa el resultado. No necesitas entenderla completamente aun, solo ejecutala con Ctrl+Enter:
SELECT nombre, precioFROM productosWHERE categoria = 'Electronica'ORDER BY precio DESC;¿Que crees que hace? Intenta describirlo con tus propias palabras.
Ejercicio 3: Modifica la consulta anterior cambiando 'Electronica' por 'Muebles'. ¿Que resultado obtienes?
Ejercicio 4: Usa el Database Navigator para explorar la base de datos. Expande tienda → Schemas → public → Tables y haz doble click en la tabla pedidos. Selecciona la pestaña Data. ¿Cuantas columnas tiene la tabla? ¿Que datos ves?
Ejercicio 5: Abre el diagrama ER de la base de datos. En el Navigator, haz doble click en Tables (el nodo que agrupa todas las tablas) y selecciona la pestaña Diagram. ¿Puedes identificar las relaciones entre las tablas? ¿Que tabla esta conectada con pedidos?
SELECT: Tu primera consulta
Prerequisito: base de datos de practica
Todos los ejemplos y ejercicios de este modulo (y los siguientes) se ejecutan sobre la base de datos tienda que creamos en el Modulo 2. Si aun no la tienes configurada, ve al Modulo 2 y sigue los pasos para crear las tablas y cargar los datos de ejemplo antes de continuar.
Tu primera consulta SQL
Llegamos al momento que estabas esperando: vas a hablar con la base de datos por primera vez. La instruccion mas fundamental de SQL es SELECT, y la vas a usar en absolutamente todo lo que hagas.
La forma mas basica de SELECT es:
SELECT columnasFROM tabla;Asi de simple. Le dices que columnas quieres y de que tabla. Probemos con nuestra base de datos:
SELECT nombre, precioFROM productos;Esta consulta devuelve el nombre y precio de todos los productos. El resultado se ve algo asi:
nombre | precio---------------------+--------- Laptop Pro 15 | 1299.99 Mouse Inalambrico | 29.99 Teclado Mecanico | 89.99 Monitor 27 pulgadas | 449.99 Auriculares Bluetooth| 59.99 ...Felicidades, acabas de hacer tu primera consulta SQL.
SELECT * vs columnas especificas
Existe un atajo para pedir todas las columnas de una tabla:
SELECT *FROM productos;El asterisco (*) significa “dame todas las columnas”. Es muy comodo para explorar datos rapidamente, pero tiene un problema importante en aplicaciones reales.
-- Esto trae TODAS las columnas: id, nombre, precio, categoria, stock, fecha_creacionSELECT *FROM productos;
-- Esto trae solo lo que necesitasSELECT nombre, precioFROM productos;¿Por que evitar SELECT * en produccion?
Cuando usas SELECT *, la base de datos tiene que leer y transferir todas las columnas de cada fila, incluso las que no necesitas. Si tu tabla tiene 20 columnas pero solo necesitas 3, estas transfiriendo casi 7 veces mas datos de los necesarios.
Piensalo asi: el trabajo por cada fila es proporcional al numero de columnas que pides. Si pides 3 columnas, es O(3) por fila. Si pides 20, es O(20) por fila. En una tabla con un millon de filas, esa diferencia se nota.
Ademas, SELECT * hace que tu codigo sea fragil: si alguien agrega una columna nueva a la tabla, tu consulta de repente devuelve datos que no esperabas.
¿Cuando si usar SELECT *?
Usa SELECT * libremente cuando estes explorando datos, aprendiendo la estructura de una tabla, o haciendo consultas rapidas en desarrollo. La recomendacion de evitarlo aplica sobre todo a consultas en aplicaciones en produccion.
Seleccionando columnas especificas
Puedes pedir una, dos o todas las columnas que quieras. El orden en que las pides es el orden en que aparecen en el resultado:
-- Solo el nombreSELECT nombreFROM clientes;
-- Nombre y ciudad (en ese orden)SELECT nombre, ciudadFROM clientes;
-- Ciudad primero, luego nombre (cambio de orden)SELECT ciudad, nombreFROM clientes;
-- Varias columnas de empleadosSELECT nombre, departamento, salarioFROM empleados;Observa que en el tercer ejemplo, la ciudad aparece antes que el nombre en el resultado. Tu controlas el orden de las columnas en la salida.
Alias de columnas con AS
A veces los nombres de las columnas no son muy descriptivos o quieres darles un nombre mas claro en el resultado. Para eso usamos AS:
SELECT nombre AS producto, precio AS precio_unitarioFROM productos;Resultado:
producto | precio_unitario----------------------+---------------- Laptop Pro 15 | 1299.99 Mouse Inalambrico | 29.99 Teclado Mecanico | 89.99 ...Los alias son especialmente utiles cuando haces calculos o cuando el nombre original de la columna no es claro:
SELECT nombre AS empleado, departamento AS area, salario AS sueldo_mensualFROM empleados;AS es opcional (pero usalo)
Tecnicamente puedes omitir la palabra AS y simplemente poner el alias:
SELECT nombre producto, precio costo FROM productos;Funciona, pero es mucho menos legible. Recomiendo siempre usar AS para que sea claro que estas creando un alias.
Alias con espacios
Si necesitas un alias con espacios, usa comillas dobles:
SELECT nombre AS "Nombre del Producto", precio AS "Precio en USD"FROM productos;DISTINCT: eliminando duplicados
Si una consulta devuelve valores repetidos y quieres ver solo los valores unicos, usa DISTINCT:
-- Sin DISTINCT: puede repetir ciudadesSELECT ciudadFROM clientes; ciudad----------- Santiago Valparaiso Santiago Concepcion Santiago Valparaiso Temuco Santiago Antofagasta Concepcion-- Con DISTINCT: cada ciudad aparece una sola vezSELECT DISTINCT ciudadFROM clientes; ciudad----------- Santiago Valparaiso Concepcion Temuco AntofagastaPuedes usar DISTINCT con multiples columnas. En ese caso, elimina filas donde la combinacion de columnas sea duplicada:
-- Combinaciones unicas de departamento y jefe_idSELECT DISTINCT departamento, jefe_idFROM empleados;Esto devuelve cada combinacion unica de departamento y jefe, no cada departamento unico y cada jefe unico por separado.
-- ¿Que categorias de productos tenemos?SELECT DISTINCT categoriaFROM productos; categoria------------ Electronica Muebles Accesorios-- ¿En que estados pueden estar los pedidos?SELECT DISTINCT estadoFROM pedidos; estado----------- completado enviado pendienteCosto de DISTINCT
DISTINCT no es gratis. Para eliminar duplicados, la base de datos necesita ordenar o agrupar todos los resultados y luego compararlos entre si. En tablas grandes esto puede ser costoso. Usalo cuando realmente necesites valores unicos, no “por si acaso”.
Expresiones y calculos en SELECT
SELECT no solo sirve para leer columnas tal cual estan. Puedes hacer calculos directamente en la consulta:
Aritmetica
-- Precio con IVA (19%)SELECT nombre, precio, precio * 1.19 AS precio_con_ivaFROM productos; nombre | precio | precio_con_iva---------------------+----------+--------------- Laptop Pro 15 | 1299.99 | 1547.39 Mouse Inalambrico | 29.99 | 35.69 Teclado Mecanico | 89.99 | 107.09 ...-- Valor total del inventario por productoSELECT nombre, precio, stock, precio * stock AS valor_inventarioFROM productos;-- Salario anual de empleados (asumiendo 12 meses)SELECT nombre, salario AS salario_mensual, salario * 12 AS salario_anualFROM empleados;-- Descuento del 10% en productosSELECT nombre, precio AS precio_original, precio * 0.10 AS descuento, precio * 0.90 AS precio_finalFROM productos;Concatenacion de texto
En PostgreSQL, usamos el operador || para unir texto:
SELECT nombre || ' - ' || ciudad AS cliente_infoFROM clientes; cliente_info---------------------------- Maria Garcia - Santiago Carlos Lopez - Valparaiso Ana Martinez - Santiago ...-- Descripcion del producto con precioSELECT nombre || ' ($' || precio || ')' AS descripcionFROM productos; descripcion----------------------------- Laptop Pro 15 ($1299.99) Mouse Inalambrico ($29.99) Teclado Mecanico ($89.99) ...Valores literales
Puedes incluir valores fijos (literales) en tu SELECT:
SELECT nombre, precio, 'CLP' AS moneda, 2024 AS anioFROM productos;Cada fila tendra las columnas moneda con el valor ‘CLP’ y anio con el valor 2024. Esto puede parecer inutil ahora, pero es muy practico cuando combinas datos de distintas fuentes.
SELECT sin FROM
Dato curioso: en PostgreSQL puedes usar SELECT sin una tabla, como una calculadora:
SELECT 2 + 2;-- Resultado: 4
SELECT 100 * 1.19 AS con_iva;-- Resultado: 119.00
SELECT 'Hola' || ' ' || 'Mundo' AS saludo;-- Resultado: Hola Mundo
SELECT NOW() AS fecha_actual;-- Resultado: 2024-04-20 15:30:00 (la fecha y hora actual)Es util para probar expresiones rapidamente sin necesidad de consultar una tabla.
El orden de escritura vs. el orden de ejecucion
Este es un concepto que te va a ahorrar muchos dolores de cabeza. El orden en que escribes una consulta SQL no es el orden en que la base de datos la ejecuta.
Tu escribes:
SELECT columnas -- 1° en escribirFROM tabla -- 2° en escribirWHERE condicion -- 3° en escribirPero la base de datos ejecuta:
FROM tabla -- 1° en ejecutar (primero encuentra la tabla)WHERE condicion -- 2° en ejecutar (luego filtra filas)SELECT columnas -- 3° en ejecutar (al final elige columnas)¿Por que importa esto?
Esto explica, por ejemplo, por que no puedes usar un alias definido en SELECT dentro del WHERE: cuando el WHERE se ejecuta, el SELECT todavia no ha corrido.
-- Esto NO funciona:SELECT precio * 1.19 AS precio_con_ivaFROM productosWHERE precio_con_iva > 100; -- Error: precio_con_iva no existe aun
-- Esto SI funciona:SELECT precio * 1.19 AS precio_con_ivaFROM productosWHERE precio * 1.19 > 100; -- Repites la expresionEn modulos posteriores veremos el orden completo de ejecucion cuando agreguemos mas clausulas.
Buenas practicas al escribir SELECT
Antes de pasar a los ejercicios, algunas recomendaciones:
-- MAL: todo en una linea, dificil de leerSELECT nombre,precio,stock,precio*stock AS total FROM productos;
-- BIEN: cada columna en su linea, con indentacion claraSELECT nombre, precio, stock, precio * stock AS totalFROM productos;-- MAL: columnas ambiguas, sin aliasSELECT nombre, precio * 1.19, stock * precioFROM productos;
-- BIEN: alias descriptivos para cada calculoSELECT nombre, precio * 1.19 AS precio_con_iva, stock * precio AS valor_inventarioFROM productos;SQL no distingue mayusculas
Las palabras clave de SQL (SELECT, FROM, WHERE, etc.) funcionan en mayusculas o minusculas. select, SELECT y Select son lo mismo. La convencion mas comun es escribir las palabras clave en MAYUSCULAS para distinguirlas de los nombres de tablas y columnas. En este curso usamos esa convencion.
Ejercicios
Ejercicio 1: Escribe una consulta que muestre el nombre y la categoria de todos los productos.
Ver solucion
SELECT nombre, categoriaFROM productos;Ejercicio 2: Muestra el nombre de cada producto junto con su precio con IVA (19%) y ponle un alias descriptivo a la nueva columna.
Ver solucion
SELECT nombre, precio, precio * 1.19 AS precio_con_ivaFROM productos;Ejercicio 3: Obtener una lista de todas las ciudades unicas donde tenemos clientes.
Ver solucion
SELECT DISTINCT ciudadFROM clientes;Ejercicio 4: Muestra el nombre completo de cada cliente concatenado con su email entre parentesis. Por ejemplo: “Maria Garcia (maria@email.com)”. Usa un alias llamado contacto.
Ver solucion
SELECT nombre || ' (' || email || ')' AS contactoFROM clientes;Ejercicio 5: Para cada producto, muestra su nombre, stock actual, precio y el valor total del inventario (stock multiplicado por precio). Usa alias descriptivos.
Ver solucion
SELECT nombre, stock AS unidades_disponibles, precio AS precio_unitario, stock * precio AS valor_total_inventarioFROM productos;Ejercicio 6: Obtener los departamentos unicos de la tabla empleados. ¿Cuantos departamentos distintos hay?
Ver solucion
SELECT DISTINCT departamentoFROM empleados;-- Resultado: Gerencia, Ventas, Tecnologia, Soporte (4 departamentos)Ejercicio 7: Muestra el nombre de cada empleado, su salario mensual y su salario anual (12 meses). Ademas agrega una columna literal que diga ‘CLP’ como moneda.
Ver solucion
SELECT nombre, salario AS salario_mensual, salario * 12 AS salario_anual, 'CLP' AS monedaFROM empleados;Ejercicio 8 (desafio): Sin ejecutar la consulta, ¿esta consulta va a funcionar? ¿Por que si o por que no?
SELECT nombre, precio * stock AS valorFROM productosWHERE valor > 1000;Ver solucion
No funciona. El alias valor se define en el SELECT, pero el WHERE se ejecuta antes que el SELECT. La base de datos no conoce el alias valor cuando evalua el WHERE. La forma correcta seria:
SELECT nombre, precio * stock AS valorFROM productosWHERE precio * stock > 1000;WHERE: Filtrando datos
Filtrando datos con WHERE
En el modulo anterior aprendimos a pedir columnas con SELECT. Pero SELECT sin WHERE es como ir al supermercado y traer todo lo que hay en la tienda. En la vida real, casi siempre quieres solo una parte de los datos.
La clausula WHERE te permite filtrar filas segun condiciones:
SELECT nombre, precioFROM productosWHERE categoria = 'Electronica';Esta consulta dice: “dame el nombre y precio de los productos, pero solo los que tienen categoria Electronica”. El resultado:
nombre | precio-----------------------+--------- Laptop Pro 15 | 1299.99 Mouse Inalambrico | 29.99 Teclado Mecanico | 89.99 Monitor 27 pulgadas | 449.99 Auriculares Bluetooth | 59.99 Webcam HD | 79.99De los 15 productos en la tabla, solo 6 cumplen la condicion. El WHERE descarto los otros 9 antes de que llegaran al resultado.
WHERE: tu mejor aliado en rendimiento
WHERE es probablemente la clausula mas importante para el rendimiento de tus consultas. Filtrar filas temprano significa que el resto de la consulta (ordenar, agrupar, calcular) trabaja con menos datos. Si tu tabla tiene un millon de filas y el WHERE las reduce a 100, todo lo demas es 10,000 veces mas rapido. Siempre filtra lo mas posible, lo antes posible.
Operadores de comparacion
Los operadores basicos de comparacion son los que ya conoces de matematicas:
-- Igual aSELECT nombre, precioFROM productosWHERE precio = 29.99;
-- Diferente de (no igual)SELECT nombre, estadoFROM pedidosWHERE estado <> 'completado';
-- Mayor queSELECT nombre, precioFROM productosWHERE precio > 100;
-- Menor queSELECT nombre, salarioFROM empleadosWHERE salario < 45000;
-- Mayor o igual queSELECT nombre, stockFROM productosWHERE stock >= 100;
-- Menor o igual queSELECT nombre, precioFROM productosWHERE precio <= 50;Veamos un ejemplo mas detallado. Queremos los productos que cuestan mas de $100:
SELECT nombre, precio, categoriaFROM productosWHERE precio > 100; nombre | precio | categoria-----------------------+----------+------------ Laptop Pro 15 | 1299.99 | Electronica Monitor 27 pulgadas | 449.99 | Electronica Escritorio Ajustable | 399.99 | Muebles Silla Ergonomica | 299.99 | MueblesLos operadores de comparacion tambien funcionan con texto y fechas:
-- Clientes registrados despues de una fechaSELECT nombre, fecha_registroFROM clientesWHERE fecha_registro > '2024-01-01';
-- Pedidos con total exactoSELECT id, total, estadoFROM pedidosWHERE total = 89.99;
-- Empleados que NO son del departamento de VentasSELECT nombre, departamentoFROM empleadosWHERE departamento <> 'Ventas';Comparacion de texto
Cuando comparas texto con =, la comparacion es exacta. 'Santiago' no es igual a 'santiago' ni a 'Santiago ' (con un espacio extra). Mas adelante veremos ILIKE para busquedas mas flexibles.
Operadores logicos: AND, OR, NOT
¿Que pasa si necesitas combinar varias condiciones? Usas los operadores logicos.
AND: ambas condiciones deben cumplirse
-- Productos de Electronica que cuesten menos de $100SELECT nombre, precio, categoriaFROM productosWHERE categoria = 'Electronica' AND precio < 100; nombre | precio | categoria-----------------------+--------+------------ Mouse Inalambrico | 29.99 | Electronica Teclado Mecanico | 89.99 | Electronica Auriculares Bluetooth | 59.99 | Electronica Webcam HD | 79.99 | ElectronicaAmbas condiciones deben ser verdaderas: el producto tiene que ser de Electronica y costar menos de 100.
-- Empleados de Tecnologia con salario mayor a 55000SELECT nombre, departamento, salarioFROM empleadosWHERE departamento = 'Tecnologia' AND salario > 55000; nombre | departamento | salario---------------------+--------------+--------- Miguel Angel Torres | Tecnologia | 62000 Alejandro Vega | Tecnologia | 58000OR: al menos una condicion debe cumplirse
-- Productos que sean de Electronica O de MueblesSELECT nombre, precio, categoriaFROM productosWHERE categoria = 'Electronica' OR categoria = 'Muebles';Esto devuelve los productos que cumplan cualquiera de las dos condiciones: si es de Electronica, entra. Si es de Muebles, tambien entra.
-- Pedidos que esten pendientes o enviadosSELECT id, fecha, total, estadoFROM pedidosWHERE estado = 'pendiente' OR estado = 'enviado'; id | fecha | total | estado----+------------+---------+----------- 5 | 2024-02-28 | 1749.98 | enviado 7 | 2024-03-10 | 299.99 | pendiente 8 | 2024-03-15 | 839.98 | enviado 10 | 2024-03-25 | 479.98 | pendiente 12 | 2024-04-05 | 1299.99 | enviado 13 | 2024-04-10 | 69.98 | pendienteNOT: invierte la condicion
-- Productos que NO son de ElectronicaSELECT nombre, categoriaFROM productosWHERE NOT categoria = 'Electronica';-- Equivalente a: WHERE categoria <> 'Electronica'NOT es mas util cuando lo combinas con otros operadores como IN, BETWEEN o LIKE, que veremos en un momento.
Precedencia: AND antes que OR
Aqui viene un error clasico que atrapa a muchos principiantes. AND tiene mayor precedencia que OR, igual que la multiplicacion tiene mayor precedencia que la suma en matematicas.
-- CUIDADO: ¿que hace realmente esta consulta?SELECT nombre, precio, categoriaFROM productosWHERE categoria = 'Electronica' OR categoria = 'Muebles' AND precio < 50;Esto NO dice “productos de Electronica o Muebles que cuesten menos de 50”. Lo que realmente dice es:
-- Asi lo interpreta la base de datos:WHERE categoria = 'Electronica' OR (categoria = 'Muebles' AND precio < 50)Es decir: “dame TODOS los de Electronica (sin importar precio) O los de Muebles que cuesten menos de 50”. El AND se evalua primero y solo se aplica a Muebles.
La solucion: usa parentesis para ser explicito:
-- Esto SI hace lo que quieres:SELECT nombre, precio, categoriaFROM productosWHERE (categoria = 'Electronica' OR categoria = 'Muebles') AND precio < 50; nombre | precio | categoria-------------------+--------+------------ Mouse Inalambrico | 29.99 | Electronica Lampara LED | 34.99 | Muebles Soporte Monitor | 44.99 | MueblesSiempre usa parentesis
Cuando combines AND y OR en la misma consulta, siempre usa parentesis. Incluso si recuerdas las reglas de precedencia, los parentesis hacen que tu intencion sea clara para cualquier persona que lea la consulta (incluyendo tu yo del futuro).
BETWEEN: rangos de valores
BETWEEN es un atajo elegante para filtrar por un rango (incluyendo los extremos):
-- Productos entre $30 y $100 (incluye 30 y 100)SELECT nombre, precioFROM productosWHERE precio BETWEEN 30 AND 100; nombre | precio-----------------------+-------- Teclado Mecanico | 89.99 Auriculares Bluetooth | 59.99 Lampara LED | 34.99 Mochila para Laptop | 49.99 Hub USB-C | 39.99 Webcam HD | 79.99 Soporte Monitor | 44.99Es equivalente a escribir:
WHERE precio >= 30 AND precio <= 100Pero BETWEEN es mas legible. Funciona tambien con fechas:
-- Pedidos realizados en febrero 2024SELECT id, cliente_id, fecha, totalFROM pedidosWHERE fecha BETWEEN '2024-02-01' AND '2024-02-28'; id | cliente_id | fecha | total----+------------+------------+--------- 3 | 3 | 2024-02-01 | 499.98 4 | 1 | 2024-02-14 | 59.99 5 | 4 | 2024-02-28 | 1749.98-- Empleados con salario entre 40000 y 60000SELECT nombre, departamento, salarioFROM empleadosWHERE salario BETWEEN 40000 AND 60000;Y puedes invertirlo con NOT:
-- Productos que NO cuestan entre 30 y 100SELECT nombre, precioFROM productosWHERE precio NOT BETWEEN 30 AND 100;BETWEEN incluye los extremos
BETWEEN 30 AND 100 incluye tanto 30 como 100. Si necesitas excluir los extremos, usa operadores de comparacion: WHERE precio > 30 AND precio < 100.
IN: listas de valores
Cuando necesitas comparar contra varios valores posibles, IN es mucho mas limpio que encadenar varios OR:
-- Sin IN (funciona pero es verboso)SELECT nombre, ciudadFROM clientesWHERE ciudad = 'Santiago' OR ciudad = 'Valparaiso' OR ciudad = 'Concepcion';
-- Con IN (mismo resultado, mucho mas limpio)SELECT nombre, ciudadFROM clientesWHERE ciudad IN ('Santiago', 'Valparaiso', 'Concepcion'); nombre | ciudad-----------------+------------ Maria Garcia | Santiago Carlos Lopez | Valparaiso Ana Martinez | Santiago Pedro Sanchez | Concepcion Laura Torres | Santiago Diego Rivera | Valparaiso Roberto Diaz | Santiago Andres Vargas | ConcepcionIN funciona con cualquier tipo de dato:
-- Productos de ciertas categoriasSELECT nombre, categoria, precioFROM productosWHERE categoria IN ('Electronica', 'Accesorios');
-- Pedidos especificos por IDSELECT id, total, estadoFROM pedidosWHERE id IN (1, 5, 10, 15);
-- Pedidos que no estan completados ni enviadosSELECT id, total, estadoFROM pedidosWHERE estado NOT IN ('completado', 'enviado');IN vs OR: mismo resultado
WHERE ciudad IN ('Santiago', 'Valparaiso') produce exactamente el mismo resultado que WHERE ciudad = 'Santiago' OR ciudad = 'Valparaiso'. Internamente PostgreSQL puede incluso convertir uno al otro. La ventaja de IN es puramente de legibilidad, especialmente con listas largas.
LIKE e ILIKE: busqueda por patrones
A veces no sabes el valor exacto que buscas. LIKE te permite buscar usando patrones con dos caracteres especiales:
%representa cualquier cantidad de caracteres (cero o mas)_representa exactamente un caracter
-- Productos cuyo nombre empieza con "M"SELECT nombreFROM productosWHERE nombre LIKE 'M%'; nombre------------------- Mouse Inalambrico Monitor 27 pulgadas Mochila para Laptop Mousepad XL-- Productos cuyo nombre termina en "o"SELECT nombreFROM productosWHERE nombre LIKE '%o'; nombre------------------- Mouse Inalambrico Teclado Mecanico-- Productos que contienen "USB" en el nombreSELECT nombreFROM productosWHERE nombre LIKE '%USB%'; nombre----------- Hub USB-C-- Emails que contienen un texto especificoSELECT nombre, emailFROM clientesWHERE email LIKE '%@email.com';El guion bajo (_) es para un solo caracter:
-- Nombres de exactamente 4 letras (patron: 4 guiones bajos)-- Esto buscaria nombres de exactamente 4 caracteresSELECT nombreFROM clientesWHERE nombre LIKE '____';ILIKE: busqueda sin importar mayusculas/minusculas
LIKE es sensible a mayusculas. Si buscas LIKE 'laptop%', no encontrara “Laptop Pro 15”. Para buscar sin distinguir mayusculas, PostgreSQL tiene ILIKE:
-- LIKE: sensible a mayusculas (no encuentra nada)SELECT nombreFROM productosWHERE nombre LIKE 'laptop%';-- Resultado: 0 filas
-- ILIKE: ignora mayusculas/minusculasSELECT nombreFROM productosWHERE nombre ILIKE 'laptop%';-- Resultado: Laptop Pro 15-- Buscar clientes cuyo nombre contiene "garcia" (sin importar mayusculas)SELECT nombre, emailFROM clientesWHERE nombre ILIKE '%garcia%'; nombre | email---------------+---------------- Maria Garcia | maria@email.comILIKE es exclusivo de PostgreSQL
ILIKE no existe en el estandar SQL ni en otros motores como MySQL o SQL Server. Es una extension de PostgreSQL. En otros motores se logra de forma distinta (por ejemplo, MySQL compara texto sin distinguir mayusculas por defecto).
LIKE y el uso de indices
Cuando usas LIKE con un patron que empieza con % (como '%laptop%'), la base de datos no puede usar un indice y tiene que revisar todas las filas de la tabla. Esto es lo que llamamos un full table scan.
En cambio, si el patron empieza con texto fijo (como 'Laptop%'), PostgreSQL puede usar un indice para saltar directamente a las filas que empiezan con “Laptop”, lo cual es mucho mas rapido.
Regla general: LIKE 'texto%' puede ser rapido con un indice. LIKE '%texto%' siempre revisa toda la tabla.
IS NULL / IS NOT NULL
En bases de datos, NULL es un valor especial que significa “no hay dato” o “desconocido”. No es lo mismo que cero, no es lo mismo que una cadena vacia, y no es lo mismo que false. Es la ausencia de valor.
Un detalle importante: no puedes comparar con NULL usando =. Tienes que usar IS NULL o IS NOT NULL:
-- INCORRECTO: esto no funciona como esperasSELECT nombreFROM empleadosWHERE jefe_id = NULL;-- Resultado: 0 filas (siempre, incluso si hay NULLs)
-- CORRECTO: usa IS NULLSELECT nombreFROM empleadosWHERE jefe_id IS NULL;-- Resultado: Sofia Mendez (la gerente, no tiene jefe)¿Por que = NULL no funciona? Porque en SQL, cualquier comparacion con NULL devuelve NULL (ni verdadero ni falso). Es como preguntar “¿es lo desconocido igual a lo desconocido?” La respuesta es: no se sabe.
-- Empleados que SI tienen jefeSELECT nombre, jefe_idFROM empleadosWHERE jefe_id IS NOT NULL; nombre | jefe_id---------------------+--------- Juan Perez | 1 Valentina Castro | 1 Miguel Angel Torres | 1 Camila Rojas | 4 Alejandro Vega | 4 Fernanda Luna | 2 Ricardo Soto | 4 Patricia Herrera | 8 Daniela Flores | 2La trampa del NULL
Este es uno de los errores mas comunes en SQL. Recuerda estas reglas:
NULL = NULLdevuelve NULL (no TRUE)NULL <> NULLdevuelve NULL (no TRUE)NULL > 5devuelve NULL- Para verificar NULL, siempre usa
IS NULLoIS NOT NULL
Combinando todo
Ahora que conoces todas las herramientas de filtrado, puedes combinarlas para hacer consultas precisas:
-- Productos de Electronica entre $50 y $500 con stock mayor a 30SELECT nombre, precio, stockFROM productosWHERE categoria = 'Electronica' AND precio BETWEEN 50 AND 500 AND stock > 30; nombre | precio | stock-----------------------+--------+------- Teclado Mecanico | 89.99 | 80 Auriculares Bluetooth | 59.99 | 200 Webcam HD | 79.99 | 60-- Clientes de Santiago o Valparaiso cuyos nombres empiezan con 'C' o 'M'SELECT nombre, ciudad, emailFROM clientesWHERE ciudad IN ('Santiago', 'Valparaiso') AND (nombre LIKE 'C%' OR nombre LIKE 'M%'); nombre | ciudad | email-----------------+-------------+---------------- Maria Garcia | Santiago | maria@email.com Carlos Lopez | Valparaiso | carlos@email.com-- Pedidos completados de mas de $100 en el primer trimestre de 2024SELECT id, cliente_id, fecha, totalFROM pedidosWHERE estado = 'completado' AND total > 100 AND fecha BETWEEN '2024-01-01' AND '2024-03-31';-- Empleados que no son de Ventas ni de Soporte y ganan mas de 50000SELECT nombre, departamento, salarioFROM empleadosWHERE departamento NOT IN ('Ventas', 'Soporte') AND salario > 50000;Filtrar temprano, filtrar mucho
Imagina una tabla con 10 millones de filas. Si tu WHERE reduce eso a 1000 filas, cualquier operacion posterior (ordenar, agrupar, hacer JOINs) trabaja con 1000 filas en vez de 10 millones.
Conceptualmente, una consulta sin WHERE sobre una tabla de N filas tiene que procesar las N filas completas. Un WHERE con una condicion sobre una columna indexada puede encontrar las filas relevantes en tiempo logaritmico, es decir O(log N) en vez de O(N). Veremos indices mas adelante, pero la leccion por ahora es: cada condicion en WHERE que reduce filas mejora el rendimiento de toda la consulta.
Resumen de operadores
Aqui tienes una referencia rapida de todo lo que vimos:
| Operador | Descripcion | Ejemplo |
|---|---|---|
= | Igual a | WHERE precio = 29.99 |
<> o != | Diferente de | WHERE estado <> 'pendiente' |
> | Mayor que | WHERE precio > 100 |
< | Menor que | WHERE stock < 50 |
>= | Mayor o igual | WHERE salario >= 45000 |
<= | Menor o igual | WHERE precio <= 50 |
AND | Ambas condiciones | WHERE precio > 10 AND stock > 0 |
OR | Al menos una condicion | WHERE ciudad = 'Santiago' OR ciudad = 'Temuco' |
NOT | Invierte la condicion | WHERE NOT categoria = 'Muebles' |
BETWEEN | Rango inclusivo | WHERE precio BETWEEN 10 AND 100 |
IN | Lista de valores | WHERE ciudad IN ('Santiago', 'Temuco') |
LIKE | Patron (sensible a mayusculas) | WHERE nombre LIKE 'M%' |
ILIKE | Patron (sin distinguir mayusculas) | WHERE nombre ILIKE '%laptop%' |
IS NULL | Es nulo | WHERE jefe_id IS NULL |
IS NOT NULL | No es nulo | WHERE email IS NOT NULL |
Ejercicios
Ejercicio 1: Encuentra todos los productos que cuestan menos de $50.
Ver solucion
SELECT nombre, precioFROM productosWHERE precio < 50;Ejercicio 2: Muestra los pedidos con estado ‘enviado’ que tengan un total mayor a $500.
Ver solucion
SELECT id, cliente_id, fecha, total, estadoFROM pedidosWHERE estado = 'enviado' AND total > 500;Ejercicio 3: Encuentra todos los clientes que NO viven en Santiago.
Ver solucion
SELECT nombre, ciudadFROM clientesWHERE ciudad <> 'Santiago';-- Tambien valido: WHERE NOT ciudad = 'Santiago'-- Tambien valido: WHERE ciudad NOT IN ('Santiago')Ejercicio 4: Busca los productos cuyo nombre contiene la palabra “Monitor” (sin importar mayusculas o minusculas).
Ver solucion
SELECT nombre, precio, categoriaFROM productosWHERE nombre ILIKE '%monitor%';Ejercicio 5: Encuentra empleados del departamento de Tecnologia o Ventas que ganen entre 40000 y 60000.
Ver solucion
SELECT nombre, departamento, salarioFROM empleadosWHERE departamento IN ('Tecnologia', 'Ventas') AND salario BETWEEN 40000 AND 60000;Ejercicio 6: Muestra los pedidos realizados en marzo de 2024 que esten pendientes o enviados.
Ver solucion
SELECT id, cliente_id, fecha, total, estadoFROM pedidosWHERE fecha BETWEEN '2024-03-01' AND '2024-03-31' AND estado IN ('pendiente', 'enviado');Ejercicio 7: Encuentra al empleado (o empleados) que no tiene jefe. ¿Que cargo crees que tiene esa persona?
Ver solucion
SELECT nombre, departamento, salarioFROM empleadosWHERE jefe_id IS NULL;-- Resultado: Sofia Mendez, del departamento Gerencia.-- Es la gerente general, la unica sin jefe.Ejercicio 8 (desafio): Escribe una consulta que encuentre productos de la categoria ‘Accesorios’ que cuesten menos de $30 O productos de cualquier categoria con stock mayor a 200. Asegurate de que los parentesis esten correctos.
Ver solucion
SELECT nombre, precio, categoria, stockFROM productosWHERE (categoria = 'Accesorios' AND precio < 30) OR stock > 200;Los parentesis son clave aqui. Sin ellos, el AND se evaluaria primero y el resultado seria diferente. Los productos que cumplen son:
- Cable HDMI 2m ($12.99, Accesorios) - cumple la primera condicion
- Mousepad XL ($19.99, Accesorios) - cumple la primera condicion
- Cargador Rapido ($24.99, Accesorios) - cumple la primera condicion
- Cable HDMI 2m tambien cumple la segunda (stock: 300)
- Cargador Rapido tambien cumple la segunda (stock: 250)
Ordenar y paginar resultados
Hasta ahora sabemos seleccionar columnas y filtrar filas. Pero los resultados nos llegan en cualquier orden. En este modulo vamos a aprender a ordenar los resultados y a paginarlos para no traer todo de golpe.
ORDER BY: Ordenando resultados
Por defecto, SQL no garantiza ningun orden en los resultados. Si quieres un orden especifico, debes pedirlo explicitamente con ORDER BY.
SELECT nombre, precioFROM productosORDER BY precio;Esto te devuelve los productos ordenados por precio de menor a mayor (ascendente). Es el comportamiento por defecto.
ASC y DESC
Puedes ser explicito con la direccion del ordenamiento:
-- Ascendente (por defecto)SELECT nombre, precioFROM productosORDER BY precio ASC;
-- Descendente: del mas caro al mas baratoSELECT nombre, precioFROM productosORDER BY precio DESC;Un ejemplo practico: quieres ver los clientes mas recientes primero.
SELECT nombre, email, fecha_registroFROM clientesORDER BY fecha_registro DESC;Consejo practico
ORDER BY columna DESC es muy comun cuando quieres ver “lo mas reciente primero” o “lo mas grande primero”. Lo vas a usar todo el tiempo.
Ordenar por multiples columnas
Puedes ordenar por varias columnas. SQL ordena primero por la primera columna, y cuando hay empates, usa la segunda columna para desempatar.
SELECT nombre, categoria, precioFROM productosORDER BY categoria ASC, precio DESC;Esto agrupa los productos por categoria (alfabeticamente) y dentro de cada categoria los ordena del mas caro al mas barato. Piensa en ello como: “primero ordena por categoria, y si dos productos tienen la misma categoria, desempata por precio.”
Otro ejemplo: ordenar pedidos por estado y luego por fecha.
SELECT id, cliente_id, estado, fecha, totalFROM pedidosORDER BY estado ASC, fecha DESC;Asi ves todos los pedidos “completado” juntos (los mas recientes primero), luego los “pendiente”, etc.
ORDER BY con numero de posicion
En vez de escribir el nombre de la columna, puedes usar el numero de posicion en el SELECT:
SELECT nombre, precio, categoriaFROM productosORDER BY 3, 2 DESC;Aqui 3 se refiere a categoria (la tercera columna en el SELECT) y 2 se refiere a precio.
Cuidado con los numeros de posicion
Esto funciona, pero hace tu consulta mas dificil de leer. Si alguien cambia el orden de las columnas en el SELECT, el ORDER BY se rompe silenciosamente. Prefiere usar nombres de columnas siempre que puedas.
LIMIT: Restringir la cantidad de resultados
No siempre quieres todos los resultados. LIMIT te permite decir “dame solo los primeros N”.
-- Los 5 productos mas carosSELECT nombre, precioFROM productosORDER BY precio DESCLIMIT 5;-- Los 3 clientes mas recientesSELECT nombre, email, fecha_registroFROM clientesORDER BY fecha_registro DESCLIMIT 3;Nota
LIMIT sin ORDER BY te da N filas “cualesquiera”. Como SQL no garantiza orden, no sabes cuales te va a dar. Casi siempre quieres usar LIMIT junto con ORDER BY.
OFFSET: Saltarse filas
OFFSET le dice a la base de datos “saltate las primeras N filas”.
-- Saltate los primeros 5 productos y dame los siguientes 5SELECT nombre, precioFROM productosORDER BY precio DESCLIMIT 5 OFFSET 5;Esto te da los productos del puesto 6 al 10 (ordenados por precio descendente).
El patron LIMIT + OFFSET para paginacion
Este es uno de los patrones mas usados en aplicaciones web. Imagina que tienes una pagina de productos con 10 productos por pagina:
-- Pagina 1 (productos 1-10)SELECT nombre, precio, categoriaFROM productosORDER BY nombreLIMIT 10 OFFSET 0;
-- Pagina 2 (productos 11-20)SELECT nombre, precio, categoriaFROM productosORDER BY nombreLIMIT 10 OFFSET 10;
-- Pagina 3 (productos 21-30)SELECT nombre, precio, categoriaFROM productosORDER BY nombreLIMIT 10 OFFSET 20;La formula general es: OFFSET = (numero_pagina - 1) * elementos_por_pagina.
Formula de paginacion
Para la pagina P mostrando N elementos: LIMIT N OFFSET (P - 1) * N
NULLS FIRST y NULLS LAST
Cuando ordenas una columna que tiene valores NULL, PostgreSQL los pone al final por defecto en orden ascendente. Puedes controlar esto:
-- NULLs primeroSELECT nombre, precioFROM productosORDER BY precio ASC NULLS FIRST;
-- NULLs al final (explicitamente)SELECT nombre, precioFROM productosORDER BY precio ASC NULLS LAST;
-- Con DESC, por defecto los NULLs van primero.-- Si quieres cambiar eso:SELECT nombre, precioFROM productosORDER BY precio DESC NULLS LAST;Comportamiento por defecto
En PostgreSQL: ASC pone los NULL al final, DESC los pone al principio. Con NULLS FIRST / NULLS LAST puedes forzar la posicion que prefieras.
Combinando todo
Veamos un ejemplo completo que combina lo que hemos aprendido:
-- Los 10 pedidos mas recientes de estado 'completado',-- ordenados por total descendenteSELECT p.id, c.nombre AS cliente, p.fecha, p.totalFROM pedidos pJOIN clientes c ON p.cliente_id = c.idWHERE p.estado = 'completado'ORDER BY p.total DESC, p.fecha DESCLIMIT 10;No te preocupes por el JOIN todavia (lo veremos en el Modulo 7). Lo importante aqui es ver como WHERE, ORDER BY y LIMIT trabajan juntos.
Rendimiento y complejidad
Vamos a hablar de algo que muchos cursos ignoran: que tan costosas son estas operaciones.
Costo de ORDER BY
ORDER BY requiere ordenar todos los resultados. La complejidad de un ordenamiento es O(n log n) donde n es el numero de filas a ordenar. En tablas pequenas no lo notas, pero si tienes millones de filas, ordenar puede ser muy lento.
LIMIT ayuda… pero tiene limites
Cuando usas LIMIT, la base de datos puede hacer una optimizacion: no necesita ordenar todo, solo encontrar los primeros N elementos. Esto es mas rapido.
-- PostgreSQL puede optimizar esto: no ordena todo,-- solo busca los 10 mas grandesSELECT nombre, precioFROM productosORDER BY precio DESCLIMIT 10;El problema de la paginacion profunda con OFFSET
Aqui viene el problema serio. Mira estas dos consultas:
-- Pagina 1: rapidaSELECT * FROM productos ORDER BY id LIMIT 10 OFFSET 0;
-- Pagina 100,000: MUY lentaSELECT * FROM productos ORDER BY id LIMIT 10 OFFSET 999990;La segunda consulta parece inocente, pero la base de datos tiene que leer y descartar 999,990 filas antes de darte las 10 que pides. El OFFSET es O(n) - tiene que recorrer todas esas filas aunque no las devuelva.
OFFSET profundo es lento
OFFSET 1000000 significa que la base de datos lee un millon de filas para descartarlas. No importa que tu LIMIT sea solo 10. Cuanto mas profunda la paginacion, mas lenta la consulta.
Alternativa: paginacion por keyset (cursor)
La solucion profesional para paginacion profunda es usar keyset pagination (paginacion por cursor). En vez de decir “saltate N filas”, dices “dame filas despues de este valor”:
-- En vez de OFFSET, usamos WHERE con el ultimo ID visto-- Supongamos que el ultimo producto de la pagina anterior tenia id = 500SELECT id, nombre, precioFROM productosWHERE id > 500ORDER BY idLIMIT 10;Esto es O(log n) si id tiene un indice (casi siempre lo tiene). No importa si estas en la pagina 1 o en la pagina 100,000, la velocidad es la misma.
Cuando usar cada patron
- LIMIT + OFFSET: Perfecto para pocas paginas (menos de ~100 paginas). Simple de implementar.
- Keyset pagination: Necesario cuando tienes muchos datos y el usuario puede navegar a paginas profundas. Mas complejo pero mucho mas eficiente.
Ejercicios
Practica con estas consultas usando la base de datos del curso.
Ejercicio 1: Muestra todos los productos ordenados por precio de mayor a menor. Muestra nombre, precio y categoria.
Ver solucion
SELECT nombre, precio, categoriaFROM productosORDER BY precio DESC;Ejercicio 2: Muestra los 5 clientes mas antiguos (los que se registraron primero). Muestra su nombre, email y fecha de registro.
Ver solucion
SELECT nombre, email, fecha_registroFROM clientesORDER BY fecha_registro ASCLIMIT 5;Ejercicio 3: Muestra los productos ordenados por categoria (ascendente) y dentro de cada categoria por precio (descendente). Limita a 20 resultados.
Ver solucion
SELECT nombre, categoria, precioFROM productosORDER BY categoria ASC, precio DESCLIMIT 20;Ejercicio 4: Simula la pagina 3 de un listado de pedidos (10 pedidos por pagina), ordenados por fecha descendente. Muestra id, fecha, total y estado.
Ver solucion
SELECT id, fecha, total, estadoFROM pedidosORDER BY fecha DESCLIMIT 10 OFFSET 20;Pagina 3 con 10 elementos por pagina: OFFSET = (3 - 1) * 10 = 20
Ejercicio 5: Muestra los 3 pedidos con el total mas alto que esten en estado ‘pendiente’.
Ver solucion
SELECT id, cliente_id, fecha, totalFROM pedidosWHERE estado = 'pendiente'ORDER BY total DESCLIMIT 3;Ejercicio 6 (Desafio): Escribe una consulta con keyset pagination. Supongamos que ya viste productos con id hasta el 50. Trae los siguientes 10 productos ordenados por id.
Ver solucion
SELECT id, nombre, precio, categoriaFROM productosWHERE id > 50ORDER BY id ASCLIMIT 10;Esto es mucho mas eficiente que OFFSET 50 para tablas grandes, ya que usa el indice de la columna id directamente.
Funciones de agregacion
Hasta ahora hemos trabajado con filas individuales: seleccionar, filtrar, ordenar. Pero muchas veces necesitas resumenes: cuantos productos hay, cual es el precio promedio, cuanto se vendio en total. Para eso existen las funciones de agregacion.
Las funciones basicas de agregacion
COUNT: Contar filas
COUNT cuenta el numero de filas. Tiene varias formas:
-- Contar TODAS las filas de la tablaSELECT COUNT(*) FROM productos;
-- Contar filas donde la columna NO es NULLSELECT COUNT(email) FROM clientes;
-- Contar valores DISTINTOSSELECT COUNT(DISTINCT categoria) FROM productos;COUNT(*) vs COUNT(columna)
COUNT(*) cuenta todas las filas, incluyendo las que tienen NULLs. COUNT(columna) solo cuenta filas donde esa columna no es NULL. COUNT(DISTINCT columna) cuenta valores unicos (sin repetir).
Veamos ejemplos mas concretos:
-- Cuantos clientes tenemos?SELECT COUNT(*) AS total_clientes FROM clientes;
-- Cuantas ciudades distintas tienen nuestros clientes?SELECT COUNT(DISTINCT ciudad) AS ciudades FROM clientes;
-- Cuantos pedidos estan pendientes?SELECT COUNT(*) AS pendientesFROM pedidosWHERE estado = 'pendiente';SUM: Sumar valores
SUM suma todos los valores de una columna numerica.
-- Total de ingresos por pedidos completadosSELECT SUM(total) AS ingresos_totalesFROM pedidosWHERE estado = 'completado';
-- Stock total de todos los productosSELECT SUM(stock) AS stock_total FROM productos;AVG: Promedio
AVG calcula el promedio (la media aritmetica).
-- Precio promedio de los productosSELECT AVG(precio) AS precio_promedio FROM productos;
-- Salario promedio de los empleadosSELECT AVG(salario) AS salario_promedio FROM empleados;
-- Promedio del total de los pedidosSELECT AVG(total) AS pedido_promedio FROM pedidos;Redondear el resultado
AVG suele devolver muchos decimales. Puedes usar ROUND para limitar: ROUND(AVG(precio), 2) te da 2 decimales.
MIN y MAX: Extremos
-- Producto mas barato y mas caroSELECT MIN(precio) AS precio_minimo, MAX(precio) AS precio_maximoFROM productos;
-- Primer y ultimo registro de clientesSELECT MIN(fecha_registro) AS primer_cliente, MAX(fecha_registro) AS ultimo_clienteFROM clientes;
-- El pedido mas grandeSELECT MAX(total) AS pedido_mas_grande FROM pedidos;Combinando varias funciones
Puedes usar varias funciones de agregacion en el mismo SELECT:
SELECT COUNT(*) AS total_productos, ROUND(AVG(precio), 2) AS precio_promedio, MIN(precio) AS mas_barato, MAX(precio) AS mas_caro, SUM(stock) AS stock_totalFROM productos;Esto te da un resumen completo de tu tabla de productos en una sola consulta.
GROUP BY: Agrupando filas
Las funciones de agregacion se vuelven realmente poderosas cuando las combinas con GROUP BY. En vez de un solo resumen para toda la tabla, obtienes un resumen por grupo.
-- Cuantos productos hay en cada categoria?SELECT categoria, COUNT(*) AS cantidadFROM productosGROUP BY categoria;El resultado seria algo como:
| categoria | cantidad |
|---|---|
| Electronica | 6 |
| Accesorios | 5 |
| Muebles | 4 |
Mas ejemplos:
-- Precio promedio por categoriaSELECT categoria, ROUND(AVG(precio), 2) AS precio_promedio, COUNT(*) AS cantidadFROM productosGROUP BY categoria;
-- Total de ventas por estado del pedidoSELECT estado, COUNT(*) AS cantidad_pedidos, SUM(total) AS suma_totales, ROUND(AVG(total), 2) AS promedio_totalFROM pedidosGROUP BY estado;
-- Cuantos clientes por ciudad?SELECT ciudad, COUNT(*) AS total_clientesFROM clientesGROUP BY ciudadORDER BY total_clientes DESC;Regla importante de GROUP BY
Cuando usas GROUP BY, todas las columnas en el SELECT deben ser: (a) columnas por las que agrupas, o (b) funciones de agregacion. No puedes poner una columna suelta que no este en el GROUP BY ni dentro de una funcion de agregacion.
Esto es un error comun:
-- ERROR: "nombre" no esta en GROUP BY ni es una funcion de agregacionSELECT nombre, categoria, COUNT(*)FROM productosGROUP BY categoria;PostgreSQL te va a dar un error porque nombre no sabe cual devolver: hay muchos nombres por categoria. Tienes que elegir: o lo agregas al GROUP BY, o usas una funcion de agregacion como MIN(nombre), MAX(nombre), etc.
GROUP BY con multiples columnas
Puedes agrupar por mas de una columna. Esto crea grupos mas granulares:
-- Cuantos pedidos por estado Y por mesSELECT estado, EXTRACT(MONTH FROM fecha) AS mes, COUNT(*) AS cantidad, SUM(total) AS total_ventasFROM pedidosGROUP BY estado, EXTRACT(MONTH FROM fecha)ORDER BY mes, estado;-- Salario promedio por departamentoSELECT departamento, COUNT(*) AS empleados, ROUND(AVG(salario), 2) AS salario_promedio, MIN(salario) AS salario_minimo, MAX(salario) AS salario_maximoFROM empleadosGROUP BY departamentoORDER BY salario_promedio DESC;HAVING: Filtrar grupos
Ya conoces WHERE para filtrar filas individuales. Pero WHERE se ejecuta antes de agrupar, asi que no puedes usarlo para filtrar basandote en el resultado de una funcion de agregacion.
Para eso existe HAVING: filtra grupos despues de la agregacion.
-- Categorias que tienen mas de 5 productosSELECT categoria, COUNT(*) AS cantidadFROM productosGROUP BY categoriaHAVING COUNT(*) > 5;-- Ciudades con al menos 3 clientesSELECT ciudad, COUNT(*) AS total_clientesFROM clientesGROUP BY ciudadHAVING COUNT(*) >= 3ORDER BY total_clientes DESC;-- Clientes que han gastado mas de 1000 en totalSELECT cliente_id, COUNT(*) AS num_pedidos, SUM(total) AS gasto_totalFROM pedidosGROUP BY cliente_idHAVING SUM(total) > 1000ORDER BY gasto_total DESC;WHERE vs HAVING
Esta es una duda muy comun. La diferencia es cuando se aplica cada filtro:
-- WHERE filtra filas ANTES de agrupar-- HAVING filtra grupos DESPUES de agruparSELECT categoria, AVG(precio) AS precio_promedioFROM productosWHERE stock > 0 -- solo productos con stockGROUP BY categoriaHAVING AVG(precio) > 50 -- solo categorias con promedio > 50ORDER BY precio_promedio DESC;WHERE vs HAVING en resumen
- WHERE: Filtra filas individuales ANTES del GROUP BY. No puede usar funciones de agregacion.
- HAVING: Filtra grupos DESPUES del GROUP BY. SI puede usar funciones de agregacion.
- Usa WHERE siempre que puedas: es mas eficiente porque reduce filas antes de agrupar.
El orden de ejecucion de una consulta SQL
Este es un concepto clave que te va a ayudar a entender por que las cosas funcionan como funcionan. SQL no se ejecuta en el orden en que lo escribes. El orden real es:
-- Asi lo ESCRIBES:SELECT categoria, COUNT(*) AS cantidad -- 5FROM productos -- 1WHERE precio > 10 -- 2GROUP BY categoria -- 3HAVING COUNT(*) > 2 -- 4ORDER BY cantidad DESC -- 6LIMIT 5; -- 7El orden de ejecucion es:
- FROM - Determina de que tabla leer
- WHERE - Filtra filas individuales
- GROUP BY - Agrupa las filas que pasaron el WHERE
- HAVING - Filtra los grupos
- SELECT - Elige que columnas/expresiones mostrar
- ORDER BY - Ordena los resultados
- LIMIT - Corta los resultados
Por que importa este orden?
Esto explica por que no puedes usar un alias del SELECT en el WHERE (el SELECT se ejecuta despues), pero SI puedes usarlo en el ORDER BY (se ejecuta despues del SELECT). Tambien explica por que HAVING puede usar funciones de agregacion pero WHERE no.
Rendimiento y complejidad
Costo de las funciones de agregacion
Las funciones de agregacion como COUNT, SUM, AVG deben recorrer todas las filas que coinciden con el filtro. Esto es O(n) donde n es el numero de filas. No hay forma de evitarlo: para sumar, hay que ver cada valor.
GROUP BY y el costo de agrupar
GROUP BY necesita organizar las filas en grupos. PostgreSQL tiene dos estrategias principales:
-- Si hay pocos grupos distintos, PostgreSQL puede usar-- una tabla hash en memoria: O(n)SELECT categoria, COUNT(*)FROM productosGROUP BY categoria;
-- Si hay muchos grupos o poca memoria, puede necesitar-- ordenar las filas primero: O(n log n)SELECT fecha, COUNT(*)FROM pedidosGROUP BY fecha;Agrupar es O(n) o O(n log n)
GROUP BY usa hashing (O(n), mas rapido) o sorting (O(n log n)). PostgreSQL elige la estrategia automaticamente. En general, mientras menos grupos distintos haya, mas eficiente es la operacion.
Tip: filtra con WHERE antes de agrupar
Siempre que puedas, reduce las filas con WHERE antes del GROUP BY. Esto es mucho mas eficiente que agrupar todo y luego filtrar con HAVING:
-- MEJOR: filtra primero, luego agrupaSELECT categoria, AVG(precio)FROM productosWHERE stock > 0 -- reduce filas ANTES de agruparGROUP BY categoria;
-- PEOR (si lo que filtras NO depende del grupo):-- no filtres con HAVING lo que puedes filtrar con WHEREEjercicios
Ejercicio 1: Cuenta cuantos productos hay en total y cuantas categorias distintas existen.
Ver solucion
SELECT COUNT(*) AS total_productos, COUNT(DISTINCT categoria) AS total_categoriasFROM productos;Ejercicio 2: Calcula el precio minimo, maximo y promedio de los productos. Redondea el promedio a 2 decimales.
Ver solucion
SELECT MIN(precio) AS precio_minimo, MAX(precio) AS precio_maximo, ROUND(AVG(precio), 2) AS precio_promedioFROM productos;Ejercicio 3: Muestra cuantos pedidos hay en cada estado, junto con el total facturado por estado. Ordena por total facturado descendente.
Ver solucion
SELECT estado, COUNT(*) AS cantidad_pedidos, SUM(total) AS total_facturadoFROM pedidosGROUP BY estadoORDER BY total_facturado DESC;Ejercicio 4: Encuentra las categorias de productos que tienen un precio promedio mayor a 100. Muestra la categoria, el precio promedio (redondeado) y la cantidad de productos.
Ver solucion
SELECT categoria, ROUND(AVG(precio), 2) AS precio_promedio, COUNT(*) AS cantidadFROM productosGROUP BY categoriaHAVING AVG(precio) > 100ORDER BY precio_promedio DESC;Ejercicio 5: Para cada ciudad, muestra cuantos clientes hay, pero solo las ciudades con 2 o mas clientes. Ordena de mayor a menor cantidad.
Ver solucion
SELECT ciudad, COUNT(*) AS total_clientesFROM clientesGROUP BY ciudadHAVING COUNT(*) >= 2ORDER BY total_clientes DESC;Ejercicio 6: Muestra el departamento, numero de empleados y salario promedio para cada departamento que tenga un salario promedio mayor a 40000.
Ver solucion
SELECT departamento, COUNT(*) AS num_empleados, ROUND(AVG(salario), 2) AS salario_promedioFROM empleadosGROUP BY departamentoHAVING AVG(salario) > 40000ORDER BY salario_promedio DESC;Ejercicio 7 (Desafio): Encuentra los 3 clientes que mas pedidos han hecho. Muestra el cliente_id, el numero de pedidos, y el gasto total. Solo incluye pedidos con estado ‘completado’.
Ver solucion
SELECT cliente_id, COUNT(*) AS num_pedidos, SUM(total) AS gasto_totalFROM pedidosWHERE estado = 'completado'GROUP BY cliente_idORDER BY num_pedidos DESCLIMIT 3;Nota que usamos WHERE para filtrar por estado (es una condicion sobre filas individuales, no sobre grupos), y ORDER BY + LIMIT para quedarnos con los top 3.
JOINs: Conectando tablas
Hasta ahora hemos consultado una tabla a la vez. Pero la informacion real vive repartida en varias tablas. Los pedidos estan en una tabla, los clientes en otra, los productos en otra. Para obtener respuestas utiles, necesitamos conectar esas tablas. Eso es exactamente lo que hacen los JOIN.
Por que los datos estan en tablas separadas?
Imagina que guardas todo en una sola tabla gigante: cada pedido tendria el nombre del cliente, su email, su ciudad, el nombre del producto, el precio… repetido una y otra vez. Eso es un desastre:
- Datos duplicados: el nombre del cliente se repite en cada pedido que hace.
- Inconsistencia: si el cliente cambia de email, hay que actualizarlo en cientos de filas.
- Desperdicio: ocupas mucho mas espacio del necesario.
La solucion es la normalizacion: separar los datos en tablas relacionadas. Cada tabla tiene un tema (clientes, productos, pedidos) y se conectan mediante claves foraneas (como cliente_id en la tabla pedidos).
Nuestra base de datos tiene esta estructura:
clientes (id, nombre, email, ciudad, fecha_registro) | | cliente_id vpedidos (id, cliente_id, fecha, total, estado) | | pedido_id vdetalle_pedidos (id, pedido_id, producto_id, cantidad, precio_unitario) ^ | producto_id |productos (id, nombre, precio, categoria, stock, fecha_creacion)
empleados (id, nombre, departamento, salario, fecha_contratacion, jefe_id) | | +<-------- jefe_id apunta a otro empleado.id ------------------+Los JOIN nos permiten reconstruir la informacion completa combinando estas tablas.
INNER JOIN: Solo las coincidencias
INNER JOIN devuelve solo las filas que tienen coincidencia en ambas tablas. Si un cliente no tiene pedidos, no aparece. Si un pedido no tiene cliente valido, tampoco aparece.
Veamos como funciona con un ejemplo visual. Supongamos que tenemos estos datos:
tabla clientes tabla pedidos ┌────┬──────────┐ ┌────┬────────────┬───────┐ │ id │ nombre │ │ id │ cliente_id │ total │ ├────┼──────────┤ ├────┼────────────┼───────┤ │ 1 │ Ana │ │ 10 │ 1 │ 500 │ │ 2 │ Bruno │ │ 11 │ 1 │ 300 │ │ 3 │ Carla │ │ 12 │ 3 │ 150 │ └────┴──────────┘ └────┴────────────┴───────┘
Ana tiene 2 pedidos, Carla tiene 1, Bruno no tiene ninguno.Al hacer INNER JOIN:
SELECT c.nombre, p.id AS pedido_id, p.totalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_id; Resultado INNER JOIN ┌──────────┬───────────┬───────┐ │ nombre │ pedido_id │ total │ ├──────────┼───────────┼───────┤ │ Ana │ 10 │ 500 │ │ Ana │ 11 │ 300 │ │ Carla │ 12 │ 150 │ └──────────┴───────────┴───────┘
Bruno NO aparece (no tiene pedidos). Ana aparece 2 veces (tiene 2 pedidos).Ahora con nuestra base de datos de practica:
SELECT c.nombre AS cliente, p.id AS pedido_id, p.fecha, p.totalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_id;Desmenucemos la sintaxis:
FROM clientes c— tabla principal (o “izquierda”)INNER JOIN pedidos p— tabla que queremos conectar (la “derecha”)ON c.id = p.cliente_id— la condicion de conexion
Nota
INNER JOIN y JOIN son lo mismo. La palabra INNER es opcional, pero es buena practica escribirla para ser explicito.
Paso a paso: como PostgreSQL ejecuta un INNER JOIN
Para que entiendas exactamente que ocurre, sigamos el proceso fila por fila:
Paso 1: PostgreSQL toma la PRIMERA fila de clientes → Ana (id = 1)
Paso 2: Busca en pedidos TODAS las filas donde cliente_id = 1 → Pedido 10 (cliente_id = 1, total = 500) ✓ MATCH → Pedido 11 (cliente_id = 1, total = 300) ✓ MATCH → Pedido 12 (cliente_id = 3, total = 150) ✗ No coincide
Paso 3: Combina Ana con cada pedido que coincidio → Fila resultado: Ana | 10 | 500 → Fila resultado: Ana | 11 | 300
Paso 4: Toma la SIGUIENTE fila de clientes → Bruno (id = 2)
Paso 5: Busca en pedidos donde cliente_id = 2 → Pedido 10 (cliente_id = 1) ✗ → Pedido 11 (cliente_id = 1) ✗ → Pedido 12 (cliente_id = 3) ✗ → No hay coincidencias → Bruno NO aparece en el resultado
Paso 6: Toma la SIGUIENTE fila de clientes → Carla (id = 3)
Paso 7: Busca en pedidos donde cliente_id = 3 → Pedido 12 (cliente_id = 3, total = 150) ✓ MATCH → Fila resultado: Carla | 12 | 150La regla es simple: sin match, no hay fila. Un INNER JOIN solo produce resultados cuando ambos lados tienen datos que coinciden.
Puedes encadenar multiples JOINs. Aqui conectamos detalle_pedidos con pedidos y con productos:
SELECT p.id AS pedido_id, pr.nombre AS producto, dp.cantidad, dp.precio_unitarioFROM detalle_pedidos dpINNER JOIN pedidos p ON dp.pedido_id = p.idINNER JOIN productos pr ON dp.producto_id = pr.id;Aliases de tablas: Escribir menos
Escribir clientes.nombre y pedidos.fecha una y otra vez es tedioso. Usa aliases para abreviar:
SELECT c.nombre AS cliente, p.id AS pedido_id, p.fecha, p.totalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_id;clientes c le da el alias c a la tabla clientes. Ahora puedes escribir c.nombre en vez de clientes.nombre. Esto no cambia el resultado, solo hace la consulta mas corta y legible.
Convencion de aliases
Una convencion comun es usar la primera letra de la tabla: c para clientes, p para pedidos, pr o prod para productos, dp para detalle_pedidos, e para empleados. Lo importante es que sea consistente y claro.
LEFT JOIN: Todo de la tabla izquierda
LEFT JOIN (o LEFT OUTER JOIN) devuelve todas las filas de la tabla izquierda, incluso si no tienen coincidencia en la tabla derecha. Donde no hay coincidencia, las columnas de la derecha seran NULL.
Usando los mismos datos del ejemplo anterior:
tabla clientes tabla pedidos ┌────┬──────────┐ ┌────┬────────────┬───────┐ │ id │ nombre │ │ id │ cliente_id │ total │ ├────┼──────────┤ ├────┼────────────┼───────┤ │ 1 │ Ana │ │ 10 │ 1 │ 500 │ │ 2 │ Bruno │ │ 11 │ 1 │ 300 │ │ 3 │ Carla │ │ 12 │ 3 │ 150 │ └────┴──────────┘ └────┴────────────┴───────┘SELECT c.nombre, p.id AS pedido_id, p.totalFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_id; Resultado LEFT JOIN ┌──────────┬───────────┬───────┐ │ nombre │ pedido_id │ total │ ├──────────┼───────────┼───────┤ │ Ana │ 10 │ 500 │ │ Ana │ 11 │ 300 │ │ Bruno │ NULL │ NULL │ ← Bruno aparece con NULLs │ Carla │ 12 │ 150 │ └──────────┴───────────┴───────┘
TODOS los clientes aparecen, tengan o no pedidos.Paso a paso: como PostgreSQL ejecuta un LEFT JOIN
La diferencia con INNER JOIN es sutil pero crucial:
Paso 1: PostgreSQL toma la PRIMERA fila de clientes → Ana (id = 1)
Paso 2: Busca en pedidos donde cliente_id = 1 → Pedido 10 ✓ MATCH → Fila: Ana | 10 | 500 → Pedido 11 ✓ MATCH → Fila: Ana | 11 | 300
Paso 3: Toma la SIGUIENTE fila de clientes → Bruno (id = 2)
Paso 4: Busca en pedidos donde cliente_id = 2 → No hay coincidencias... → Pero es LEFT JOIN, asi que Bruno NO se descarta. → En vez de eliminarlo, PostgreSQL rellena con NULLs: → Fila: Bruno | NULL | NULL ← ¡Esta es la diferencia!
Paso 5: Toma la SIGUIENTE fila de clientes → Carla (id = 3)
Paso 6: Busca en pedidos donde cliente_id = 3 → Pedido 12 ✓ MATCH → Fila: Carla | 12 | 150La diferencia clave: donde INNER JOIN descarta las filas sin match, LEFT JOIN las conserva rellenando con NULLs. Esto garantiza que nunca pierdas datos de la tabla izquierda.
Ahora con nuestra base de datos:
-- TODOS los clientes, tengan o no pedidosSELECT c.nombre AS cliente, c.email, p.id AS pedido_id, p.totalFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_id;Patron: encontrar registros sin relacion
LEFT JOIN + WHERE tabla_derecha.id IS NULL es un patron clasico para encontrar registros huerfanos:
-- Clientes que NUNCA han hecho un pedidoSELECT c.nombre, c.emailFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idWHERE p.id IS NULL;-- Productos que nunca se han vendidoSELECT pr.nombre, pr.precio, pr.categoriaFROM productos prLEFT JOIN detalle_pedidos dp ON pr.id = dp.producto_idWHERE dp.id IS NULL;-- Todos los productos con su cantidad total vendida (0 si nunca se vendieron)SELECT pr.nombre, pr.precio, COALESCE(SUM(dp.cantidad), 0) AS total_vendidoFROM productos prLEFT JOIN detalle_pedidos dp ON pr.id = dp.producto_idGROUP BY pr.id, pr.nombre, pr.precioORDER BY total_vendido DESC;COALESCE para manejar NULLs
COALESCE(valor, 0) devuelve valor si no es NULL, o 0 si es NULL. Muy util con LEFT JOIN para convertir NULLs en ceros.
RIGHT JOIN: Todo de la tabla derecha
RIGHT JOIN (o RIGHT OUTER JOIN) es el espejo del LEFT JOIN: mantiene todas las filas de la tabla derecha, incluso si no tienen coincidencia en la izquierda. Donde no hay coincidencia, las columnas de la izquierda seran NULL.
Veamoslo con un ejemplo donde hay un pedido con un cliente_id que no existe:
tabla clientes tabla pedidos ┌────┬──────────┐ ┌────┬────────────┬───────┐ │ id │ nombre │ │ id │ cliente_id │ total │ ├────┼──────────┤ ├────┼────────────┼───────┤ │ 1 │ Ana │ │ 10 │ 1 │ 500 │ │ 2 │ Bruno │ │ 11 │ 1 │ 300 │ │ 3 │ Carla │ │ 12 │ 3 │ 150 │ └────┴──────────┘ │ 13 │ 99 │ 200 │ ← cliente_id 99 no existe └────┴────────────┴───────┘SELECT c.nombre, p.id AS pedido_id, p.totalFROM clientes cRIGHT JOIN pedidos p ON c.id = p.cliente_id; Resultado RIGHT JOIN ┌──────────┬───────────┬───────┐ │ nombre │ pedido_id │ total │ ├──────────┼───────────┼───────┤ │ Ana │ 10 │ 500 │ │ Ana │ 11 │ 300 │ │ Carla │ 12 │ 150 │ │ NULL │ 13 │ 200 │ ← pedido 13 aparece, pero sin cliente └──────────┴───────────┴───────┘
TODOS los pedidos aparecen. El pedido 13 tiene un cliente_id invalido, asi que nombre es NULL. Bruno NO aparece (no tiene pedidos y no es la tabla "protegida").Compara con LEFT JOIN para ver la diferencia:
LEFT JOIN protege la tabla IZQUIERDA (clientes): Ana ✓ Bruno ✓ (con NULLs) Carla ✓ Pedido 13 ✗ (desaparece)
RIGHT JOIN protege la tabla DERECHA (pedidos): Pedido 10 ✓ Pedido 11 ✓ Pedido 12 ✓ Pedido 13 ✓ (con NULLs) Bruno ✗ (desaparece)Un RIGHT JOIN siempre se puede reescribir como LEFT JOIN invirtiendo el orden de las tablas:
-- Esto con RIGHT JOIN...SELECT c.nombre, p.id, p.totalFROM clientes cRIGHT JOIN pedidos p ON c.id = p.cliente_id;
-- ...es IDENTICO a esto con LEFT JOIN (tablas invertidas)SELECT c.nombre, p.id, p.totalFROM pedidos pLEFT JOIN clientes c ON c.id = p.cliente_id;Tip
En la practica, casi nadie usa RIGHT JOIN. Simplemente inviertes el orden de las tablas y usas LEFT JOIN. Es mas facil de leer y mas consistente. Si ves un RIGHT JOIN en codigo existente, ya sabes que es lo mismo que un LEFT JOIN al reves.
FULL OUTER JOIN: Todo de ambos lados
FULL OUTER JOIN devuelve todas las filas de ambas tablas. Donde hay coincidencia, las combina. Donde no, pone NULLs en las columnas de la tabla que no tiene coincidencia.
tabla clientes tabla pedidos ┌────┬──────────┐ ┌────┬────────────┬───────┐ │ id │ nombre │ │ id │ cliente_id │ total │ ├────┼──────────┤ ├────┼────────────┼───────┤ │ 1 │ Ana │ │ 10 │ 1 │ 500 │ │ 2 │ Bruno │ │ 11 │ 1 │ 300 │ │ 3 │ Carla │ │ 12 │ 3 │ 150 │ └────┴──────────┘ │ 13 │ 99 │ 200 │ ← cliente_id 99 no existe └────┴────────────┴───────┘SELECT c.nombre, p.id AS pedido_id, p.totalFROM clientes cFULL OUTER JOIN pedidos p ON c.id = p.cliente_id; Resultado FULL OUTER JOIN ┌──────────┬───────────┬───────┐ │ nombre │ pedido_id │ total │ ├──────────┼───────────┼───────┤ │ Ana │ 10 │ 500 │ │ Ana │ 11 │ 300 │ │ Bruno │ NULL │ NULL │ ← cliente sin pedidos │ Carla │ 12 │ 150 │ │ NULL │ 13 │ 200 │ ← pedido sin cliente valido └──────────┴───────────┴───────┘
Aparece TODO: clientes sin pedidos Y pedidos sin cliente.Con nuestra base de datos:
SELECT c.nombre AS cliente, p.id AS pedido_id, p.totalFROM clientes cFULL OUTER JOIN pedidos p ON c.id = p.cliente_id;En la practica, FULL OUTER JOIN se usa poco comparado con INNER JOIN o LEFT JOIN, pero es muy util para auditorias o para encontrar inconsistencias en los datos.
CROSS JOIN: Todas las combinaciones posibles
CROSS JOIN genera el producto cartesiano: combina cada fila de la tabla izquierda con todas las filas de la tabla derecha. No usa clausula ON porque no necesita condicion de match — simplemente combina todo con todo.
tabla colores tabla tallas ┌───────────┐ ┌──────────┐ │ color │ │ talla │ ├───────────┤ ├──────────┤ │ Rojo │ │ S │ │ Azul │ │ M │ └───────────┘ │ L │ └──────────┘SELECT color, tallaFROM coloresCROSS JOIN tallas; Resultado CROSS JOIN (2 × 3 = 6 filas) ┌───────────┬──────────┐ │ color │ talla │ ├───────────┼──────────┤ │ Rojo │ S │ │ Rojo │ M │ │ Rojo │ L │ │ Azul │ S │ │ Azul │ M │ │ Azul │ L │ └───────────┴──────────┘
Cada color se combina con CADA talla. Sin excepciones.Cuidado con el tamaño
Si la tabla A tiene 1,000 filas y la tabla B tiene 1,000 filas, un CROSS JOIN genera 1,000,000 de filas. Usalo solo con tablas pequenas o con un proposito claro.
Ejemplo practico con nuestra BD
Un uso comun es generar combinaciones para reportes. Por ejemplo, queremos asegurar que todas las categorias aparezcan para cada ciudad, incluso si no hubo ventas:
-- Generar todas las combinaciones categoria × ciudadSELECT DISTINCT pr.categoria, c.ciudadFROM productos prCROSS JOIN clientes cORDER BY pr.categoria, c.ciudad;Otro ejemplo practico: comparar cada producto contra el promedio de su categoria:
-- Promedio por categoria usando CROSS JOIN con una subconsultaSELECT p.nombre, p.precio, p.categoria, avg_cat.promedio, ROUND(p.precio - avg_cat.promedio, 2) AS diferenciaFROM productos pINNER JOIN ( SELECT categoria, ROUND(AVG(precio), 2) AS promedio FROM productos GROUP BY categoria) avg_cat ON p.categoria = avg_cat.categoriaORDER BY p.categoria, diferencia DESC;Sintaxis alternativa
CROSS JOIN tambien se puede escribir con coma en el FROM: FROM tabla_a, tabla_b. Son equivalentes, pero CROSS JOIN es mas explicito y claro sobre tu intencion.
Resumen visual: todos los JOINs de un vistazo
Imagina dos tablas como circulos. La zona de interseccion son las filas que coinciden. Cada JOIN “ilumina” una parte distinta:
INNER JOIN
LEFT JOIN
RIGHT JOIN
FULL OUTER JOIN
Cuando usar cada JOIN
| Comando | Descripcion |
|---|---|
| INNER JOIN | Necesitas solo los datos que tienen match en ambas tablas. Es el JOIN mas comun. Ejemplo: 'clientes que SI tienen pedidos'. |
| LEFT JOIN | Necesitas TODOS los registros de la tabla principal, tengan o no match. Ejemplo: 'todos los clientes, con o sin pedidos'. Tambien para encontrar registros sin relacion (con WHERE ... IS NULL). |
| RIGHT JOIN | Casi nunca. Puedes invertir las tablas y usar LEFT JOIN, que es mas legible. |
| FULL OUTER JOIN | Para auditorias: encontrar registros huerfanos en AMBAS tablas. Poco comun en consultas del dia a dia. |
| CROSS JOIN | Genera TODAS las combinaciones posibles (producto cartesiano). Util para generar combinaciones, calendarios, o tablas de referencia. Rara vez se usa con datos transaccionales. |
Regla rapida
Si la pregunta incluye la palabra “todos” (todos los clientes, todos los productos), probablemente necesitas LEFT JOIN. Si solo te interesan los que tienen datos relacionados, usa INNER JOIN.
Self JOIN: Una tabla consigo misma
A veces necesitas conectar una tabla consigo misma. El ejemplo clasico es la tabla empleados donde jefe_id apunta al id de otro empleado.
-- Ver cada empleado junto con el nombre de su jefeSELECT e.nombre AS empleado, e.departamento, j.nombre AS jefeFROM empleados eLEFT JOIN empleados j ON e.jefe_id = j.id;Aqui usamos la tabla empleados dos veces: una como e (el empleado) y otra como j (el jefe). El LEFT JOIN asegura que aparezcan todos los empleados, incluso el jefe superior que no tiene jefe (su jefe_id seria NULL).
-- Empleados que ganan mas que su jefeSELECT e.nombre AS empleado, e.salario AS salario_empleado, j.nombre AS jefe, j.salario AS salario_jefeFROM empleados eINNER JOIN empleados j ON e.jefe_id = j.idWHERE e.salario > j.salario;Self JOIN requiere aliases
Cuando haces un self JOIN, los aliases son obligatorios. Sin ellos, PostgreSQL no sabe a cual de las dos “copias” de la tabla te refieres.
JOIN con multiples condiciones y ON vs WHERE
La clausula ON puede tener mas de una condicion, conectadas con AND:
SELECT p.id AS pedido_id, p.fecha, pr.nombre AS producto, dp.cantidad, dp.precio_unitarioFROM pedidos pINNER JOIN detalle_pedidos dp ON dp.pedido_id = p.idINNER JOIN productos pr ON dp.producto_id = pr.id AND pr.categoria = 'Electronica'WHERE p.fecha >= '2024-01-01';ON vs WHERE: diferencia critica con LEFT JOIN
Con INNER JOIN, poner la condicion en el ON o en el WHERE da el mismo resultado. Pero con LEFT JOIN, es muy diferente: una condicion en el ON filtra antes de hacer el join (sin perder filas de la izquierda), mientras que en el WHERE filtra despues (y puede eliminar filas de la izquierda).
Este es uno de los errores mas frecuentes con JOINs. Veamos la diferencia:
-- Condicion en ON:-- Muestra TODOS los clientes, pero solo sus pedidos completadosSELECT c.nombre, p.id, p.estadoFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_id AND p.estado = 'completado';-- Clientes sin pedidos completados aparecen con NULLs ✓
-- Condicion en WHERE:-- Solo muestra clientes que TENGAN pedidos completadosSELECT c.nombre, p.id, p.estadoFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idWHERE p.estado = 'completado';-- Clientes sin pedidos completados DESAPARECEN ✗-- (porque p.estado seria NULL, y NULL != 'completado')¿Por que la segunda consulta pierde filas? Porque WHERE se aplica despues del JOIN. Para un cliente sin pedidos completados, p.estado es NULL, y NULL = 'completado' es falso. Entonces esa fila se descarta, y el LEFT JOIN se comporta como si fuera un INNER JOIN.
LEFT JOIN que se convierte en INNER JOIN
Si filtras por una columna de la tabla derecha en el WHERE (por ejemplo, WHERE p.estado = 'completado'), estas eliminando todas las filas donde esa columna es NULL, lo que cancela el efecto del LEFT JOIN. Si necesitas filtrar la tabla derecha sin perder filas de la izquierda, pon la condicion en el ON.
La trampa de los duplicados
Esta es probablemente la fuente de errores mas frustrante para quienes empiezan con JOINs. Cuando haces un JOIN, las filas se pueden multiplicar, y si no lo tienes en cuenta, tus conteos y sumas seran incorrectos.
Por que los JOINs generan filas repetidas
Un JOIN combina cada fila de la tabla izquierda con cada fila que coincida en la tabla derecha. Si un cliente tiene 3 pedidos, ese cliente aparece 3 veces en el resultado:
SELECT c.nombre, p.id AS pedido_id, p.totalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idWHERE c.nombre = 'Ana Torres'; ┌─────────────┬───────────┬────────┐ │ nombre │ pedido_id │ total │ ├─────────────┼───────────┼────────┤ │ Ana Torres │ 1 │ 150.50 │ │ Ana Torres │ 4 │ 89.99 │ │ Ana Torres │ 7 │ 320.00 │ └─────────────┴───────────┴────────┘
Ana aparece 3 veces porque tiene 3 pedidos. Esto es CORRECTO — cada fila es un pedido distinto.Hasta aqui todo bien. El problema aparece cuando agregas otro JOIN que multiplica las filas aun mas.
El efecto multiplicador con multiples JOINs
Supongamos que Ana tiene 3 pedidos, y cada pedido tiene 2 productos en detalle_pedidos. Si hacemos JOIN de pedidos con detalle_pedidos:
SELECT c.nombre, p.id AS pedido_id, p.total, dp.producto_id, dp.cantidadFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idWHERE c.nombre = 'Ana Torres'; ┌─────────────┬───────────┬────────┬─────────────┬──────────┐ │ nombre │ pedido_id │ total │ producto_id │ cantidad │ ├─────────────┼───────────┼────────┼─────────────┼──────────┤ │ Ana Torres │ 1 │ 150.50 │ 3 │ 2 │ │ Ana Torres │ 1 │ 150.50 │ 7 │ 1 │ ← pedido 1: 2 lineas │ Ana Torres │ 4 │ 89.99 │ 1 │ 3 │ │ Ana Torres │ 4 │ 89.99 │ 5 │ 1 │ ← pedido 4: 2 lineas │ Ana Torres │ 7 │ 320.00 │ 2 │ 1 │ │ Ana Torres │ 7 │ 320.00 │ 8 │ 2 │ ← pedido 7: 2 lineas └─────────────┴───────────┴────────┴─────────────┴──────────┘
3 pedidos × 2 detalles cada uno = 6 filas. El total de cada pedido se REPITE por cada linea de detalle.Observa que p.total aparece repetido. El pedido 1 tiene total = 150.50, pero esa fila aparece 2 veces (una por cada producto en ese pedido). Esto es correcto en el resultado del JOIN, pero se convierte en problema cuando haces calculos.
SUM inflado: el error clasico
¿Que pasa si sumas p.total en la consulta anterior?
-- INCORRECTO: SUM inflada por duplicadosSELECT c.nombre, SUM(p.total) AS gasto_totalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idWHERE c.nombre = 'Ana Torres'GROUP BY c.nombre; Resultado INCORRECTO ┌─────────────┬─────────────┐ │ nombre │ gasto_total │ ├─────────────┼─────────────┤ │ Ana Torres │ 1120.98 │ ← INCORRECTO! └─────────────┴─────────────┘
Lo que SUM esta sumando: 150.50 + 150.50 + 89.99 + 89.99 + 320.00 + 320.00 = 1120.98
El valor correcto seria: 150.50 + 89.99 + 320.00 = 560.49Cada total se sumo tantas veces como lineas de detalle tiene ese pedido. El resultado esta duplicado (en este caso, exactamente el doble porque cada pedido tenia 2 detalles).
Regla de oro
Cuando haces JOIN entre tablas con relacion uno-a-muchos y luego usas SUM o COUNT, verifica que no estas sumando valores de la tabla ‘uno’ que se repiten por la tabla ‘muchos’. Si un pedido aparece N veces en el resultado (por tener N detalles), SUM(p.total) sumara ese total N veces.
Como corregirlo
Opcion 1: Quitar el JOIN que causa la multiplicacion (si no lo necesitas)
-- CORRECTO: si solo necesitas el total por cliente, no necesitas detalle_pedidosSELECT c.nombre, SUM(p.total) AS gasto_totalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idWHERE c.nombre = 'Ana Torres'GROUP BY c.nombre;Opcion 2: Usar COUNT(DISTINCT) y SUM sobre valores unicos
-- CORRECTO: contar pedidos unicos con DISTINCTSELECT c.nombre, COUNT(DISTINCT p.id) AS num_pedidos, -- Para SUM necesitamos otra estrategia (ver opcion 3) COUNT(*) AS filas_en_resultadoFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idGROUP BY c.nombre;SUM(DISTINCT) no es la solucion
Podrias pensar que SUM(DISTINCT p.total) resuelve el problema. No siempre. Si dos pedidos tienen el mismo total (por ejemplo, ambos son 150.50), SUM(DISTINCT) contaria ese valor una sola vez en lugar de dos, dandote un resultado menor al correcto. DISTINCT elimina duplicados de valor, no duplicados de fila.
Opcion 3: Pre-agregar con una subconsulta o CTE (la solucion mas segura)
-- CORRECTO: primero calcula totales por cliente, luego haz JOINWITH totales_cliente AS ( SELECT cliente_id, COUNT(*) AS num_pedidos, SUM(total) AS gasto_total FROM pedidos GROUP BY cliente_id)SELECT c.nombre, tc.num_pedidos, tc.gasto_totalFROM clientes cINNER JOIN totales_cliente tc ON c.id = tc.cliente_idORDER BY tc.gasto_total DESC;Al pre-agregar en el CTE, cada cliente aparece una sola vez en totales_cliente, y el JOIN posterior no genera duplicados.
Como detectar que tienes duplicados
Antes de confiar en cualquier SUM o COUNT, haz estas verificaciones:
-- Verificacion rapida: ¿hay mas filas de las esperadas?-- Si tienes 20 pedidos pero tu JOIN devuelve 50 filas, hay multiplicacion.SELECT COUNT(*) AS filas_totalesFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_id;
-- Compara con COUNT(DISTINCT)SELECT COUNT(*) AS filas_totales, COUNT(DISTINCT p.id) AS pedidos_unicos, COUNT(DISTINCT c.id) AS clientes_unicosFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_id;-- Si filas_totales > pedidos_unicos, hay multiplicacion-- Revisa el resultado crudo con LIMIT antes de agregarSELECT c.nombre, p.id AS pedido_id, p.total, dp.id AS detalle_idFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idORDER BY c.nombre, p.idLIMIT 20;-- Busca filas donde pedido_id y total se repitenHabito de verificacion
Antes de agregar SUM() o COUNT(*) a una consulta con multiples JOINs, siempre ejecuta primero el SELECT sin agregacion y con LIMIT para ver las filas crudas. Asi puedes detectar visualmente si hay filas multiplicadas.
Errores comunes con JOINs
1. Olvidar la clausula ON
-- PELIGRO: sin ON, esto genera un producto cartesiano-- Si tienes 100 clientes y 500 pedidos, obtienes 50,000 filas!SELECT c.nombre, p.totalFROM clientes cINNER JOIN pedidos p;-- Falta: ON c.id = p.cliente_idProducto cartesiano accidental
Si olvidas el ON, cada fila de una tabla se combina con TODAS las filas de la otra. Con tablas de miles de filas, esto puede colgar tu base de datos. Siempre verifica que tu JOIN tenga una clausula ON.
2. Columnas ambiguas
-- ERROR: "id" existe en ambas tablas. Cual quieres?SELECT id, nombreFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_id;
-- CORRECTO: especifica la tablaSELECT c.id, c.nombre, p.id AS pedido_idFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_id;3. JOIN en la columna equivocada
-- INCORRECTO: esto compara IDs que no estan relacionadosSELECT *FROM clientes cINNER JOIN productos pr ON c.id = pr.id;-- Esto "funciona" pero no tiene sentido logico
-- CORRECTO: usa las relaciones reales de tu modeloSELECT *FROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_id;4. LEFT JOIN que se convierte en INNER JOIN
-- INCORRECTO: el WHERE anula el LEFT JOINSELECT c.nombre, p.total, p.estadoFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idWHERE p.estado = 'completado';-- Clientes sin pedidos completados desaparecen-- porque p.estado es NULL para ellos, y NULL != 'completado'
-- CORRECTO: pon la condicion en el ONSELECT c.nombre, p.total, p.estadoFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_id AND p.estado = 'completado';-- Clientes sin pedidos completados aparecen con NULLsEjemplo completo: consulta multi-JOIN
Vamos a armar una consulta que conecte varias tablas para obtener un informe completo:
-- Informe detallado de ventas: que compro cada clienteSELECT c.nombre AS cliente, c.ciudad, p.id AS pedido_id, p.fecha, pr.nombre AS producto, pr.categoria, dp.cantidad, dp.precio_unitario, (dp.cantidad * dp.precio_unitario) AS subtotalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idINNER JOIN productos pr ON dp.producto_id = pr.idWHERE p.estado = 'completado'ORDER BY c.nombre, p.fecha DESC;Y un resumen por cliente usando un CTE para evitar el problema de duplicados:
-- Total gastado por cada cliente (sin riesgo de duplicados)WITH resumen_pedidos AS ( SELECT cliente_id, COUNT(*) AS num_pedidos, SUM(total) AS gasto_total, ROUND(AVG(total), 2) AS pedido_promedio FROM pedidos WHERE estado = 'completado' GROUP BY cliente_id)SELECT c.nombre AS cliente, c.ciudad, rp.num_pedidos, rp.gasto_total, rp.pedido_promedioFROM clientes cINNER JOIN resumen_pedidos rp ON c.id = rp.cliente_idWHERE rp.gasto_total > 500ORDER BY rp.gasto_total DESC;Rendimiento de los JOINs
Complejidad de los JOINs
En el peor caso, un JOIN entre una tabla de n filas y otra de m filas es O(n * m) (nested loop: comparar cada fila con cada fila). Con tablas de 10,000 filas cada una, eso podria ser 100 millones de comparaciones. Por eso los indices son tan importantes.
Estrategias de JOIN que usa PostgreSQL
PostgreSQL elige automaticamente entre tres estrategias:
1. Nested Loop Join — Para cada fila de la tabla A, busca coincidencias en la tabla B.
- Sin indice: O(n * m) — lento
- Con indice: O(n * log m) — mucho mejor
- Bueno cuando una tabla es pequena
2. Hash Join — Construye una tabla hash con una tabla y busca las coincidencias de la otra.
- Complejidad: O(n + m) — muy eficiente
- Necesita memoria para la tabla hash
- Bueno cuando ambas tablas son grandes
3. Merge Join — Ordena ambas tablas y las recorre en paralelo.
- Complejidad: O(n log n + m log m) para ordenar, luego O(n + m) para el merge
- Bueno cuando los datos ya estan ordenados (por un indice)
-- Puedes ver que estrategia elige PostgreSQL con EXPLAINEXPLAIN SELECT c.nombre, p.totalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_id;Lo mas importante para JOINs rapidos
Asegurate de que las columnas en tu clausula ON tengan indices. Las claves primarias (id) ya tienen indice automaticamente. Las claves foraneas (cliente_id, pedido_id, producto_id) deberias agregarles un indice si no lo tienen. Esto puede hacer la diferencia entre un JOIN que tarda milisegundos y uno que tarda minutos.
Consejo practico: minimiza las filas antes del JOIN
-- PostgreSQL generalmente optimiza esto automaticamente,-- pero reducir las filas antes del JOIN siempre ayuda.SELECT c.nombre, p.totalFROM pedidos pINNER JOIN clientes c ON p.cliente_id = c.idWHERE p.fecha >= '2024-01-01' AND p.estado = 'completado';Ejercicios
Ejercicio 1: Muestra el nombre de cada cliente junto con la fecha y total de sus pedidos. Usa INNER JOIN.
Ver solucion
SELECT c.nombre AS cliente, p.fecha, p.totalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idORDER BY c.nombre, p.fecha;Ejercicio 2: Muestra TODOS los clientes y cuantos pedidos tiene cada uno (incluyendo los que tienen 0 pedidos).
Ver solucion
SELECT c.nombre AS cliente, COUNT(p.id) AS num_pedidosFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.id, c.nombreORDER BY num_pedidos DESC;Usamos LEFT JOIN para incluir clientes sin pedidos, y COUNT(p.id) en vez de COUNT(*) para que los clientes sin pedidos tengan 0 (porque p.id sera NULL y COUNT no cuenta NULLs).
Ejercicio 3: Encuentra todos los productos que nunca se han vendido (no aparecen en detalle_pedidos).
Ver solucion
SELECT pr.nombre, pr.precio, pr.categoriaFROM productos prLEFT JOIN detalle_pedidos dp ON pr.id = dp.producto_idWHERE dp.id IS NULL;Ejercicio 4: Muestra cada empleado junto con el nombre de su jefe. Incluye empleados sin jefe (mostrando NULL).
Ver solucion
SELECT e.nombre AS empleado, e.departamento, e.salario, j.nombre AS jefeFROM empleados eLEFT JOIN empleados j ON e.jefe_id = j.idORDER BY j.nombre NULLS FIRST, e.nombre;Ejercicio 5: Muestra un informe con: nombre del cliente, nombre del producto, cantidad y precio unitario, para todos los pedidos con estado ‘completado’. Necesitas conectar 4 tablas.
Ver solucion
SELECT c.nombre AS cliente, pr.nombre AS producto, dp.cantidad, dp.precio_unitario, (dp.cantidad * dp.precio_unitario) AS subtotalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idINNER JOIN productos pr ON dp.producto_id = pr.idWHERE p.estado = 'completado'ORDER BY c.nombre, pr.nombre;Ejercicio 6: Para cada categoria de producto, muestra la cantidad total de unidades vendidas. Incluye categorias con 0 ventas.
Ver solucion
SELECT pr.categoria, COALESCE(SUM(dp.cantidad), 0) AS unidades_vendidasFROM productos prLEFT JOIN detalle_pedidos dp ON pr.id = dp.producto_idGROUP BY pr.categoriaORDER BY unidades_vendidas DESC;Ejercicio 7: Encuentra los clientes que han gastado mas de 1000 en total, mostrando su nombre, ciudad, numero de pedidos y gasto total. Solo incluye pedidos completados.
Ver solucion
SELECT c.nombre, c.ciudad, COUNT(p.id) AS num_pedidos, SUM(p.total) AS gasto_totalFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idWHERE p.estado = 'completado'GROUP BY c.id, c.nombre, c.ciudadHAVING SUM(p.total) > 1000ORDER BY gasto_total DESC;Esta consulta combina JOIN, WHERE, GROUP BY, HAVING y ORDER BY.
Ejercicio 8 (Desafio): Quieres saber cuantos productos distintos ha comprado cada cliente y el total gastado. Pero cuidado: si haces JOIN de pedidos con detalle_pedidos, los totales se pueden inflar. Usa un CTE para evitar el problema.
Ver solucion
-- Paso 1: total gastado por cliente (sin duplicados)WITH gasto_cliente AS ( SELECT cliente_id, SUM(total) AS gasto_total FROM pedidos WHERE estado = 'completado' GROUP BY cliente_id),-- Paso 2: productos distintos por clienteproductos_cliente AS ( SELECT p.cliente_id, COUNT(DISTINCT dp.producto_id) AS productos_distintos FROM pedidos p INNER JOIN detalle_pedidos dp ON p.id = dp.pedido_id WHERE p.estado = 'completado' GROUP BY p.cliente_id)SELECT c.nombre, c.ciudad, pc.productos_distintos, gc.gasto_totalFROM clientes cINNER JOIN gasto_cliente gc ON c.id = gc.cliente_idINNER JOIN productos_cliente pc ON c.id = pc.cliente_idORDER BY gc.gasto_total DESC;Al pre-agregar en CTEs separados, cada cliente aparece una sola vez en cada CTE. El JOIN final no genera duplicados y los totales son correctos.
Subconsultas y CTEs
Hasta ahora, todas nuestras consultas han sido “planas”: un solo SELECT que lee de una o varias tablas. Pero SQL es mucho mas poderoso que eso. Podemos anidar consultas dentro de otras consultas. A esto le llamamos subconsultas (o subqueries).
Y cuando las subconsultas se vuelven complicadas de leer, tenemos una herramienta elegante: las CTEs (Common Table Expressions), que nos permiten escribir consultas complejas de forma clara y organizada.
Que es una subconsulta?
Una subconsulta es simplemente un SELECT dentro de otro SELECT. Va entre parentesis y puede aparecer en diferentes partes de tu consulta: en el WHERE, en el FROM, o incluso en el SELECT.
Pensalo asi: en lugar de escribir un valor fijo, le decis a SQL “calcula este valor por mi con otra consulta”.
Subconsultas en WHERE
Este es el uso mas comun. Vamos a ver las diferentes formas.
Subconsulta escalar (devuelve un solo valor)
Quiero ver todos los productos que cuestan mas que el precio promedio:
SELECT nombre, precioFROM productosWHERE precio > (SELECT AVG(precio) FROM productos);Lo que pasa aqui es que PostgreSQL primero ejecuta la subconsulta interna (SELECT AVG(precio) FROM productos), obtiene un numero (digamos 45.50), y luego ejecuta la consulta externa como si dijera WHERE precio > 45.50.
Nota
Una subconsulta escalar es la que devuelve exactamente una fila y una columna (un solo valor). Si devuelve mas de una fila, PostgreSQL va a tirar un error.
Subconsulta con IN (devuelve una lista)
Quiero ver los clientes que han hecho al menos un pedido:
SELECT nombre, emailFROM clientesWHERE id IN (SELECT DISTINCT cliente_id FROM pedidos);La subconsulta devuelve una lista de IDs, y IN verifica si el id del cliente esta en esa lista.
Otro ejemplo: productos que nunca se han vendido:
SELECT nombre, precioFROM productosWHERE id NOT IN ( SELECT DISTINCT producto_id FROM detalle_pedidos);Cuidado con NOT IN y NULLs
Si la subconsulta dentro de NOT IN devuelve algun valor NULL, el resultado completo sera vacio. Esto es una trampa clasica de SQL. Si hay riesgo de NULLs, usa NOT EXISTS en su lugar (lo vemos a continuacion).
Subconsulta con EXISTS
EXISTS verifica si una subconsulta devuelve al menos una fila. No le importa que datos devuelve, solo si hay resultados o no.
Clientes que tienen al menos un pedido:
SELECT c.nombre, c.emailFROM clientes cWHERE EXISTS ( SELECT 1 FROM pedidos p WHERE p.cliente_id = c.id);Y lo contrario: clientes sin ningun pedido:
SELECT c.nombre, c.emailFROM clientes cWHERE NOT EXISTS ( SELECT 1 FROM pedidos p WHERE p.cliente_id = c.id);Tip
El SELECT 1 dentro de EXISTS es una convencion. Podrias poner SELECT * o SELECT 42 y funcionaria igual. PostgreSQL solo verifica si hay filas, no le importa que columnas selecciones.
Subconsultas en FROM (tablas derivadas)
Podemos usar una subconsulta como si fuera una tabla temporal. Esto se llama tabla derivada y siempre necesita un alias.
Ejemplo: quiero ver el total gastado por cliente, pero solo los que gastaron mas de 500:
SELECT sub.nombre, sub.total_gastadoFROM ( SELECT c.nombre, SUM(p.total) AS total_gastado FROM clientes c JOIN pedidos p ON c.id = p.cliente_id GROUP BY c.nombre) AS subWHERE sub.total_gastado > 500ORDER BY sub.total_gastado DESC;Nota
Si, esto tambien se puede hacer con HAVING. Pero las tablas derivadas son utiles cuando necesitas hacer operaciones adicionales sobre resultados ya agrupados.
Subconsultas en SELECT (subconsultas escalares)
Podemos calcular un valor en cada fila usando una subconsulta en la lista de columnas:
SELECT p.nombre, p.precio, (SELECT AVG(precio) FROM productos) AS precio_promedio, p.precio - (SELECT AVG(precio) FROM productos) AS diferenciaFROM productos pORDER BY diferencia DESC;Esto agrega dos columnas calculadas: el precio promedio general y cuanto se aleja cada producto de ese promedio.
Otro ejemplo mas util: para cada cliente, cuantos pedidos tiene:
SELECT c.nombre, c.ciudad, (SELECT COUNT(*) FROM pedidos p WHERE p.cliente_id = c.id) AS total_pedidosFROM clientes cORDER BY total_pedidos DESC;Subconsultas correlacionadas vs no correlacionadas
Esta distincion es clave para entender el rendimiento.
No correlacionada: la subconsulta se ejecuta una sola vez y su resultado se reutiliza.
-- Se ejecuta UNA vez: calcula el promedio y listoSELECT nombre, precioFROM productosWHERE precio > (SELECT AVG(precio) FROM productos);Correlacionada: la subconsulta se ejecuta una vez por cada fila de la consulta externa, porque depende de un valor de esa fila.
-- Se ejecuta UNA VEZ POR CADA CLIENTESELECT c.nombre, (SELECT COUNT(*) FROM pedidos p WHERE p.cliente_id = c.id) AS total_pedidosFROM clientes c;Cuidado con subconsultas correlacionadas
Una subconsulta correlacionada puede tener complejidad O(n * m) donde n es el numero de filas de la consulta externa y m el costo de la subconsulta interna. Si la tabla clientes tiene 10,000 filas y pedidos tiene 100,000 filas, esta ejecutando la subconsulta interna 10,000 veces. Muchas veces un JOIN con GROUP BY logra el mismo resultado de forma mucho mas eficiente.
El mismo resultado con JOIN (generalmente mas rapido):
SELECT c.nombre, COUNT(p.id) AS total_pedidosFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombreORDER BY total_pedidos DESC;Common Table Expressions (CTEs)
Las CTEs son una forma de darle nombre temporal a una subconsulta para usarla mas adelante. Se definen con la palabra clave WITH.
Sintaxis basica
WITH nombre_cte AS ( SELECT ...)SELECT * FROM nombre_cte;Veamos un ejemplo real. Quiero encontrar los clientes VIP (los que gastaron mas de 1000) y ver sus datos:
WITH clientes_vip AS ( SELECT cliente_id, SUM(total) AS total_gastado FROM pedidos GROUP BY cliente_id HAVING SUM(total) > 1000)SELECT c.nombre, c.email, cv.total_gastadoFROM clientes cJOIN clientes_vip cv ON c.id = cv.cliente_idORDER BY cv.total_gastado DESC;Comparalo con la version sin CTE:
SELECT c.nombre, c.email, sub.total_gastadoFROM clientes cJOIN ( SELECT cliente_id, SUM(total) AS total_gastado FROM pedidos GROUP BY cliente_id HAVING SUM(total) > 1000) sub ON c.id = sub.cliente_idORDER BY sub.total_gastado DESC;Ambas hacen lo mismo, pero la version con CTE es mas facil de leer porque le diste un nombre descriptivo (clientes_vip) a la subconsulta.
Por que las CTEs mejoran la legibilidad?
Imagina que tenes una consulta compleja con subconsultas anidadas tres niveles. Es una pesadilla de leer. Con CTEs, podes descomponer la logica paso a paso:
-- Paso 1: calcular ventas por productoWITH ventas_por_producto AS ( SELECT dp.producto_id, SUM(dp.cantidad) AS total_vendido, SUM(dp.cantidad * dp.precio_unitario) AS ingresos FROM detalle_pedidos dp GROUP BY dp.producto_id),-- Paso 2: clasificar productosproductos_clasificados AS ( SELECT p.nombre, p.categoria, vp.total_vendido, vp.ingresos, CASE WHEN vp.total_vendido > 100 THEN 'Estrella' WHEN vp.total_vendido > 50 THEN 'Popular' ELSE 'Normal' END AS clasificacion FROM productos p JOIN ventas_por_producto vp ON p.id = vp.producto_id)-- Paso 3: consulta finalSELECT clasificacion, COUNT(*) AS cantidad, SUM(ingresos) AS ingresos_totalesFROM productos_clasificadosGROUP BY clasificacionORDER BY ingresos_totales DESC;Cada CTE es un “paso” con nombre claro. Es como escribir un programa paso a paso en lugar de meter todo en una sola linea.
Multiples CTEs en una consulta
Como viste en el ejemplo anterior, podes definir varias CTEs separadas por comas. Cada una puede referenciar a las anteriores:
WITHpedidos_recientes AS ( SELECT * FROM pedidos WHERE fecha >= CURRENT_DATE - INTERVAL '30 days'),clientes_activos AS ( SELECT DISTINCT cliente_id FROM pedidos_recientes),resumen AS ( SELECT c.ciudad, COUNT(*) AS clientes_activos FROM clientes c JOIN clientes_activos ca ON c.id = ca.cliente_id GROUP BY c.ciudad)SELECT * FROM resumen ORDER BY clientes_activos DESC;Regla de oro
Si tu consulta tiene mas de 2 subconsultas anidadas, probablemente deberia usar CTEs. Tu yo del futuro (y tus companeros) te lo van a agradecer.
Rendimiento de CTEs en PostgreSQL
CTEs materializadas vs no materializadas
Antes de PostgreSQL 12, las CTEs siempre se materializaban: PostgreSQL ejecutaba la CTE, guardaba el resultado en memoria, y luego la consulta principal leia de ahi. Esto podia ser mas lento porque el optimizador no podia “empujar” filtros dentro de la CTE.
Desde PostgreSQL 12, si la CTE se usa solo una vez y no es recursiva, PostgreSQL puede hacer inline de la CTE (no materializarla), permitiendo al optimizador aplicar filtros y optimizaciones.
Podes controlar esto manualmente:
-- Forzar materializacion (util si la CTE se usa muchas veces)WITH datos AS MATERIALIZED ( SELECT * FROM productos WHERE precio > 100)SELECT * FROM datos WHERE categoria = 'Electronica';
-- Forzar inline (util para que el optimizador pueda optimizar)WITH datos AS NOT MATERIALIZED ( SELECT * FROM productos WHERE precio > 100)SELECT * FROM datos WHERE categoria = 'Electronica';Cuando usar subconsulta vs JOIN?
| Comando | Descripcion |
|---|---|
| Filtrar por un valor calculado | Subconsulta escalar en WHERE |
| Verificar existencia | EXISTS (generalmente mas rapido que IN) |
| Combinar datos de varias tablas | JOIN |
| Consulta compleja con multiples pasos | CTEs |
| Necesitas el resultado en cada fila | JOIN o subconsulta en SELECT |
| Subconsulta correlacionada costosa | Reescribir como JOIN + GROUP BY |
Tip
No hay una regla absoluta. En muchos casos, PostgreSQL optimiza subconsultas y JOINs de forma similar. Pero como regla general: si podes escribirlo con JOIN y es legible, preferi el JOIN.
Ejercicios
Ejercicio 1: Encontra todos los productos cuyo precio es mayor al precio promedio de su misma categoria. (Pista: necesitas una subconsulta correlacionada).
SELECT nombre, precio, categoriaFROM productos pWHERE precio > ( SELECT AVG(precio) FROM productos WHERE categoria = p.categoria);Ejercicio 2: Usa EXISTS para encontrar las categorias que tienen al menos un producto con stock menor a 10.
SELECT DISTINCT p.categoriaFROM productos pWHERE EXISTS ( SELECT 1 FROM productos p2 WHERE p2.categoria = p.categoria AND p2.stock < 10);Ejercicio 3: Usando una CTE, calcula el total de ventas por cliente y muestra solo los que estan por encima del promedio de todos los clientes.
WITH ventas_cliente AS ( SELECT cliente_id, SUM(total) AS total_ventas FROM pedidos GROUP BY cliente_id)SELECT c.nombre, vc.total_ventasFROM clientes cJOIN ventas_cliente vc ON c.id = vc.cliente_idWHERE vc.total_ventas > (SELECT AVG(total_ventas) FROM ventas_cliente)ORDER BY vc.total_ventas DESC;Ejercicio 4: Escribe una consulta con multiples CTEs que: (1) calcule las ventas totales por producto, (2) identifique los productos del top 3, y (3) muestre los clientes que compraron esos productos.
WITH ventas_producto AS ( SELECT producto_id, SUM(cantidad * precio_unitario) AS total_ventas FROM detalle_pedidos GROUP BY producto_id),top_productos AS ( SELECT producto_id FROM ventas_producto ORDER BY total_ventas DESC LIMIT 3),clientes_top AS ( SELECT DISTINCT p.cliente_id FROM pedidos p JOIN detalle_pedidos dp ON p.id = dp.pedido_id WHERE dp.producto_id IN (SELECT producto_id FROM top_productos))SELECT c.nombre, c.emailFROM clientes cJOIN clientes_top ct ON c.id = ct.cliente_id;Ejercicio 5: Reescribi la siguiente subconsulta correlacionada como un JOIN con GROUP BY. Compara mentalmente cual seria mas eficiente:
-- Version original (subconsulta correlacionada)SELECT e.nombre, e.departamento, (SELECT COUNT(*) FROM empleados e2 WHERE e2.departamento = e.departamento) AS total_deptoFROM empleados e;
-- Tu version con JOIN:SELECT e.nombre, e.departamento, d.total_deptoFROM empleados eJOIN ( SELECT departamento, COUNT(*) AS total_depto FROM empleados GROUP BY departamento) d ON e.departamento = d.departamento;Ejercicio 6: Encontra los empleados cuyo salario es el mas alto dentro de su departamento. Resolverlo de dos formas: con subconsulta correlacionada y con CTE.
-- Con subconsulta correlacionadaSELECT nombre, departamento, salarioFROM empleados eWHERE salario = ( SELECT MAX(salario) FROM empleados WHERE departamento = e.departamento);
-- Con CTEWITH max_por_depto AS ( SELECT departamento, MAX(salario) AS max_salario FROM empleados GROUP BY departamento)SELECT e.nombre, e.departamento, e.salarioFROM empleados eJOIN max_por_depto m ON e.departamento = m.departamento AND e.salario = m.max_salario;Funciones y expresiones
SQL no es solo para filtrar y unir tablas. Tambien tiene un monton de funciones incorporadas que te permiten transformar texto, trabajar con fechas, hacer calculos matematicos y manejar casos especiales. En este modulo vamos a explorar las funciones y expresiones mas utiles de PostgreSQL.
Funciones de texto (strings)
PostgreSQL tiene un arsenal completo de funciones para manipular texto. Estas son las mas usadas:
| Comando | Descripcion |
|---|---|
| UPPER(texto) | Convierte a mayusculas |
| LOWER(texto) | Convierte a minusculas |
| TRIM(texto) | Elimina espacios al inicio y final |
| LENGTH(texto) | Devuelve la cantidad de caracteres |
| SUBSTRING(texto, inicio, largo) | Extrae una porcion del texto |
| CONCAT(a, b, ...) | Concatena textos (ignora NULLs) |
| a || b | Concatena textos (NULL si alguno es NULL) |
| REPLACE(texto, buscar, reemplazo) | Reemplaza ocurrencias |
| LEFT(texto, n) | Primeros n caracteres |
| RIGHT(texto, n) | Ultimos n caracteres |
| POSITION(buscar IN texto) | Posicion de un subtexto |
Veamos ejemplos con nuestra base de datos:
-- Nombre del cliente en mayusculasSELECT UPPER(nombre) AS nombre_mayusculas FROM clientes;
-- Email en minusculas (por si acaso)SELECT LOWER(email) AS email_normalizado FROM clientes;
-- Largo del nombre de cada productoSELECT nombre, LENGTH(nombre) AS caracteres FROM productos;
-- Primeras 3 letras de la ciudadSELECT nombre, LEFT(ciudad, 3) AS codigo_ciudad FROM clientes;
-- Concatenar nombre y ciudadSELECT CONCAT(nombre, ' - ', ciudad) AS cliente_info FROM clientes;
-- Lo mismo con el operador ||SELECT nombre || ' (' || ciudad || ')' AS cliente_info FROM clientes;Diferencia entre CONCAT y ||
CONCAT ignora valores NULL (los trata como texto vacio), mientras que || devuelve NULL si cualquiera de los operandos es NULL. Usa CONCAT cuando pueda haber NULLs.
SELECT CONCAT('Hola', NULL, ' mundo'); -- Resultado: 'Hola mundo'SELECT 'Hola' || NULL || ' mundo'; -- Resultado: NULLUn ejemplo mas practico con SUBSTRING y REPLACE:
-- Extraer el dominio del emailSELECT nombre, email, SUBSTRING(email FROM POSITION('@' IN email) + 1) AS dominioFROM clientes;
-- Reemplazar texto en nombres de productosSELECT REPLACE(nombre, 'Premium', 'Pro') AS nombre_nuevoFROM productosWHERE nombre LIKE '%Premium%';STRING_AGG: concatenar valores de multiples filas
STRING_AGG combina valores de varias filas en un solo texto, separados por un delimitador. Es el equivalente de GROUP_CONCAT en MySQL.
-- Ciudades de todos los clientes en una sola lineaSELECT STRING_AGG(DISTINCT ciudad, ', ') AS ciudadesFROM clientes;-- Resultado: 'Antofagasta, Concepcion, Santiago, Temuco, Valparaiso'Combinado con GROUP BY, es muy util para crear listas por grupo:
-- Productos que compro cada cliente (una linea por cliente)SELECT c.nombre, STRING_AGG(DISTINCT pr.nombre, ', ' ORDER BY pr.nombre) AS productos_compradosFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idINNER JOIN productos pr ON dp.producto_id = pr.idGROUP BY c.id, c.nombre;-- Empleados por departamentoSELECT departamento, STRING_AGG(nombre, ', ' ORDER BY nombre) AS empleadosFROM empleadosGROUP BY departamento;-- Ejemplo: 'Ventas' | 'Ana Torres, Carlos Diaz, Maria Lopez'ORDER BY dentro de STRING_AGG
Puedes usar ORDER BY dentro de STRING_AGG para controlar el orden de los valores concatenados. Tambien puedes usar DISTINCT para eliminar duplicados.
-- Categorias de productos que ha comprado cada cliente, sin repetirSELECT c.nombre, STRING_AGG(DISTINCT pr.categoria, ' | ' ORDER BY pr.categoria) AS categoriasFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idINNER JOIN productos pr ON dp.producto_id = pr.idGROUP BY c.id, c.nombre;-- Ejemplo: 'Ana Torres' | 'Accesorios | Electronica | Muebles'Funciones de fecha y hora
Trabajar con fechas es algo que vas a hacer constantemente. PostgreSQL tiene funciones excelentes para esto.
| Comando | Descripcion |
|---|---|
| NOW() | Fecha y hora actual (con timezone) |
| CURRENT_DATE | Solo la fecha de hoy |
| CURRENT_TIME | Solo la hora actual |
| AGE(fecha) | Diferencia entre hoy y esa fecha |
| AGE(fecha1, fecha2) | Diferencia entre dos fechas |
| EXTRACT(campo FROM fecha) | Extrae una parte (year, month, day, etc.) |
| DATE_TRUNC(precision, fecha) | Trunca a una precision (month, year, etc.) |
| fecha + INTERVAL '...' | Suma un intervalo a una fecha |
Vamos a ver esto en accion:
-- Fecha y hora actualSELECT NOW(); -- 2026-03-28 14:30:00.123456-03SELECT CURRENT_DATE; -- 2026-03-28SELECT CURRENT_TIME; -- 14:30:00.123456-03
-- Hace cuanto se registro cada cliente?SELECT nombre, fecha_registro, AGE(fecha_registro) AS antiguedadFROM clientes;-- Resultado: '2 years 3 mons 15 days'
-- Extraer partes de una fechaSELECT nombre, fecha_registro, EXTRACT(YEAR FROM fecha_registro) AS anio, EXTRACT(MONTH FROM fecha_registro) AS mes, EXTRACT(DOW FROM fecha_registro) AS dia_semana -- 0=domingo, 6=sabadoFROM clientes;
-- Ventas por mes usando DATE_TRUNCSELECT DATE_TRUNC('month', fecha) AS mes, COUNT(*) AS cantidad_pedidos, SUM(total) AS ventas_totalesFROM pedidosGROUP BY DATE_TRUNC('month', fecha)ORDER BY mes;DATE_TRUNC es tu mejor amigo
DATE_TRUNC es increiblemente util para agrupar por periodos de tiempo. Trunca la fecha a la precision que le indiques:
DATE_TRUNC('year', '2026-03-28') -- 2026-01-01DATE_TRUNC('month', '2026-03-28') -- 2026-03-01DATE_TRUNC('week', '2026-03-28') -- 2026-03-23 (inicio de semana)DATE_TRUNC('day', NOW()) -- 2026-03-28 00:00:00Intervalos
Los intervalos te permiten sumar o restar tiempo de forma muy expresiva:
-- Pedidos de los ultimos 30 diasSELECT * FROM pedidosWHERE fecha >= CURRENT_DATE - INTERVAL '30 days';
-- Pedidos de los ultimos 3 mesesSELECT * FROM pedidosWHERE fecha >= CURRENT_DATE - INTERVAL '3 months';
-- Clientes registrados en el ultimo anioSELECT nombre, fecha_registroFROM clientesWHERE fecha_registro >= CURRENT_DATE - INTERVAL '1 year';
-- Sumar 2 semanas a una fechaSELECT fecha, fecha + INTERVAL '2 weeks' AS fecha_entregaFROM pedidos;Funciones matematicas
Para cuando necesitas hacer calculos numericos:
| Comando | Descripcion |
|---|---|
| ROUND(n, decimales) | Redondea al numero de decimales |
| CEIL(n) / CEILING(n) | Redondea hacia arriba |
| FLOOR(n) | Redondea hacia abajo |
| ABS(n) | Valor absoluto |
| MOD(a, b) | Resto de la division (a % b) |
| POWER(base, exp) | Potencia |
| SQRT(n) | Raiz cuadrada |
-- Redondear precios a 2 decimalesSELECT nombre, ROUND(precio, 2) AS precio_redondeado FROM productos;
-- Precio con IVA (21%) redondeadoSELECT nombre, precio, ROUND(precio * 1.21, 2) AS precio_con_ivaFROM productos;
-- Redondear hacia arriba (para calcular cajas necesarias, por ejemplo)SELECT nombre, stock, CEIL(stock::numeric / 12) AS cajas_necesariasFROM productos;
-- Valor absoluto de la diferencia con el precio promedioSELECT nombre, precio, ROUND(ABS(precio - (SELECT AVG(precio) FROM productos)), 2) AS diferencia_absFROM productos;CASE WHEN: la expresion condicional
CASE WHEN es como un if/else dentro de SQL. Es una de las expresiones mas utiles que vas a usar.
Forma buscada (searched CASE)
SELECT nombre, precio, CASE WHEN precio < 20 THEN 'Economico' WHEN precio < 50 THEN 'Medio' WHEN precio < 100 THEN 'Premium' ELSE 'Lujo' END AS rango_precioFROM productosORDER BY precio;Se pueden usar en cualquier parte de la consulta, incluyendo ORDER BY y GROUP BY:
-- Agrupar por rango de precioSELECT CASE WHEN precio < 20 THEN 'Economico' WHEN precio < 50 THEN 'Medio' WHEN precio < 100 THEN 'Premium' ELSE 'Lujo' END AS rango, COUNT(*) AS cantidad, ROUND(AVG(precio), 2) AS precio_promedioFROM productosGROUP BY rangoORDER BY precio_promedio;Forma simple (simple CASE)
Cuando comparas contra un solo campo con valores exactos:
SELECT id, total, CASE estado WHEN 'pendiente' THEN 'En espera' WHEN 'enviado' THEN 'En camino' WHEN 'completado' THEN 'Finalizado' ELSE 'Desconocido' END AS estado_legibleFROM pedidos;CASE WHEN para pivotear datos
Un truco muy util es usar CASE con funciones de agregacion para crear reportes tipo tabla cruzada:
SELECT categoria, COUNT(*) AS total_productos, SUM(CASE WHEN stock > 50 THEN 1 ELSE 0 END) AS con_buen_stock, SUM(CASE WHEN stock BETWEEN 10 AND 50 THEN 1 ELSE 0 END) AS stock_medio, SUM(CASE WHEN stock < 10 THEN 1 ELSE 0 END) AS stock_bajoFROM productosGROUP BY categoria;COALESCE: manejo de NULLs
COALESCE devuelve el primer valor que no sea NULL de una lista de argumentos. Es la funcion estrella para manejar valores nulos.
-- Si la ciudad es NULL, mostrar 'Sin ciudad'SELECT nombre, COALESCE(ciudad, 'Sin ciudad') AS ciudadFROM clientes;
-- Encadenar varios valores de respaldoSELECT COALESCE(telefono, email, 'Sin contacto') AS contactoFROM clientes;Un uso muy comun es en calculos donde podria haber NULLs:
-- Asegurar que el total nunca sea NULLSELECT c.nombre, COALESCE(SUM(p.total), 0) AS total_comprasFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombre;Nota
Sin COALESCE, los clientes sin pedidos mostrarian NULL en total_compras. Con COALESCE(..., 0), muestran 0, que es mucho mas claro.
NULLIF
NULLIF(a, b) devuelve NULL si a es igual a b. De lo contrario, devuelve a. Es el opuesto logico de COALESCE.
El uso mas comun es evitar divisiones por cero:
-- Sin NULLIF: si total_vendido es 0, esto da errorSELECT nombre, ingresos / total_vendido AS precio_promedioFROM resumen_ventas;
-- Con NULLIF: si total_vendido es 0, devuelve NULL en lugar de errorSELECT nombre, ingresos / NULLIF(total_vendido, 0) AS precio_promedioFROM resumen_ventas;Ejemplo con nuestra base de datos:
-- Ratio de pedidos completados vs totales (evitando division por cero)SELECT c.nombre, COUNT(p.id) AS total_pedidos, COUNT(CASE WHEN p.estado = 'completado' THEN 1 END) AS completados, ROUND( COUNT(CASE WHEN p.estado = 'completado' THEN 1 END)::numeric / NULLIF(COUNT(p.id), 0) * 100, 1 ) AS porcentaje_completadoFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombre;CAST y :: para conversion de tipos
A veces necesitas convertir un valor de un tipo a otro. PostgreSQL ofrece dos sintaxis:
-- Sintaxis estandar SQLSELECT CAST('42' AS INTEGER);SELECT CAST(precio AS INTEGER) FROM productos;
-- Sintaxis de PostgreSQL (mas corta, mas comun)SELECT '42'::INTEGER;SELECT precio::INTEGER FROM productos;Conversiones comunes:
-- Texto a numeroSELECT '123.45'::NUMERIC;SELECT '42'::INTEGER;
-- Numero a textoSELECT 42::TEXT;SELECT precio::TEXT FROM productos;
-- Texto a fechaSELECT '2026-03-28'::DATE;
-- Division entera vs decimalSELECT 7 / 2; -- Resultado: 3 (division entera!)SELECT 7::NUMERIC / 2; -- Resultado: 3.5 (division decimal)
-- Porcentajes correctosSELECT categoria, COUNT(*) AS cantidad, ROUND(COUNT(*)::NUMERIC / (SELECT COUNT(*) FROM productos) * 100, 1) AS porcentajeFROM productosGROUP BY categoria;La trampa de la division entera
En PostgreSQL, dividir dos enteros da un entero: 5 / 2 = 2, no 2.5. Si necesitas decimales, convierte al menos uno de los operandos: 5::NUMERIC / 2 = 2.5.
Rendimiento: funciones en WHERE
Funciones que matan tus indices
Cuando aplicas una funcion a una columna en el WHERE, PostgreSQL no puede usar el indice de esa columna. Esto se llama un predicado “no sargable”.
-- MAL: no usa el indice en 'nombre' (escaneo completo de tabla)SELECT * FROM clientes WHERE UPPER(nombre) = 'MARIA GARCIA';
-- BIEN: usa ILIKE que puede aprovechar indices con pg_trgmSELECT * FROM clientes WHERE nombre ILIKE 'maria garcia';
-- MAL: no usa el indice en 'fecha_registro'SELECT * FROM clientes WHERE EXTRACT(YEAR FROM fecha_registro) = 2025;
-- BIEN: usa un rango (puede usar el indice)SELECT * FROM clientesWHERE fecha_registro >= '2025-01-01' AND fecha_registro < '2026-01-01';
-- MAL: funcion sobre la columnaSELECT * FROM productos WHERE ROUND(precio, 0) = 50;
-- BIEN: rango equivalenteSELECT * FROM productos WHERE precio >= 49.5 AND precio < 50.5;La regla general: mantene las columnas indexadas “limpias” en el WHERE. Aplica funciones al otro lado de la comparacion, o reestructura la condicion para no necesitarlas.
Ejercicios
Ejercicio 1: Muestra los productos con su nombre en mayusculas, el largo del nombre, y el precio redondeado sin decimales.
SELECT UPPER(nombre) AS nombre_mayusculas, LENGTH(nombre) AS largo_nombre, ROUND(precio, 0) AS precio_redondeadoFROM productos;Ejercicio 2: Calcula cuantos dias hace que se registro cada cliente y muestra solo los que tienen mas de 365 dias.
SELECT nombre, fecha_registro, CURRENT_DATE - fecha_registro AS dias_registradoFROM clientesWHERE CURRENT_DATE - fecha_registro > 365ORDER BY dias_registrado DESC;Ejercicio 3: Crea un reporte de pedidos por mes y anio, mostrando la cantidad y el total. Usa DATE_TRUNC o EXTRACT.
SELECT EXTRACT(YEAR FROM fecha) AS anio, EXTRACT(MONTH FROM fecha) AS mes, COUNT(*) AS cantidad_pedidos, ROUND(SUM(total), 2) AS total_ventasFROM pedidosGROUP BY anio, mesORDER BY anio, mes;Ejercicio 4: Clasifica a los empleados en rangos salariales usando CASE WHEN: “Junior” (menos de 40000), “Semi-Senior” (40000-70000), “Senior” (mas de 70000). Muestra cuantos hay en cada rango.
SELECT CASE WHEN salario < 40000 THEN 'Junior' WHEN salario <= 70000 THEN 'Semi-Senior' ELSE 'Senior' END AS rango, COUNT(*) AS cantidad, ROUND(AVG(salario), 2) AS salario_promedioFROM empleadosGROUP BY rangoORDER BY salario_promedio;Ejercicio 5: Muestra cada cliente con su total de compras. Si nunca compro nada, debe aparecer 0 (no NULL). Usa COALESCE.
SELECT c.nombre, c.ciudad, COALESCE(SUM(p.total), 0) AS total_comprasFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombre, c.ciudadORDER BY total_compras DESC;Ejercicio 6: Genera un reporte que muestre para cada categoria: nombre, cantidad de productos, precio promedio, y el producto mas caro y mas barato (concatenados como texto). Usa varias de las funciones que aprendimos.
WITH stats AS ( SELECT categoria, COUNT(*) AS cantidad, ROUND(AVG(precio), 2) AS precio_promedio, MIN(precio) AS min_precio, MAX(precio) AS max_precio FROM productos GROUP BY categoria)SELECT UPPER(s.categoria) AS categoria, s.cantidad, s.precio_promedio, CONCAT( 'Mas barato: $', s.min_precio::TEXT, ' | Mas caro: $', s.max_precio::TEXT ) AS rango_preciosFROM stats sORDER BY s.precio_promedio DESC;Modificando datos
Hasta ahora nos enfocamos en leer datos con SELECT. Pero en la vida real tambien necesitas agregar, modificar y eliminar datos. Estos son los comandos DML (Data Manipulation Language): INSERT, UPDATE y DELETE.
Este curso se enfoca en consultas, asi que vamos a ser concisos. Pero es fundamental que conozcas estas operaciones y, sobre todo, que aprendas a usarlas de forma segura.
Este modulo modifica datos
Los ejemplos y ejercicios de este modulo insertan, modifican y eliminan filas de tu base de datos. Para experimentar con seguridad, usa transacciones: ejecuta BEGIN; antes de cada ejemplo y ROLLBACK; si quieres deshacer los cambios. Si en algun momento tu base queda en un estado raro, vuelve a ejecutar el script db/init.sql del Modulo 2 para resetearla.
INSERT: agregando datos
Insertar una sola fila
La sintaxis basica:
INSERT INTO productos (nombre, precio, categoria, stock, fecha_creacion)VALUES ('Base para Laptop', 45.99, 'Accesorios', 25, CURRENT_DATE);Nota
La columna id no la incluimos porque es SERIAL (auto-incremental). PostgreSQL le asigna el siguiente valor automaticamente.
Insertar multiples filas
En lugar de ejecutar un INSERT por cada fila, podes insertar varias de una vez:
INSERT INTO productos (nombre, precio, categoria, stock, fecha_creacion)VALUES ('Alfombrilla Escritorio', 35.50, 'Accesorios', 100, CURRENT_DATE), ('Organizador Cables', 14.99, 'Accesorios', 15, CURRENT_DATE), ('Reposamuñecas Teclado', 22.99, 'Muebles', 200, CURRENT_DATE);Inserciones en bulk
Insertar 1000 filas con un solo INSERT ... VALUES (...) de multiples filas es muchisimo mas rapido que ejecutar 1000 sentencias INSERT individuales. Cada INSERT individual tiene overhead de red, parsing y transaccion. Un INSERT masivo hace todo de una vez.
Para volumenes muy grandes (millones de filas), investiga el comando COPY de PostgreSQL, que es aun mas rapido que INSERT masivo.
INSERT con SELECT (copiar datos)
Podes insertar datos que vienen del resultado de una consulta. Primero creamos una tabla destino:
-- Crear una tabla para productos premiumCREATE TABLE productos_premium ( id SERIAL PRIMARY KEY, nombre VARCHAR(100), precio DECIMAL(10,2), categoria VARCHAR(50));
-- Copiar productos con precio mayor a 100INSERT INTO productos_premium (nombre, precio, categoria)SELECT nombre, precio, categoriaFROM productosWHERE precio > 100;Esto es muy util para crear tablas de resumen, copiar datos entre tablas, o poblar tablas temporales.
Copiar una tabla completa
Si quieres crear una copia completa de una tabla (estructura + datos) en un solo paso, usa CREATE TABLE ... AS:
-- Copiar tabla completa con datosCREATE TABLE productos_backup ASSELECT * FROM productos;
-- Copiar solo algunas columnas o filasCREATE TABLE electronica ASSELECT nombre, precio, stockFROM productosWHERE categoria = 'Electronica';CREATE TABLE AS no copia restricciones
CREATE TABLE ... AS copia los datos y los tipos de columna, pero no copia PRIMARY KEY, FOREIGN KEY, NOT NULL, DEFAULT ni indices. Si necesitas esas restricciones, crea la tabla manualmente con CREATE TABLE y luego usa INSERT INTO ... SELECT para copiar los datos.
Tambien existe SELECT INTO, que hace lo mismo pero con otra sintaxis:
-- Equivalente a CREATE TABLE ... ASSELECT * INTO productos_backupFROM productosWHERE stock > 50;INSERT con RETURNING
Una funcionalidad muy util de PostgreSQL: podes obtener los datos insertados de vuelta, incluyendo los valores generados automaticamente como el id.
INSERT INTO clientes (nombre, email, ciudad, fecha_registro)VALUES ('Felipe Rojas', 'felipe@email.com', 'Santiago', CURRENT_DATE)RETURNING id, nombre;Esto devuelve:
id | nombre----+-------------- 11 | Felipe RojasMuy practico cuando necesitas el id recien generado para usarlo en otra operacion (por ejemplo, crear un pedido para ese cliente).
-- Tambien funciona para devolver todas las columnasINSERT INTO productos (nombre, precio, categoria, stock, fecha_creacion)VALUES ('Parlante Portatil', 49.99, 'Electronica', 30, CURRENT_DATE)RETURNING *;UPDATE: modificando datos
Sintaxis basica
UPDATE productosSET precio = 79.99WHERE id = 5;Podes actualizar varias columnas a la vez:
UPDATE productosSET precio = 79.99, stock = stock - 1, nombre = 'Teclado Mecanico RGB'WHERE id = 5;SIEMPRE usa WHERE con UPDATE
Un UPDATE sin WHERE modifica TODAS las filas de la tabla. Esto es casi siempre un error catastrofico:
-- PELIGRO: esto cambia el precio de TODOS los productos!UPDATE productos SET precio = 0;
-- CORRECTO: solo cambia un producto especificoUPDATE productos SET precio = 0 WHERE id = 42;Antes de ejecutar un UPDATE, siempre preguntate: “cuantas filas va a afectar esto?”
UPDATE con expresiones
Podes usar expresiones y calculos en el SET:
-- Aumentar todos los precios un 10%UPDATE productosSET precio = ROUND(precio * 1.10, 2)WHERE categoria = 'Electronica';
-- Reabastecer productos con stock bajoUPDATE productosSET stock = stock + 50WHERE stock < 10;UPDATE con subconsultas
Podes usar subconsultas para calcular el nuevo valor:
-- Igualar el precio al promedio de su categoriaUPDATE productos pSET precio = ( SELECT ROUND(AVG(precio), 2) FROM productos WHERE categoria = p.categoria)WHERE precio < 10;UPDATE con FROM (JOIN)
PostgreSQL permite usar FROM en un UPDATE para hacer JOINs, algo que no todos los motores soportan:
-- Marcar como completados los pedidos pendientes de clientes de SantiagoUPDATE pedidosSET estado = 'completado'FROM clientesWHERE pedidos.cliente_id = clientes.id AND clientes.ciudad = 'Santiago' AND pedidos.estado = 'pendiente';UPDATE con RETURNING
Al igual que INSERT, UPDATE tambien soporta RETURNING:
UPDATE productosSET precio = ROUND(precio * 0.90, 2)WHERE categoria = 'Accesorios'RETURNING id, nombre, precio;Esto te muestra exactamente que filas fueron actualizadas y con que valores.
Actualizar varios registros con valores distintos
A veces necesitas actualizar muchos registros a la vez, pero cada uno con un valor diferente. Por ejemplo, actualizar los precios de varios productos de una sola vez.
Opcion 1: UPDATE con CASE
La forma mas comun es usar CASE dentro del SET:
UPDATE productosSET precio = CASE id WHEN 1 THEN 299.99 WHEN 2 THEN 149.50 WHEN 3 THEN 89.99 WHEN 5 THEN 199.00 ENDWHERE id IN (1, 2, 3, 5);No olvides el WHERE
El WHERE id IN (...) es fundamental. Sin el, las filas que no estan en el CASE reciben valor NULL porque el CASE no tiene ELSE. Siempre filtra solo los IDs que quieres modificar.
Tambien podes actualizar varias columnas a la vez:
UPDATE productosSET precio = CASE id WHEN 1 THEN 299.99 WHEN 2 THEN 149.50 WHEN 3 THEN 89.99 END, stock = CASE id WHEN 1 THEN 50 WHEN 2 THEN 30 WHEN 3 THEN 100 ENDWHERE id IN (1, 2, 3);Opcion 2: UPDATE con FROM VALUES
Para muchos registros, esta sintaxis es mas limpia. Usas una lista de valores como si fuera una tabla temporal:
UPDATE productosSET precio = nuevos.precioFROM (VALUES (1, 299.99), (2, 149.50), (3, 89.99), (5, 199.00)) AS nuevos(id, precio)WHERE productos.id = nuevos.id;Tambien funciona con varias columnas:
UPDATE productosSET precio = nuevos.precio, stock = nuevos.stockFROM (VALUES (1, 299.99, 50), (2, 149.50, 30), (3, 89.99, 100)) AS nuevos(id, precio, stock)WHERE productos.id = nuevos.id;¿CASE o FROM VALUES?
Ambos logran lo mismo. CASE es mas facil de entender para principiantes. FROM VALUES es mas limpio cuando tienes muchos registros o varias columnas que actualizar, y se parece mas a un JOIN.
DELETE: eliminando datos
Sintaxis basica
DELETE FROM productosWHERE id = 42;SIEMPRE usa WHERE con DELETE
Igual que con UPDATE, un DELETE sin WHERE elimina TODAS las filas de la tabla:
-- PELIGRO: esto borra TODOS los productos!DELETE FROM productos;
-- CORRECTO: solo borra productos sin stockDELETE FROM productos WHERE stock = 0;No hay “Ctrl+Z” en SQL. Una vez que eliminas datos, se fueron (a menos que estes en una transaccion que puedas revertir).
DELETE con subconsultas
-- Eliminar pedidos de clientes que ya no existenDELETE FROM pedidosWHERE cliente_id NOT IN ( SELECT id FROM clientes);
-- Mejor con NOT EXISTS (mas seguro con NULLs)DELETE FROM pedidos pWHERE NOT EXISTS ( SELECT 1 FROM clientes c WHERE c.id = p.cliente_id);DELETE con RETURNING
DELETE FROM productosWHERE stock = 0 AND fecha_creacion < CURRENT_DATE - INTERVAL '1 year'RETURNING id, nombre;Esto te muestra que datos eliminaste, util para llevar un log o confirmar la operacion.
TRUNCATE vs DELETE
Si necesitas vaciar una tabla completa, TRUNCATE es mucho mas eficiente que DELETE:
-- Lento: recorre fila por fila, genera logs por cada unaDELETE FROM logs_temporales;
-- Rapido: elimina todas las filas de golpeTRUNCATE TABLE logs_temporales;| Comando | Descripcion |
|---|---|
| Velocidad | DELETE es lento (fila por fila). TRUNCATE es instantaneo. |
| Se puede filtrar? | DELETE acepta WHERE. TRUNCATE no. |
| Dispara triggers? | DELETE si. TRUNCATE no (por defecto). |
| Se puede revertir? | Ambos se pueden revertir dentro de una transaccion. |
| Reinicia secuencias? | DELETE no. TRUNCATE puede con RESTART IDENTITY. |
-- Truncar y reiniciar el contador de IDsTRUNCATE TABLE logs_temporales RESTART IDENTITY;Rendimiento y seguridad
UPDATE/DELETE sin WHERE = desastre de rendimiento
Un UPDATE o DELETE sin WHERE hace un full table scan y modifica cada fila. En una tabla con millones de filas, esto puede tomar minutos u horas, bloquear otras consultas y llenar el log de transacciones. Siempre verifica tu WHERE.
La regla de oro: SELECT antes de UPDATE/DELETE
Antes de ejecutar cualquier UPDATE o DELETE, primero ejecuta la misma consulta como SELECT para verificar que afecta las filas correctas:
-- Paso 1: verificar que vamos a modificarSELECT id, nombre, precio FROM productosWHERE precio < 20;-- Resultado: ver cuantas filas y cuales son. OK, es lo que esperaba.
-- Paso 2: ahora si, ejecutar el DELETEDELETE FROM productosWHERE precio < 20;-- DELETE N (confirma cuantas filas se borraron)Este habito te va a salvar de errores costosos. Todos hemos escuchado (o vivido) historias de un DELETE que borro la tabla entera de produccion.
Otro consejo practico: usa transacciones cuando hagas operaciones peligrosas:
BEGIN; -- Iniciar transaccion
DELETE FROM pedidos WHERE estado = 'pendiente' AND fecha < '2024-06-01';-- Verificar cuantas filas se borraron...-- Si algo salio mal:-- ROLLBACK;
-- Si todo esta bien:COMMIT;ALTER TABLE: modificando la estructura
Los comandos anteriores (INSERT, UPDATE, DELETE) modifican datos. Pero a veces necesitas modificar la estructura de una tabla: agregar columnas, eliminarlas o cambiar sus propiedades. Para eso existe ALTER TABLE.
Agregar una columna
ALTER TABLE productosADD COLUMN descripcion TEXT;La nueva columna se agrega con valor NULL en todas las filas existentes. Podes agregar un valor por defecto:
ALTER TABLE productosADD COLUMN activo BOOLEAN DEFAULT TRUE;Ahora todas las filas existentes tendran activo = TRUE, y las nuevas filas tambien (a menos que especifiques otro valor).
NOT NULL: columnas obligatorias
NOT NULL significa que la columna siempre debe tener un valor — no puede quedar vacia. Es una restriccion fundamental para proteger la integridad de tus datos:
-- Al crear la tablaCREATE TABLE ejemplo ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, -- obligatorio email VARCHAR(100), -- opcional (acepta NULL) activo BOOLEAN NOT NULL DEFAULT TRUE -- obligatorio, con default);Si intentas insertar una fila sin darle valor a una columna NOT NULL (y no tiene default), PostgreSQL da error:
INSERT INTO ejemplo (email) VALUES ('test@email.com');-- ERROR: null value in column "nombre" violates not-null constraintAgregar columna NOT NULL a tabla existente
Si agregas una columna NOT NULL a una tabla que ya tiene datos, debes incluir un DEFAULT. De lo contrario PostgreSQL no sabra que valor asignar a las filas existentes y dara error:
-- ERROR: la tabla tiene filas, no puede ser NULL sin defaultALTER TABLE productos ADD COLUMN codigo VARCHAR(20) NOT NULL;
-- CORRECTO: con default funcionaALTER TABLE productos ADD COLUMN codigo VARCHAR(20) NOT NULL DEFAULT 'SIN-CODIGO';SERIAL: columnas auto-incrementales
SERIAL es un tipo especial que genera un numero entero auto-incremental. Cada vez que insertas una fila, PostgreSQL asigna automaticamente el siguiente numero. Es la forma mas comun de crear IDs:
CREATE TABLE categorias ( id SERIAL PRIMARY KEY, -- 1, 2, 3, 4, ... nombre VARCHAR(50) NOT NULL);
-- No necesitas especificar el id al insertarINSERT INTO categorias (nombre) VALUES ('Electronica'); -- id = 1INSERT INTO categorias (nombre) VALUES ('Muebles'); -- id = 2INSERT INTO categorias (nombre) VALUES ('Accesorios'); -- id = 3¿Que es SERIAL realmente?
SERIAL no es un tipo de dato verdadero. Es un atajo de PostgreSQL que hace 3 cosas por ti:
- Crea la columna como
INTEGER NOT NULL - Crea una secuencia (un contador) asociada a la columna
- Establece el default como
nextval('nombre_secuencia')
Para tablas nuevas, PostgreSQL recomienda usar GENERATED ALWAYS AS IDENTITY como alternativa mas moderna:
CREATE TABLE categorias ( id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY, nombre VARCHAR(50) NOT NULL);Eliminar una columna
ALTER TABLE productosDROP COLUMN descripcion;Eliminar columnas es irreversible
DROP COLUMN elimina la columna y todos sus datos de forma permanente. No hay forma de recuperarla (salvo un backup). Siempre verifica antes de ejecutar.
Si la columna tiene dependencias (foreign keys, vistas, indices), PostgreSQL te dara un error. Podes forzar la eliminacion con CASCADE, pero usalo con cuidado:
-- Eliminar la columna y todo lo que dependa de ellaALTER TABLE productosDROP COLUMN categoria CASCADE;Renombrar una columna
ALTER TABLE productosRENAME COLUMN stock TO cantidad_disponible;Renombrar una tabla
ALTER TABLE productos_backupRENAME TO productos_respaldo;Esto cambia el nombre de la tabla en toda la base de datos. Las foreign keys que apuntan a esta tabla se actualizan automaticamente, pero las consultas guardadas o vistas que la referencian por el nombre antiguo dejaran de funcionar.
Cambiar el tipo de dato
ALTER TABLE productosALTER COLUMN nombre TYPE VARCHAR(200);Conversiones de tipo
No todas las conversiones son posibles. Por ejemplo, podes ampliar un VARCHAR(50) a VARCHAR(200), pero convertir un TEXT con letras a INTEGER va a fallar si hay datos que no son numeros. PostgreSQL te avisara con un error antes de hacer nada.
Resumen de ALTER TABLE
| Comando | Descripcion |
|---|---|
| ADD COLUMN nombre tipo | Agrega una nueva columna a la tabla |
| DROP COLUMN nombre | Elimina una columna y todos sus datos |
| RENAME COLUMN viejo TO nuevo | Cambia el nombre de una columna |
| RENAME TO nuevo_nombre | Cambia el nombre de la tabla |
| ALTER COLUMN nombre TYPE tipo | Cambia el tipo de dato de una columna |
| ALTER COLUMN nombre SET DEFAULT valor | Establece un valor por defecto |
| ALTER COLUMN nombre SET NOT NULL | Hace la columna obligatoria (no acepta NULL) |
| ALTER COLUMN nombre DROP NOT NULL | Permite NULL en la columna |
DROP TABLE: eliminando tablas
Eliminar una tabla
DROP TABLE productos_premium;Esto elimina la tabla completa: estructura, datos, indices, todo. Es irreversible.
DROP TABLE IF EXISTS
Si intentas eliminar una tabla que no existe, PostgreSQL da error. Para evitarlo, usa IF EXISTS:
-- Sin IF EXISTS: da error si la tabla no existeDROP TABLE productos_premium; -- ERROR: table "productos_premium" does not exist
-- Con IF EXISTS: no da error, simplemente no hace nadaDROP TABLE IF EXISTS productos_premium; -- NOTICE: table does not exist, skippingCuando usar IF EXISTS
IF EXISTS es especialmente util en scripts de inicializacion. Es comun ver este patron al inicio de un script que crea tablas:
-- Borrar tablas si existen (para empezar limpio)DROP TABLE IF EXISTS detalle_pedidos;DROP TABLE IF EXISTS pedidos;DROP TABLE IF EXISTS productos;DROP TABLE IF EXISTS clientes;DROP TABLE IF EXISTS empleados;
-- Crear las tablas desde ceroCREATE TABLE clientes ( ... );CREATE TABLE productos ( ... );-- etc.Asi el script se puede ejecutar multiples veces sin errores.
Cuidado con el orden de eliminacion
Si una tabla tiene foreign keys que la referencian, no la podes eliminar directamente. Debes eliminar primero las tablas que dependen de ella, o usar CASCADE:
-- Error: pedidos referencia a clientesDROP TABLE clientes;
-- Opcion 1: eliminar en orden correctoDROP TABLE IF EXISTS detalle_pedidos;DROP TABLE IF EXISTS pedidos;DROP TABLE IF EXISTS clientes;
-- Opcion 2: forzar con CASCADE (elimina las FK automaticamente)DROP TABLE clientes CASCADE;CREATE TABLE IF NOT EXISTS
El complemento de DROP TABLE IF EXISTS. Crea la tabla solo si no existe:
CREATE TABLE IF NOT EXISTS logs ( id SERIAL PRIMARY KEY, mensaje TEXT, fecha TIMESTAMP DEFAULT NOW());Esto es util para scripts que pueden ejecutarse multiples veces sin fallar.
Ejercicios
Ejercicio 1: Inserta 3 nuevos productos en la tabla productos usando un solo INSERT. Usa RETURNING para ver los IDs generados.
INSERT INTO productos (nombre, precio, categoria, stock, fecha_creacion)VALUES ('Adaptador DisplayPort', 18.99, 'Accesorios', 60, CURRENT_DATE), ('Reposamuñecas Gel', 22.50, 'Accesorios', 80, CURRENT_DATE), ('Parlante Portatil', 65.00, 'Electronica', 35, CURRENT_DATE)RETURNING id, nombre, precio;Ejercicio 2: Aumenta un 15% el precio de todos los productos de la categoria ‘Electronica’. Muestra los productos afectados con RETURNING.
UPDATE productosSET precio = ROUND(precio * 1.15, 2)WHERE categoria = 'Electronica'RETURNING id, nombre, precio;Ejercicio 3: Escribe el SELECT que usarias para verificar antes de eliminar todos los pedidos pendientes anteriores a marzo 2024. Luego escribe el DELETE correspondiente.
-- Paso 1: verificarSELECT id, cliente_id, fecha, estadoFROM pedidosWHERE estado = 'pendiente' AND fecha < '2024-03-01';
-- Paso 2: eliminar (solo despues de verificar)DELETE FROM pedidosWHERE estado = 'pendiente' AND fecha < '2024-03-01'RETURNING id;Ejercicio 4: Usa UPDATE para marcar como ‘completado’ todos los pedidos con estado ‘enviado’ cuyo total supere el promedio. (Primero escribe el SELECT de verificacion).
-- VerificacionSELECT p.id, p.total, p.estadoFROM pedidos pWHERE p.estado = 'enviado' AND p.total > (SELECT AVG(total) FROM pedidos);
-- UpdateUPDATE pedidosSET estado = 'completado'WHERE estado = 'enviado' AND total > (SELECT AVG(total) FROM pedidos)RETURNING id, total, estado;Ejercicio 5: Inserta en la tabla pedidos un nuevo pedido para el cliente con email ‘maria@email.com’, usando una subconsulta para obtener su id.
INSERT INTO pedidos (cliente_id, fecha, total, estado)VALUES ( (SELECT id FROM clientes WHERE email = 'maria@email.com'), CURRENT_DATE, 0, 'pendiente')RETURNING *;Ejercicio 6: Agrega una columna telefono VARCHAR(20) a la tabla clientes. Luego actualiza el telefono de Maria Garcia a ‘+56 9 1234 5678’. Finalmente, elimina la columna.
-- Agregar columnaALTER TABLE clientes ADD COLUMN telefono VARCHAR(20);
-- Actualizar un registroUPDATE clientes SET telefono = '+56 9 1234 5678' WHERE nombre = 'Maria Garcia';
-- VerificarSELECT nombre, email, telefono FROM clientes WHERE nombre = 'Maria Garcia';
-- Eliminar columna (cuando ya no la necesites)ALTER TABLE clientes DROP COLUMN telefono;Ejercicio 7: Escribe un script que elimine la tabla productos_premium (si existe) y la vuelva a crear con las columnas: id, nombre, precio y fecha_agregado. Luego inserta los 3 productos mas caros desde la tabla productos.
DROP TABLE IF EXISTS productos_premium;
CREATE TABLE productos_premium ( id SERIAL PRIMARY KEY, nombre VARCHAR(100), precio DECIMAL(10,2), fecha_agregado DATE DEFAULT CURRENT_DATE);
INSERT INTO productos_premium (nombre, precio)SELECT nombre, precioFROM productosORDER BY precio DESCLIMIT 3;Rendimiento y optimizacion
Llegamos al modulo mas importante del curso. En serio. Puedes saber escribir SQL perfecto, pero si tus consultas tardan 30 segundos en una tabla con millones de filas, tienes un problema gordo. En este modulo vas a aprender como piensa PostgreSQL cuando ejecuta tus consultas y, mas importante, como hacer que piense mas rapido.
Como ejecuta PostgreSQL una consulta
Cuando escribes una consulta SQL y presionas Enter, PostgreSQL no la ejecuta directamente. Pasa por varias etapas:
- Parsing: Verifica que tu SQL sea valido sintacticamente. Si escribiste
SLECTen vez deSELECT, aqui muere. - Rewriting: Aplica reglas internas (como expandir vistas).
- Planning/Optimizing: El planificador analiza multiples estrategias para ejecutar tu consulta y elige la que estima que sera mas barata.
- Execution: Ejecuta el plan elegido y te devuelve los resultados.
La etapa clave es la 3. PostgreSQL tiene un optimizador basado en costos: calcula cuanto “costaria” cada estrategia posible y elige la mas barata. Y aqui es donde tu puedes influir enormemente.
Analogia
Imagina que necesitas ir del punto A al punto B en una ciudad. Puedes ir caminando (lento pero seguro), en auto por la autopista (rapido si no hay trafico), o en metro (rapido pero con transbordos). El planificador de PostgreSQL hace exactamente esto: evalua las rutas posibles y elige la mejor segun las condiciones actuales.
EXPLAIN: Tu herramienta de diagnostico
EXPLAIN es el estetoscopio del desarrollador SQL. Te muestra que plan eligio PostgreSQL sin ejecutar la consulta:
EXPLAIN SELECT * FROM productos WHERE precio > 100;Resultado tipico:
Seq Scan on productos (cost=0.00..25.00 rows=500 width=64) Filter: (precio > 100)Vamos a desmenuzar esto:
- Seq Scan on productos: Va a leer la tabla completa, fila por fila (Sequential Scan).
- cost=0.00..25.00: Costo estimado. El primer numero es el costo de arranque, el segundo es el costo total.
- rows=500: Estima que devolvera 500 filas.
- width=64: Cada fila ocupa aproximadamente 64 bytes.
Para ver que realmente pasa (con tiempos reales), usa EXPLAIN ANALYZE:
EXPLAIN ANALYZE SELECT * FROM productos WHERE precio > 100;Seq Scan on productos (cost=0.00..25.00 rows=500 width=64) (actual time=0.015..0.320 rows=487 loops=1) Filter: (precio > 100) Rows Removed by Filter: 513Planning Time: 0.085 msExecution Time: 0.450 msAhora ves datos reales:
- actual time=0.015..0.320: Tardo 0.015 ms en devolver la primera fila y 0.320 ms en total.
- rows=487: Devolvio 487 filas realmente (el estimado era 500, bastante cerca).
- Rows Removed by Filter: 513: Leyo 513 filas que no cumplian el filtro. Eso es trabajo desperdiciado.
- Planning Time: Cuanto tardo en elegir el plan.
- Execution Time: Cuanto tardo en ejecutarlo.
Cuidado con EXPLAIN ANALYZE
EXPLAIN ANALYZE si ejecuta la consulta. Si haces EXPLAIN ANALYZE DELETE FROM clientes;… si, borra todos los clientes. Para consultas destructivas, usa solo EXPLAIN (sin ANALYZE) o envuelve en una transaccion que luego haces rollback:
BEGIN;EXPLAIN ANALYZE DELETE FROM clientes WHERE ciudad = 'Test';ROLLBACK;Tipos de escaneo: como lee PostgreSQL tus datos
Sequential Scan (Seq Scan)
Lee toda la tabla, fila por fila. Es como leer un libro de principio a fin buscando una palabra.
EXPLAIN SELECT * FROM productos;Seq Scan on productos (cost=0.00..22.00 rows=1000 width=64)Para tablas pequenas o cuando necesitas la mayoria de las filas, esto esta bien. El problema es cuando la tabla tiene millones de filas y solo necesitas unas pocas.
Complejidad: O(n) - Tiene que mirar cada fila.
Index Scan
Usa un indice para ir directamente a las filas que necesita. Es como usar el indice de un libro para encontrar un tema especifico.
-- Suponiendo que existe un indice en la columna precioEXPLAIN SELECT * FROM productos WHERE precio = 99.99;Index Scan using idx_productos_precio on productos (cost=0.28..8.30 rows=1 width=64) Index Cond: (precio = 99.99)Mucho mas rapido. En vez de leer 1000 filas, va directo a las que cumplen la condicion.
Complejidad: O(log n) - Busqueda en el arbol del indice.
Index Only Scan
Aun mejor que Index Scan. Si toda la informacion que necesitas esta en el indice, PostgreSQL ni siquiera necesita ir a la tabla:
-- Con un indice en (precio)EXPLAIN SELECT precio FROM productos WHERE precio > 100;Index Only Scan using idx_productos_precio on productos (cost=0.28..12.50 rows=500 width=8) Index Cond: (precio > 100)Complejidad: O(log n + k) donde k es el numero de resultados.
Bitmap Index Scan + Bitmap Heap Scan
Un enfoque hibrido. Primero usa el indice para crear un “mapa de bits” de las paginas que contienen filas relevantes, luego lee esas paginas:
EXPLAIN SELECT * FROM productos WHERE precio BETWEEN 50 AND 150;Bitmap Heap Scan on productos (cost=5.00..20.00 rows=300 width=64) Recheck Cond: (precio >= 50 AND precio <= 150) -> Bitmap Index Scan on idx_productos_precio (cost=0.00..4.93 rows=300 width=0) Index Cond: (precio >= 50 AND precio <= 150)PostgreSQL elige esto cuando hay muchas filas que coinciden pero no tantas como para justificar un Seq Scan completo.
Cuando usa cada tipo de escaneo
- Seq Scan: Tablas pequenas o cuando se necesita >10-15% de las filas.
- Index Scan: Pocas filas coinciden y necesitas columnas que no estan en el indice.
- Index Only Scan: Pocas filas coinciden y todas las columnas estan en el indice.
- Bitmap Scan: Numero moderado de filas coinciden (entre lo que justifica Index Scan y Seq Scan).
Indices: el turbo de tus consultas
Un indice es como el indice al final de un libro. En vez de leer todo el libro para encontrar “PostgreSQL”, vas al indice, buscas la P, y te dice exactamente en que paginas aparece.
En PostgreSQL, el tipo de indice mas comun es el B-tree (arbol balanceado). Imagina un arbol donde:
- La raiz te dice “los valores menores a 500 estan a la izquierda, los mayores a la derecha”
- Cada nivel refina mas la busqueda
- Las hojas contienen los valores reales y un puntero a la fila de la tabla
[500] / \ [200,350] [700,900] / | \ / | \ [filas] ... [filas] ... [filas]Esto permite encontrar cualquier valor en O(log n). En una tabla con 1 millon de filas, un B-tree necesita solo unas 20 comparaciones para encontrar una fila, en vez de revisar el millon completo.
Crear un indice
-- Indice simpleCREATE INDEX idx_productos_precio ON productos(precio);
-- Indice en multiples columnas (compuesto)CREATE INDEX idx_productos_cat_precio ON productos(categoria, precio);
-- Indice unicoCREATE UNIQUE INDEX idx_clientes_email ON clientes(email);Dato
PostgreSQL crea automaticamente un indice para cada PRIMARY KEY y cada restriccion UNIQUE. No necesitas crearlos manualmente.
Cuando los indices ayudan
Los indices son geniales para:
-- Busquedas por igualdadSELECT * FROM clientes WHERE email = 'ana@mail.com';
-- Busquedas por rangoSELECT * FROM productos WHERE precio BETWEEN 10 AND 50;
-- OrdenamientoSELECT * FROM productos ORDER BY precio LIMIT 10;
-- JOINs (en las columnas de union)SELECT c.nombre, p.totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_id;Cuando los indices NO ayudan
-- Tablas muy pequenas (el Seq Scan es mas rapido)SELECT * FROM categorias; -- si tiene 10 filas, un indice estorba
-- Cuando seleccionas la mayoria de las filasSELECT * FROM productos WHERE stock > 0; -- si el 95% tiene stock, no sirve
-- Cuando usas funciones sobre la columna indexadaSELECT * FROM clientes WHERE UPPER(nombre) = 'ANA'; -- NO usa el indice en nombreSELECT * FROM clientes WHERE nombre = 'Ana'; -- SI usa el indice
-- Cuando usas LIKE con comodin al inicioSELECT * FROM productos WHERE nombre LIKE '%laptop%'; -- NO usa indiceSELECT * FROM productos WHERE nombre LIKE 'Laptop%'; -- SI puede usar indiceRegla de oro
Si aplicas una funcion a una columna indexada en el WHERE, el indice no se usa. Esto es uno de los errores mas comunes. En vez de WHERE UPPER(nombre) = 'ANA', crea un indice funcional: CREATE INDEX idx_nombre_upper ON clientes(UPPER(nombre));
Algoritmos de JOIN
Cuando haces un JOIN, PostgreSQL tiene tres estrategias principales:
Nested Loop Join
Para cada fila de la tabla A, recorre todas las filas de la tabla B buscando coincidencias.
Para cada fila en clientes: -- n filas Para cada fila en pedidos: -- m filas Si coincide, emitir filaComplejidad: O(n * m) sin indice, O(n * log m) con indice en la tabla interna.
Es bueno cuando una de las tablas es muy pequena o cuando hay un indice en la columna de JOIN de la tabla interna.
EXPLAIN ANALYZESELECT c.nombre, p.totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_idWHERE c.ciudad = 'Madrid';Nested Loop (cost=0.29..45.50 rows=15 actual time=0.020..0.150) -> Seq Scan on clientes c (cost=0.00..12.00 rows=5 actual time=0.010..0.030) Filter: (ciudad = 'Madrid') -> Index Scan using idx_pedidos_cliente on pedidos p (cost=0.29..6.50 rows=3 actual time=0.010..0.020) Index Cond: (cliente_id = c.id)Solo 5 clientes de Madrid, y para cada uno busca sus pedidos por indice. Rapido.
Hash Join
Construye una tabla hash en memoria con la tabla mas pequena, y luego recorre la tabla grande buscando en el hash:
1. Construir hash de clientes (tabla pequena)2. Para cada fila en pedidos: Buscar en hash si existe cliente_idComplejidad: O(n + m) - Construir el hash es O(n), recorrer la otra tabla es O(m).
EXPLAIN ANALYZESELECT c.nombre, p.totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_id;Hash Join (cost=15.00..52.00 rows=1000 actual time=0.200..1.500) Hash Cond: (p.cliente_id = c.id) -> Seq Scan on pedidos p (cost=0.00..30.00 rows=1000) -> Hash (cost=12.00..12.00 rows=200) -> Seq Scan on clientes c (cost=0.00..12.00 rows=200)Ideal para JOINs grandes donde no hay indice pero una tabla cabe en memoria.
Merge Join
Ordena ambas tablas por la columna de JOIN y luego las recorre en paralelo (como mezclar dos mazos de cartas ya ordenados):
1. Ordenar clientes por id2. Ordenar pedidos por cliente_id3. Recorrer ambas listas en paralelo, emitiendo coincidenciasComplejidad: O(n log n + m log m) por la ordenacion, luego O(n + m) para el merge.
Merge Join (cost=80.00..120.00 rows=1000) Merge Cond: (c.id = p.cliente_id) -> Sort (cost=30.00..32.00 rows=200) Sort Key: c.id -> Seq Scan on clientes c -> Sort (cost=50.00..55.00 rows=1000) Sort Key: p.cliente_id -> Seq Scan on pedidos pEs eficiente cuando ambas tablas son grandes y ya estan (o pueden ser) ordenadas.
| Comando | Descripcion |
|---|---|
| Nested Loop | Una tabla muy pequena o hay indice en la tabla interna |
| Hash Join | Tablas medianas/grandes sin indice, una cabe en memoria |
| Merge Join | Tablas grandes ya ordenadas o cuando el resultado debe estar ordenado |
Indices compuestos y orden de columnas
Un indice compuesto tiene multiples columnas. El orden importa muchisimo:
CREATE INDEX idx_prod_cat_precio ON productos(categoria, precio);Este indice es util para:
-- Filtra por categoria (primera columna): SI usa el indiceSELECT * FROM productos WHERE categoria = 'Electronica';
-- Filtra por categoria Y precio: SI usa el indice (ambas columnas)SELECT * FROM productos WHERE categoria = 'Electronica' AND precio < 500;
-- Filtra SOLO por precio (segunda columna): NO usa el indice eficientementeSELECT * FROM productos WHERE precio < 500;Regla del prefijo izquierdo
Un indice compuesto (A, B, C) sirve para consultas que filtran por:
- A
- A y B
- A, B y C
Pero no para consultas que filtran solo por B, solo por C, o por B y C sin A. Piensa en una guia telefonica ordenada por (apellido, nombre): puedes buscar por apellido, o por apellido + nombre, pero no puedes buscar eficientemente solo por nombre.
Veamos el impacto con EXPLAIN:
-- Con indice en (categoria, precio)EXPLAIN ANALYZE SELECT * FROM productosWHERE categoria = 'Electronica' AND precio < 500;Index Scan using idx_prod_cat_precio on productos (cost=0.28..15.00 rows=45 actual time=0.020..0.150) Index Cond: (categoria = 'Electronica' AND precio < 500)-- Consulta que NO aprovecha el indice compuestoEXPLAIN ANALYZE SELECT * FROM productos WHERE precio < 500;Seq Scan on productos (cost=0.00..25.00 rows=800 actual time=0.010..0.400) Filter: (precio < 500)La primera consulta usa el indice y escanea solo 45 filas. La segunda hace Seq Scan y lee toda la tabla.
Covering indexes (indices cubrientes)
Un covering index incluye todas las columnas que tu consulta necesita. Esto permite un Index Only Scan, que es el escaneo mas rapido posible porque nunca necesita ir a la tabla:
-- Queremos ejecutar frecuentemente esta consulta:SELECT nombre, precio FROM productos WHERE categoria = 'Electronica';
-- Creamos un indice que "cubra" todas las columnas necesarias:CREATE INDEX idx_prod_covering ON productos(categoria) INCLUDE (nombre, precio);EXPLAIN ANALYZE SELECT nombre, precio FROM productos WHERE categoria = 'Electronica';Index Only Scan using idx_prod_covering on productos (cost=0.28..5.50 rows=50 actual time=0.015..0.080) Index Cond: (categoria = 'Electronica') Heap Fetches: 0Heap Fetches: 0 significa que NO tuvo que ir a la tabla para nada. Todo estaba en el indice.
Rendimiento
Un Index Only Scan con Heap Fetches: 0 es practicamente lo mas rapido que puedes lograr. Pero ten cuidado: los covering indexes ocupan mas espacio y hacen los INSERT/UPDATE mas lentos.
El costo de los indices
Los indices no son gratis. Cada indice:
- Ocupa espacio en disco: Un indice puede ocupar tanto como la tabla misma.
- Hace mas lento el INSERT: Cada fila nueva debe insertarse en la tabla Y en cada indice.
- Hace mas lento el UPDATE: Si actualizas una columna indexada, el indice tambien se actualiza.
- Hace mas lento el DELETE: Igual, hay que actualizar el indice.
-- Ver el tamano de tus indicesSELECT indexname, pg_size_pretty(pg_relation_size(indexname::regclass)) AS tamanoFROM pg_indexesWHERE tablename = 'productos';No indexes todo
No crees un indice en cada columna “por si acaso”. Analiza que consultas se ejecutan frecuentemente, usa EXPLAIN, y crea indices solo donde realmente se necesiten. Un indice que no se usa es puro desperdicio.
Tips de optimizacion de consultas
Aqui van las tecnicas mas efectivas para escribir consultas rapidas:
1. Selecciona solo las columnas que necesitas
-- Malo: trae TODAS las columnasSELECT * FROM productos WHERE categoria = 'Electronica';
-- Bueno: trae solo lo necesarioSELECT nombre, precio FROM productos WHERE categoria = 'Electronica';Menos columnas = menos datos transferidos = mas rapido. Ademas, permite usar Index Only Scan.
2. Filtra temprano con WHERE
-- Malo: primero une todo, luego filtraSELECT c.nombre, SUM(p.total)FROM clientes cJOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombreHAVING c.nombre LIKE 'A%';
-- Bueno: filtra antes de unirSELECT c.nombre, SUM(p.total)FROM clientes cJOIN pedidos p ON c.id = p.cliente_idWHERE c.nombre LIKE 'A%'GROUP BY c.nombre;3. Evita funciones en columnas indexadas
-- Malo: la funcion impide usar el indiceSELECT * FROM pedidos WHERE EXTRACT(YEAR FROM fecha) = 2024;
-- Bueno: rango que SI usa el indiceSELECT * FROM pedidosWHERE fecha >= '2024-01-01' AND fecha < '2025-01-01';4. Usa EXISTS en vez de IN para subconsultas grandes
-- Mas lento con tablas grandesSELECT * FROM clientesWHERE id IN (SELECT cliente_id FROM pedidos);
-- Mas rapido: EXISTS se detiene en la primera coincidenciaSELECT * FROM clientes cWHERE EXISTS (SELECT 1 FROM pedidos p WHERE p.cliente_id = c.id);Por que EXISTS es mas rapido
IN necesita materializar toda la subconsulta primero. EXISTS se detiene tan pronto encuentra la primera coincidencia para cada fila. Si un cliente tiene 100 pedidos, IN los encuentra todos, EXISTS encuentra el primero y sigue con el siguiente cliente.
5. Prefiere JOINs sobre subconsultas correlacionadas
-- Malo: subconsulta se ejecuta una vez POR CADA clienteSELECT c.nombre, (SELECT COUNT(*) FROM pedidos p WHERE p.cliente_id = c.id) AS total_pedidosFROM clientes c;
-- Bueno: un solo JOIN con agregacionSELECT c.nombre, COUNT(p.id) AS total_pedidosFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombre;6. Usa LIMIT cuando no necesitas todas las filas
-- Si solo quieres los 10 productos mas caros:SELECT nombre, precio FROM productos ORDER BY precio DESC LIMIT 10;Con un indice en precio, esto es practicamente instantaneo porque no necesita ordenar toda la tabla.
7. Operaciones masivas vs fila por fila
-- Malo: insertar uno por uno (en un loop de aplicacion)INSERT INTO productos (nombre, precio) VALUES ('Producto 1', 10);INSERT INTO productos (nombre, precio) VALUES ('Producto 2', 20);INSERT INTO productos (nombre, precio) VALUES ('Producto 3', 30);
-- Bueno: insertar todo de una vezINSERT INTO productos (nombre, precio) VALUES ('Producto 1', 10), ('Producto 2', 20), ('Producto 3', 30);El INSERT masivo es dramaticamente mas rapido porque reduce la sobrecarga de comunicacion con la base de datos.
Ejemplo completo: optimizando una consulta paso a paso
Supongamos que tenemos esta consulta lenta:
-- Consulta originalSELECT c.nombre, c.email, COUNT(*) AS total_pedidos, SUM(p.total) AS gasto_totalFROM clientes c, pedidos pWHERE c.id = p.cliente_id AND UPPER(c.ciudad) = 'MADRID' AND EXTRACT(YEAR FROM p.fecha) = 2024GROUP BY c.nombre, c.emailORDER BY gasto_total DESC;Veamos el EXPLAIN:
EXPLAIN ANALYZE SELECT c.nombre, c.email, COUNT(*), SUM(p.total)FROM clientes c, pedidos pWHERE c.id = p.cliente_id AND UPPER(c.ciudad) = 'MADRID' AND EXTRACT(YEAR FROM p.fecha) = 2024GROUP BY c.nombre, c.emailORDER BY SUM(p.total) DESC;Sort (cost=150.00..151.00 rows=50) Sort Key: (sum(p.total)) DESC -> HashAggregate (cost=140.00..145.00 rows=50) -> Hash Join (cost=15.00..130.00 rows=200) Hash Cond: (p.cliente_id = c.id) -> Seq Scan on pedidos p (cost=0.00..100.00 rows=2000) Filter: (EXTRACT(YEAR FROM fecha) = 2024) -> Hash (cost=12.00..12.00 rows=50) -> Seq Scan on clientes c (cost=0.00..12.00 rows=50) Filter: (upper(ciudad) = 'MADRID')Planning Time: 0.200 msExecution Time: 5.500 msProblemas identificados:
- Seq Scan en pedidos con filtro por funcion (
EXTRACT) - Seq Scan en clientes con filtro por funcion (
UPPER) - JOIN implicito (estilo viejo con coma)
Optimizacion paso a paso:
-- Paso 1: Usar JOIN explicito y evitar funciones en WHERESELECT c.nombre, c.email, COUNT(*) AS total_pedidos, SUM(p.total) AS gasto_totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_idWHERE c.ciudad = 'Madrid' AND p.fecha >= '2024-01-01' AND p.fecha < '2025-01-01'GROUP BY c.nombre, c.emailORDER BY gasto_total DESC;-- Paso 2: Crear indices utilesCREATE INDEX idx_clientes_ciudad ON clientes(ciudad);CREATE INDEX idx_pedidos_fecha_cliente ON pedidos(fecha, cliente_id);Ahora el EXPLAIN muestra:
Sort (cost=25.00..25.50 rows=50) Sort Key: (sum(p.total)) DESC -> HashAggregate (cost=20.00..22.00 rows=50) -> Nested Loop (cost=1.00..18.00 rows=80) -> Index Scan using idx_clientes_ciudad on clientes c (cost=0.28..5.00 rows=15) Index Cond: (ciudad = 'Madrid') -> Index Scan using idx_pedidos_fecha_cliente on pedidos p (cost=0.29..0.80 rows=5) Index Cond: (fecha >= '2024-01-01' AND fecha < '2025-01-01' AND cliente_id = c.id)Planning Time: 0.300 msExecution Time: 0.450 msDe 5.5 ms a 0.45 ms. Mas de 12 veces mas rapido. Y en tablas con millones de filas, la diferencia seria de minutos a milisegundos.
Tabla resumen de complejidad
| Comando | Descripcion |
|---|---|
| Busqueda por clave primaria (con indice) | **O(log n)** - Muy rapido |
| Index Scan | **O(log n + k)** - k = filas devueltas |
| Sequential Scan | **O(n)** - Lee toda la tabla |
| Ordenar sin indice (Sort) | **O(n log n)** |
| Hash Join | **O(n + m)** - Ambas tablas |
| Merge Join | **O(n log n + m log m)** - Por la ordenacion |
| Nested Loop (sin indice) | **O(n * m)** - Producto cartesiano |
| Nested Loop (con indice) | **O(n * log m)** - Mucho mejor |
Interpretacion practica
Con 1 millon de filas:
- O(log n) ~ 20 operaciones
- O(n) ~ 1,000,000 operaciones
- O(n log n) ~ 20,000,000 operaciones
- O(n * m) con m = 1,000,000 ~ 1,000,000,000,000 operaciones
La diferencia entre O(log n) y O(n) es literalmente la diferencia entre milisegundos y minutos.
VACUUM y ANALYZE: mantenimiento de la base
PostgreSQL necesita mantenimiento periodico:
- VACUUM: Recupera espacio de filas eliminadas o actualizadas. PostgreSQL no borra filas fisicamente al hacer DELETE; las marca como “muertas”. VACUUM limpia esas filas muertas.
- ANALYZE: Actualiza las estadisticas que usa el planificador para estimar costos. Si las estadisticas estan desactualizadas, el planificador puede elegir planes malos.
-- Ejecutar manualmente (normalmente lo hace autovacuum automaticamente)VACUUM ANALYZE productos;Nota
PostgreSQL tiene un proceso llamado autovacuum que ejecuta VACUUM y ANALYZE automaticamente. En la mayoria de los casos no necesitas hacerlo manualmente, pero es bueno saber que existe por si diagnosticas problemas de rendimiento.
Ejercicios
Ejercicio 1: Mira este EXPLAIN y responde: que tipo de escaneo se esta usando? Es eficiente para una tabla con 10 millones de filas?
Seq Scan on pedidos (cost=0.00..250000.00 rows=5000000 width=44) Filter: (estado = 'completado') Rows Removed by Filter: 5000000Ver solucion
Se esta usando un Sequential Scan. Para una tabla con 10 millones de filas, esto es ineficiente si solo necesitamos los pedidos completados (5 millones de 10 millones = 50%). Aunque 50% es bastante, un indice podria ayudar si las consultas son frecuentes. La solucion seria:
CREATE INDEX idx_pedidos_estado ON pedidos(estado);Sin embargo, si el 50% de los pedidos son “completado”, PostgreSQL podria seguir eligiendo Seq Scan porque tiene que leer la mitad de la tabla de todos modos. Un indice brilla mas cuando el filtro es mas selectivo (por ejemplo, estado = ‘cancelado’ si solo hay un 2%).
Ejercicio 2: Esta consulta es lenta. Identifica los problemas y reescribela de forma optimizada:
SELECT *FROM clientesWHERE LOWER(email) LIKE '%gmail.com'ORDER BY fecha_registro;Ver solucion
Problemas:
SELECT *trae columnas innecesarias.LOWER(email)impide usar un indice en email.LIKE '%gmail.com'con comodin al inicio no puede usar indice.ORDER BY fecha_registrosin indice requiere ordenar toda la tabla.
Solucion:
-- Crear indice para el ordenamientoCREATE INDEX idx_clientes_fecha ON clientes(fecha_registro);
-- Seleccionar solo lo necesario-- El LIKE con % al inicio es dificil de optimizar con indices normales.-- Opciones: usar pg_trgm extension o reestructurar la consultaSELECT nombre, email, fecha_registroFROM clientesWHERE email LIKE '%@gmail.com'ORDER BY fecha_registro;Para optimizar el LIKE con % al inicio, se puede usar la extension pg_trgm:
CREATE EXTENSION IF NOT EXISTS pg_trgm;CREATE INDEX idx_clientes_email_trgm ON clientes USING gin (email gin_trgm_ops);Ejercicio 3: Crea los indices necesarios para optimizar esta consulta:
SELECT c.nombre, COUNT(p.id) AS total_pedidos, AVG(p.total) AS promedioFROM clientes cJOIN pedidos p ON c.id = p.cliente_idWHERE c.ciudad = 'Barcelona' AND p.fecha >= '2024-01-01'GROUP BY c.nombreORDER BY promedio DESCLIMIT 10;Ver solucion
-- Indice para filtrar clientes por ciudadCREATE INDEX idx_clientes_ciudad ON clientes(ciudad);
-- Indice compuesto para pedidos: filtra por fecha y une por cliente_idCREATE INDEX idx_pedidos_fecha_cliente ON pedidos(fecha, cliente_id);
-- Alternativamente, si cliente_id es mas selectivo:CREATE INDEX idx_pedidos_cliente_fecha ON pedidos(cliente_id, fecha);El orden del indice compuesto depende de cual columna es mas selectiva. Si hay pocos clientes de Barcelona (digamos 20), entonces idx_pedidos_cliente_fecha es mejor porque para cada cliente el Nested Loop buscara directamente por cliente_id y luego filtrara por fecha.
Ejercicio 4: Explica por que esta consulta no usa el indice en fecha_creacion de la tabla productos:
CREATE INDEX idx_prod_fecha ON productos(fecha_creacion);
SELECT * FROM productos WHERE fecha_creacion + INTERVAL '30 days' > NOW();Ver solucion
La operacion fecha_creacion + INTERVAL '30 days' aplica una funcion/operacion a la columna indexada. PostgreSQL no puede usar el indice porque la expresion transforma el valor antes de comparar.
La solucion es mover la operacion al otro lado:
SELECT * FROM productos WHERE fecha_creacion > NOW() - INTERVAL '30 days';Ahora fecha_creacion esta “limpia” en el WHERE y PostgreSQL puede usar el indice para buscar directamente los valores mayores a la fecha calculada.
Ejercicio 5: Analiza el siguiente plan de ejecucion y sugiere como mejorarlo:
Hash Join (cost=400.00..2500.00 rows=50000 actual time=50.000..800.000) Hash Cond: (dp.producto_id = pr.id) -> Seq Scan on detalle_pedidos dp (cost=0.00..1500.00 rows=100000 actual time=0.020..200.000) -> Hash (cost=200.00..200.00 rows=10000 actual time=45.000..45.000) -> Seq Scan on productos pr (cost=0.00..200.00 rows=10000 actual time=0.010..30.000)Planning Time: 0.500 msExecution Time: 850.000 msVer solucion
El plan muestra un Hash Join entre detalle_pedidos (100,000 filas) y productos (10,000 filas). Ambas tablas usan Seq Scan, y el tiempo total es de 850 ms.
Mejoras:
- Crear un indice en
detalle_pedidos.producto_idpara evitar el Seq Scan:
CREATE INDEX idx_detalle_producto ON detalle_pedidos(producto_id);-
Si la consulta original filtra por algun criterio adicional (como una fecha o categoria), agregar ese filtro y un indice compuesto.
-
Si no necesitas todas las columnas de ambas tablas, selecciona solo las necesarias para reducir el volumen de datos.
Con el indice, PostgreSQL podria cambiar a un Nested Loop con Index Scan en detalle_pedidos, o al menos usar un Bitmap Scan, lo que reduciria significativamente el tiempo.
Ejercicio 6: Tienes una tabla pedidos con 5 millones de filas. Esta consulta tarda 15 segundos:
SELECT estado, COUNT(*), AVG(total)FROM pedidosWHERE fecha BETWEEN '2024-01-01' AND '2024-12-31'GROUP BY estadoORDER BY COUNT(*) DESC;Que harias para optimizarla? Piensa en indices, y si un Index Only Scan seria posible.
Ver solucion
-- Indice compuesto que cubre las columnas del WHERE, GROUP BY y SELECTCREATE INDEX idx_pedidos_fecha_estado_total ON pedidos(fecha, estado, total);Este indice permite:
- Filtrar por
fechaeficientemente (primera columna del indice). - Agrupar por
estadosin ordenacion adicional. - Calcular
AVG(total)directamente desde el indice (Index Only Scan).
EXPLAIN ANALYZE SELECT estado, COUNT(*), AVG(total)FROM pedidosWHERE fecha BETWEEN '2024-01-01' AND '2024-12-31'GROUP BY estadoORDER BY COUNT(*) DESC;Resultado esperado: Index Only Scan seguido de un GroupAggregate, reduciendo el tiempo de 15 segundos a menos de 1 segundo.
Alternativamente, con la clausula INCLUDE:
CREATE INDEX idx_pedidos_optimizado ON pedidos(fecha, estado) INCLUDE (total);Analitica con SQL
Ya sabes agrupar datos con GROUP BY y calcular promedios con AVG. Pero el analisis de datos real va mas alla: necesitas rankings, comparaciones con periodos anteriores, acumulados progresivos y medidas estadisticas como la mediana o la desviacion estandar. En este modulo vas a aprender las herramientas de SQL que convierten una base de datos en una plataforma de analisis.
Prerequisito
Este modulo asume que dominas GROUP BY y HAVING (Modulo 6), subconsultas y CTEs (Modulo 8), y funciones basicas (Modulo 9). Si alguno de esos temas te suena nuevo, revisalos antes de continuar.
Funciones de ventana (Window Functions)
Que son y por que las necesitas
Con GROUP BY obtienes un resumen que colapsa las filas. Pero a veces necesitas el resumen y los datos individuales al mismo tiempo. Por ejemplo: ver cada empleado con su salario y el salario promedio de su departamento, en la misma fila.
Comparemos ambos enfoques:
-- GROUP BY: colapsa filas (una fila por departamento)SELECT departamento, ROUND(AVG(salario), 2) AS promedioFROM empleadosGROUP BY departamento; departamento │ promedio──────────────┼────────── Gerencia │ 85000.00 Tecnologia │ 58333.33 Ventas │ 42000.00 Soporte │ 37000.00Pierdes el detalle individual. Ahora con una funcion de ventana:
-- Window function: mantiene CADA fila y agrega el promedioSELECT nombre, departamento, salario, ROUND(AVG(salario) OVER (PARTITION BY departamento), 2) AS promedio_deptoFROM empleadosORDER BY departamento, salario DESC; nombre │ departamento │ salario │ promedio_depto─────────────────────┼──────────────┼─────────┼─────────────── Sofia Mendez │ Gerencia │ 85000 │ 85000.00 Ricardo Soto │ Soporte │ 38000 │ 37000.00 Patricia Herrera │ Soporte │ 36000 │ 37000.00 Miguel Angel Torres │ Tecnologia │ 62000 │ 58333.33 Alejandro Vega │ Tecnologia │ 58000 │ 58333.33 Camila Rojas │ Tecnologia │ 55000 │ 58333.33 ...Cada empleado conserva su fila individual, pero ahora tiene una columna extra con el promedio de su departamento. Eso es una funcion de ventana.
Paso a paso: como piensa PostgreSQL una funcion de ventana
Para entender bien las funciones de ventana, veamos que hace PostgreSQL internamente cuando ejecutas esta consulta:
SELECT nombre, departamento, salario, SUM(salario) OVER (PARTITION BY departamento) AS total_deptoFROM empleados;Paso 1: Ejecutar el FROM y WHERE (obtener todas las filas)
PostgreSQL lee todas las filas de empleados como lo haria normalmente.
Paso 2: Dividir en ventanas (PARTITION BY)
Agrupa las filas segun PARTITION BY departamento, pero no las colapsa (esa es la diferencia con GROUP BY):
Ventana "Gerencia": [Sofia – 85000] Ventana "Soporte": [Ricardo – 38000, Patricia – 36000] Ventana "Tecnologia": [Miguel – 62000, Alejandro – 58000, Camila – 55000] Ventana "Ventas": [Juan – 45000, Valentina – 42000, Fernanda – 40000, Daniela – 41000]Paso 3: Calcular la funcion dentro de cada ventana
Calcula SUM(salario) para cada ventana por separado:
- Gerencia: 85000
- Soporte: 74000
- Tecnologia: 175000
- Ventas: 168000
Paso 4: Pegar el resultado en cada fila
Cada empleado recibe el valor calculado para su ventana:
nombre │ departamento │ salario │ total_depto──────────────────┼──────────────┼─────────┼──────────── Sofia Mendez │ Gerencia │ 85000 │ 85000 ← total de Gerencia Ricardo Soto │ Soporte │ 38000 │ 74000 ← total de Soporte Patricia Herrera │ Soporte │ 36000 │ 74000 ← mismo: total de Soporte Miguel A. Torres │ Tecnologia │ 62000 │ 175000 ← total de Tecnologia ...La clave: la fila no desaparece. Cada empleado conserva su fila individual, y el resultado de la funcion de ventana se “pega” como una columna extra.
GROUP BY colapsa, OVER pega
La diferencia fundamental es esta:
GROUP BY departamento→ 4 filas (una por departamento, pierdes los nombres)SUM(...) OVER (PARTITION BY departamento)→ 10 filas (una por empleado, cada una con el total de su departamento)
Piensalo asi: GROUP BY es un resumen que destruye el detalle. OVER es una etiqueta que agrega informacion a cada fila sin destruir nada.
La clausula OVER: anatomia de una funcion de ventana
La clave es OVER(). Cualquier funcion de agregacion (SUM, AVG, COUNT, etc.) se convierte en funcion de ventana al agregarle OVER():
funcion() OVER ( PARTITION BY columna -- divide en grupos (opcional) ORDER BY columna -- ordena dentro del grupo (opcional))PARTITION BY define las “ventanas” (grupos de filas sobre los que se calcula). Visualmente:
Tabla empleados con PARTITION BY departamento:
┌──────────────────────┬──────────────┬─────────┐ │ nombre │ departamento │ salario │ ├──────────────────────┼──────────────┼─────────┤ │ Juan Perez │ Ventas │ 45000 │ ─┐ │ Valentina Castro │ Ventas │ 42000 │ ├─ Ventana 1 (Ventas) │ Fernanda Luna │ Ventas │ 40000 │ │ AVG = 42000 │ Daniela Flores │ Ventas │ 41000 │ ─┘ │ Miguel Angel Torres │ Tecnologia │ 62000 │ ─┐ │ Camila Rojas │ Tecnologia │ 55000 │ ├─ Ventana 2 (Tecnologia) │ Alejandro Vega │ Tecnologia │ 58000 │ ─┘ AVG = 58333 │ Ricardo Soto │ Soporte │ 38000 │ ─┐ Ventana 3 (Soporte) │ Patricia Herrera │ Soporte │ 36000 │ ─┘ AVG = 37000 │ Sofia Mendez │ Gerencia │ 85000 │ ── Ventana 4 (Gerencia) └──────────────────────┴──────────────┴─────────┘ AVG = 85000
La funcion se calcula DENTRO de cada ventana, por separado.OVER() vacio = toda la tabla
Si usas OVER() sin nada adentro (parentesis vacios), la ventana es la tabla completa. AVG(salario) OVER() calcula el promedio de TODOS los empleados. Esto es util para calcular porcentajes del total.
Porcentaje del total con OVER()
Un patron muy comun en analisis: calcular que porcentaje representa cada fila del total.
SELECT nombre, departamento, salario, SUM(salario) OVER() AS total_empresa, ROUND(salario::NUMERIC / SUM(salario) OVER() * 100, 2) AS porcentajeFROM empleadosORDER BY porcentaje DESC;SUM(salario) OVER() suma todos los salarios (sin PARTITION BY = toda la tabla), y se repite en cada fila. Asi puedes dividir cada salario individual entre el total para obtener el porcentaje.
Rankings: ROW_NUMBER, RANK y DENSE_RANK
Las funciones de ranking asignan un numero de posicion a cada fila segun un orden.
| Comando | Descripcion |
|---|---|
| ROW_NUMBER() OVER(...) | Numero secuencial unico (1, 2, 3, 4...). Nunca hay empates. |
| RANK() OVER(...) | Ranking con saltos en empates (1, 2, 2, 4...). Salta posiciones. |
| DENSE_RANK() OVER(...) | Ranking sin saltos en empates (1, 2, 2, 3...). No salta posiciones. |
| NTILE(n) OVER(...) | Divide las filas en n grupos iguales. Util para cuartiles (n=4), deciles (n=10). |
Veamos la diferencia con un ejemplo:
SELECT nombre, departamento, salario, ROW_NUMBER() OVER (ORDER BY salario DESC) AS row_num, RANK() OVER (ORDER BY salario DESC) AS rank, DENSE_RANK() OVER (ORDER BY salario DESC) AS dense_rankFROM empleados; nombre │ salario │ row_num │ rank │ dense_rank─────────────────────┼─────────┼─────────┼──────┼─────────── Sofia Mendez │ 85000 │ 1 │ 1 │ 1 Miguel Angel Torres │ 62000 │ 2 │ 2 │ 2 Alejandro Vega │ 58000 │ 3 │ 3 │ 3 Camila Rojas │ 55000 │ 4 │ 4 │ 4 Juan Perez │ 45000 │ 5 │ 5 │ 5 Valentina Castro │ 42000 │ 6 │ 6 │ 6 Daniela Flores │ 41000 │ 7 │ 7 │ 7 Fernanda Luna │ 40000 │ 8 │ 8 │ 8 Ricardo Soto │ 38000 │ 9 │ 9 │ 9 Patricia Herrera │ 36000 │ 10 │ 10 │ 10Sin empates las tres dan el mismo resultado. La diferencia se nota cuando hay valores iguales: RANK salta posiciones (1, 2, 2, 4) y DENSE_RANK no (1, 2, 2, 3).
ORDER BY es obligatorio en rankings
ROW_NUMBER, RANK y DENSE_RANK requieren ORDER BY dentro del OVER(). Sin ORDER BY, no tiene sentido asignar un ranking. PARTITION BY es opcional: si lo omites, el ranking es sobre toda la tabla.
El patron Top-N: lo vas a usar todo el tiempo
Uno de los patrones mas utiles en analisis de datos: obtener los N mejores de cada grupo.
-- Producto mas vendido por categoriaWITH ventas_producto AS ( SELECT pr.nombre, pr.categoria, SUM(dp.cantidad) AS total_vendido, ROW_NUMBER() OVER ( PARTITION BY pr.categoria ORDER BY SUM(dp.cantidad) DESC ) AS ranking FROM productos pr INNER JOIN detalle_pedidos dp ON pr.id = dp.producto_id GROUP BY pr.nombre, pr.categoria)SELECT nombre, categoria, total_vendidoFROM ventas_productoWHERE ranking = 1;El truco: ROW_NUMBER dentro del CTE asigna el ranking por grupo, y luego filtras con WHERE ranking <= N en la consulta exterior.
CTE + ROW_NUMBER + WHERE ranking <= N
Este patron responde preguntas como “los 3 mejores por grupo”, “el primero de cada categoria”, “el top 5 por ciudad”. Lo vas a usar constantemente en analisis de datos.
NTILE: dividir en grupos iguales
NTILE(n) divide las filas en n grupos de tamano (aproximadamente) igual. Muy util para crear cuartiles, quintiles o deciles.
-- Dividir empleados en cuartiles salarialesSELECT nombre, salario, NTILE(4) OVER (ORDER BY salario) AS cuartilFROM empleados; nombre │ salario │ cuartil─────────────────────┼─────────┼──────── Patricia Herrera │ 36000 │ 1 ← 25% mas bajo Ricardo Soto │ 38000 │ 1 Fernanda Luna │ 40000 │ 1 Daniela Flores │ 41000 │ 2 Valentina Castro │ 42000 │ 2 Juan Perez │ 45000 │ 2 Camila Rojas │ 55000 │ 3 Alejandro Vega │ 58000 │ 3 Miguel Angel Torres │ 62000 │ 4 Sofia Mendez │ 85000 │ 4 ← 25% mas altoLAG y LEAD: comparar con filas vecinas
A veces necesitas comparar cada fila con la anterior o la siguiente. ¿Cuanto crecieron las ventas respecto al mes pasado? ¿El pedido actual es mayor que el anterior? Para eso existen LAG y LEAD.
| Comando | Descripcion |
|---|---|
| LAG(col, n, default) | Valor de n filas ANTES (default: 1 fila). Devuelve NULL si no existe fila anterior, a menos que especifiques un valor por defecto. |
| LEAD(col, n, default) | Valor de n filas DESPUES (default: 1 fila). Devuelve NULL si no existe fila siguiente. |
Ejemplo clasico: variacion mensual de ventas.
WITH ventas_mes AS ( SELECT DATE_TRUNC('month', fecha) AS mes, SUM(total) AS total_mes FROM pedidos GROUP BY DATE_TRUNC('month', fecha))SELECT TO_CHAR(mes, 'YYYY-MM') AS mes, total_mes, LAG(total_mes) OVER (ORDER BY mes) AS mes_anterior, ROUND( (total_mes - LAG(total_mes) OVER (ORDER BY mes)) / LAG(total_mes) OVER (ORDER BY mes) * 100, 2 ) AS variacion_pctFROM ventas_mesORDER BY mes; mes │ total_mes │ mes_anterior │ variacion_pct──────────┼───────────┼──────────────┼────────────── 2024-01 │ 1479.97 │ NULL │ NULL ← sin mes anterior 2024-02 │ 2309.95 │ 1479.97 │ 56.08 2024-03 │ 1324.93 │ 2309.95 │ -42.65 ← caida 2024-04 │ 1949.94 │ 1324.93 │ 47.17La primera fila tiene NULL porque no hay mes anterior. Puedes usar el tercer parametro de LAG para poner un valor por defecto: LAG(total_mes, 1, 0).
LAG y LEAD requieren ORDER BY
Para hablar de “la fila anterior” necesitas definir un orden. LAG y LEAD siempre necesitan ORDER BY dentro del OVER(). PARTITION BY es opcional: si lo agregas, la comparacion es dentro de cada grupo.
FIRST_VALUE, LAST_VALUE y NTH_VALUE
Estas funciones acceden a un valor especifico dentro de la ventana: el primero, el ultimo o el N-esimo.
| Comando | Descripcion |
|---|---|
| FIRST_VALUE(col) OVER(...) | Devuelve el valor de la primera fila de la ventana. |
| LAST_VALUE(col) OVER(...) | Devuelve el valor de la ultima fila de la ventana. |
| NTH_VALUE(col, n) OVER(...) | Devuelve el valor de la fila N de la ventana. |
-- Para cada empleado: mostrar quien gana mas y quien gana menos en su departamentoSELECT nombre, departamento, salario, FIRST_VALUE(nombre) OVER ( PARTITION BY departamento ORDER BY salario DESC ) AS mejor_pagado, FIRST_VALUE(nombre) OVER ( PARTITION BY departamento ORDER BY salario ASC ) AS peor_pagadoFROM empleadosORDER BY departamento, salario DESC;Cuidado con LAST_VALUE
Por defecto, la ventana va desde el inicio hasta la fila actual (ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW). Esto significa que LAST_VALUE devuelve la fila actual, no la ultima del grupo. Para obtener la verdadera ultima fila, necesitas especificar la ventana completa:
LAST_VALUE(nombre) OVER ( PARTITION BY departamento ORDER BY salario ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)Por eso, en la practica, es mas simple usar FIRST_VALUE con el orden invertido.
Agregaciones acumulativas y promedios moviles
Cuando usas una funcion de agregacion (SUM, AVG, COUNT) con OVER(ORDER BY ...), obtienes un calculo acumulativo: cada fila incluye los datos de todas las filas anteriores.
Suma acumulada (running total)
SELECT fecha, total, SUM(total) OVER (ORDER BY fecha) AS acumulado, COUNT(*) OVER (ORDER BY fecha) AS pedidos_hasta_fechaFROM pedidosORDER BY fecha; fecha │ total │ acumulado │ pedidos_hasta_fecha────────────┼─────────┼───────────┼──────────────────── 2024-01-15 │ 1389.98 │ 1389.98 │ 1 2024-01-20 │ 89.99 │ 1479.97 │ 2 2024-02-01 │ 499.98 │ 1979.95 │ 3 2024-02-14 │ 59.99 │ 2039.94 │ 4 2024-02-28 │ 1749.98 │ 3789.92 │ 5 ...Cada fila suma su valor al total de todas las filas anteriores. Es como una suma progresiva que va creciendo fila a fila.
Como funciona el acumulado
Cuando escribes SUM(total) OVER (ORDER BY fecha), PostgreSQL suma desde la primera fila hasta la fila actual (inclusive). Internamente, la ventana por defecto es ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, que significa “desde el inicio hasta aqui”.
Promedio movil (moving average)
El promedio movil suaviza fluctuaciones y muestra tendencias. Para calcularlo, defines una “ventana deslizante” de N filas usando ROWS BETWEEN:
SELECT fecha, total, ROUND( AVG(total) OVER ( ORDER BY fecha ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ), 2 ) AS promedio_movil_3FROM pedidosORDER BY fecha;ROWS BETWEEN 2 PRECEDING AND CURRENT ROW significa “desde 2 filas antes hasta la fila actual” — una ventana de 3 filas que se va deslizando.
ROWS BETWEEN
Esta clausula define el tamano de la ventana deslizante. Los valores mas comunes: ROWS BETWEEN 2 PRECEDING AND CURRENT ROW (3 filas), ROWS BETWEEN 6 PRECEDING AND CURRENT ROW (7 filas). Para promedios moviles de ventas semanales o mensuales.
Acumulado por grupo
Puedes combinar PARTITION BY con ORDER BY para calcular acumulados dentro de cada grupo:
-- Gasto acumulado de cada cliente a lo largo del tiempoSELECT c.nombre, p.fecha, p.total, SUM(p.total) OVER ( PARTITION BY c.id ORDER BY p.fecha ) AS gasto_acumuladoFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idORDER BY c.nombre, p.fecha;Esto muestra como va creciendo el gasto de cada cliente pedido a pedido. PARTITION BY c.id reinicia el acumulado para cada cliente.
Marcos de ventana: ROWS vs RANGE
Cuando usas ORDER BY en una funcion de ventana, PostgreSQL define un marco que determina que filas se incluyen en el calculo. Hay dos tipos principales:
| Comando | Descripcion |
|---|---|
| ROWS BETWEEN | Cuenta filas fisicas. '2 PRECEDING' = exactamente 2 filas antes. Es el mas predecible. |
| RANGE BETWEEN | Usa el valor de ORDER BY. Incluye filas con el mismo valor (empates). Es el default con ORDER BY. |
| UNBOUNDED PRECEDING | Desde la primera fila de la ventana. |
| CURRENT ROW | Hasta la fila actual. |
| UNBOUNDED FOLLOWING | Hasta la ultima fila de la ventana. |
| n PRECEDING / n FOLLOWING | n filas antes/despues de la actual. |
La diferencia importa cuando hay valores duplicados en el ORDER BY:
-- ROWS: exactamente 2 filas anteriores + actual = 3 filas siempreSUM(total) OVER (ORDER BY fecha ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
-- RANGE: incluye TODAS las filas con el mismo valor de fecha-- Si hay 3 pedidos el mismo dia, los incluye todosSUM(total) OVER (ORDER BY fecha RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)¿Cual usar?
En la practica, ROWS es mas predecible y mas usado para promedios moviles y ventanas deslizantes. RANGE es util cuando quieres que los empates se traten como iguales (por ejemplo, todos los pedidos del mismo dia sumen igual).
CUME_DIST y PERCENT_RANK: distribucion
Estas funciones te dicen donde esta cada fila en la distribucion del grupo:
SELECT nombre, salario, ROUND(PERCENT_RANK() OVER (ORDER BY salario)::NUMERIC, 4) AS percent_rank, ROUND(CUME_DIST() OVER (ORDER BY salario)::NUMERIC, 4) AS cume_distFROM empleadosORDER BY salario; nombre │ salario │ percent_rank │ cume_dist─────────────────────┼─────────┼──────────────┼────────── Patricia Herrera │ 36000 │ 0.0000 │ 0.1000 ← 10% gana esto o menos Ricardo Soto │ 38000 │ 0.1111 │ 0.2000 Fernanda Luna │ 40000 │ 0.2222 │ 0.3000 ... Sofia Mendez │ 85000 │ 1.0000 │ 1.0000 ← 100% gana esto o menos- PERCENT_RANK: posicion relativa (0 = primero, 1 = ultimo). Formula:
(rank - 1) / (total - 1). - CUME_DIST: porcentaje acumulado. Formula:
filas con valor <= actual / total filas.
Estas funciones son utiles para detectar outliers: si un valor tiene PERCENT_RANK > 0.95, esta en el top 5%.
GROUPING SETS, ROLLUP y CUBE
A veces necesitas calcular subtotales y totales generales en una sola consulta. En lugar de hacer multiples GROUP BY y unirlos con UNION ALL, puedes usar GROUPING SETS.
GROUPING SETS: multiples agrupaciones en una consulta
-- Ventas por categoria, por estado, y total generalSELECT COALESCE(pr.categoria, 'TODAS') AS categoria, COALESCE(pe.estado, 'TODOS') AS estado, SUM(dp.cantidad) AS unidades, ROUND(SUM(dp.cantidad * dp.precio_unitario), 2) AS ingresosFROM detalle_pedidos dpJOIN productos pr ON dp.producto_id = pr.idJOIN pedidos pe ON dp.pedido_id = pe.idGROUP BY GROUPING SETS ( (pr.categoria, pe.estado), -- por categoria y estado (pr.categoria), -- subtotal por categoria (pe.estado), -- subtotal por estado () -- total general)ORDER BY categoria, estado;Cada tupla en GROUPING SETS genera un nivel de agrupacion. La tupla vacia () genera el total general. Las filas de subtotales tienen NULL en las columnas que no participan en esa agrupacion (por eso usamos COALESCE).
ROLLUP: jerarquia de subtotales
ROLLUP es un atajo para crear subtotales jerarquicos. ROLLUP(a, b) genera los grupos (a, b), (a) y ():
-- Ventas con subtotales por categoria y total generalSELECT COALESCE(pr.categoria, '** TOTAL **') AS categoria, COUNT(DISTINCT pe.id) AS pedidos, SUM(dp.cantidad) AS unidades, ROUND(SUM(dp.cantidad * dp.precio_unitario), 2) AS ingresosFROM detalle_pedidos dpJOIN productos pr ON dp.producto_id = pr.idJOIN pedidos pe ON dp.pedido_id = pe.idGROUP BY ROLLUP(pr.categoria)ORDER BY ingresos DESC; categoria │ pedidos │ unidades │ ingresos──────────────┼─────────┼──────────┼────────── ** TOTAL ** │ 13 │ 29 │ 8454.77 ← total general Electronica │ 8 │ 12 │ 5809.83 Muebles │ 4 │ 5 │ 1534.94 Accesorios │ 5 │ 12 │ 1110.00CUBE: todas las combinaciones
CUBE(a, b) genera TODAS las combinaciones posibles: (a, b), (a), (b) y (). Es como un GROUPING SETS con cada subconjunto:
-- Ventas cruzadas por categoria y estado (con todos los subtotales)SELECT COALESCE(pr.categoria, '** TOTAL **') AS categoria, COALESCE(pe.estado, '** TOTAL **') AS estado, SUM(dp.cantidad) AS unidadesFROM detalle_pedidos dpJOIN productos pr ON dp.producto_id = pr.idJOIN pedidos pe ON dp.pedido_id = pe.idGROUP BY CUBE(pr.categoria, pe.estado)ORDER BY categoria, estado;¿Cual usar?
- GROUPING SETS: cuando necesitas combinaciones especificas.
- ROLLUP: para reportes jerarquicos con subtotales (ventas por pais → ciudad → tienda).
- CUBE: para tablas cruzadas con todos los subtotales posibles. Mas filas, pero informacion completa.
Tablas pivote: filas a columnas
Un patron comun en reportes: convertir valores de filas en columnas. SQL no tiene un PIVOT nativo, pero puedes lograrlo con CASE + agregacion:
-- Ventas por mes como columnas (tabla pivote)SELECT c.nombre, SUM(CASE WHEN EXTRACT(MONTH FROM p.fecha) = 1 THEN p.total ELSE 0 END) AS enero, SUM(CASE WHEN EXTRACT(MONTH FROM p.fecha) = 2 THEN p.total ELSE 0 END) AS febrero, SUM(CASE WHEN EXTRACT(MONTH FROM p.fecha) = 3 THEN p.total ELSE 0 END) AS marzo, SUM(CASE WHEN EXTRACT(MONTH FROM p.fecha) = 4 THEN p.total ELSE 0 END) AS abril, SUM(p.total) AS totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_idWHERE p.fecha >= '2024-01-01' AND p.fecha < '2025-01-01'GROUP BY c.nombreORDER BY total DESC; nombre │ enero │ febrero │ marzo │ abril │ total─────────────────┼─────────┼─────────┼─────────┼─────────┼───────── Maria Garcia │ 1389.98 │ 59.99 │ 0.00 │ 449.99 │ 1899.96 Ana Martinez │ 0.00 │ 499.98 │ 839.98 │ 0.00 │ 1339.96 Isabel Moreno │ 0.00 │ 0.00 │ 0.00 │ 1299.99 │ 1299.99 ...Pivote de estados de pedidos
-- Cantidad de pedidos por estado, uno por columnaSELECT c.nombre, COUNT(*) FILTER (WHERE p.estado = 'completado') AS completados, COUNT(*) FILTER (WHERE p.estado = 'enviado') AS enviados, COUNT(*) FILTER (WHERE p.estado = 'pendiente') AS pendientes, COUNT(*) AS totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombreORDER BY total DESC;FILTER vs CASE para pivotes
FILTER es mas legible que CASE para pivotes en PostgreSQL. Pero si necesitas portabilidad a otros motores SQL, usa la version con CASE.
Patrones avanzados de analisis
Comparacion Year-over-Year (YoY)
Compara datos del mismo periodo en anos diferentes:
-- Comparar ventas mensuales entre periodosWITH ventas_por_mes AS ( SELECT EXTRACT(YEAR FROM fecha) AS anio, EXTRACT(MONTH FROM fecha) AS mes, SUM(total) AS total_ventas, COUNT(*) AS num_pedidos FROM pedidos GROUP BY EXTRACT(YEAR FROM fecha), EXTRACT(MONTH FROM fecha))SELECT anio, mes, total_ventas, num_pedidos, LAG(total_ventas) OVER (PARTITION BY mes ORDER BY anio) AS mismo_mes_anio_anterior, ROUND( (total_ventas - LAG(total_ventas) OVER (PARTITION BY mes ORDER BY anio)) / NULLIF(LAG(total_ventas) OVER (PARTITION BY mes ORDER BY anio), 0) * 100, 2 ) AS variacion_yoyFROM ventas_por_mesORDER BY anio, mes;El truco: PARTITION BY mes ORDER BY anio hace que LAG compare el mismo mes en anos consecutivos.
Analisis de retencion
¿Cuantos clientes que compraron en enero volvieron a comprar en los meses siguientes?
WITH primer_compra AS ( SELECT cliente_id, DATE_TRUNC('month', MIN(fecha)) AS mes_primera_compra FROM pedidos GROUP BY cliente_id),actividad AS ( SELECT DISTINCT p.cliente_id, pc.mes_primera_compra, DATE_TRUNC('month', p.fecha) AS mes_actividad, (EXTRACT(YEAR FROM DATE_TRUNC('month', p.fecha)) - EXTRACT(YEAR FROM pc.mes_primera_compra)) * 12 + (EXTRACT(MONTH FROM DATE_TRUNC('month', p.fecha)) - EXTRACT(MONTH FROM pc.mes_primera_compra)) AS meses_desde_primera FROM pedidos p JOIN primer_compra pc ON p.cliente_id = pc.cliente_id)SELECT TO_CHAR(mes_primera_compra, 'YYYY-MM') AS cohorte, meses_desde_primera, COUNT(DISTINCT cliente_id) AS clientes_activosFROM actividadGROUP BY mes_primera_compra, meses_desde_primeraORDER BY mes_primera_compra, meses_desde_primera;Este patron muestra cuantos clientes de cada cohorte (mes de primera compra) siguen activos en los meses siguientes. Es la base del analisis de retencion que usan empresas SaaS y e-commerce.
Acumulado con meta (target tracking)
Compara el progreso acumulado contra una meta:
WITH ventas_diarias AS ( SELECT fecha, SUM(total) AS ventas_dia FROM pedidos WHERE EXTRACT(MONTH FROM fecha) = 1 AND EXTRACT(YEAR FROM fecha) = 2024 GROUP BY fecha),meta AS ( SELECT 2000.00 AS meta_mensual -- meta de ventas del mes)SELECT vd.fecha, vd.ventas_dia, SUM(vd.ventas_dia) OVER (ORDER BY vd.fecha) AS acumulado, m.meta_mensual, ROUND(SUM(vd.ventas_dia) OVER (ORDER BY vd.fecha) / m.meta_mensual * 100, 1) AS pct_metaFROM ventas_diarias vdCROSS JOIN meta mORDER BY vd.fecha;Funciones estadisticas
Para analisis de datos necesitas ir mas alla del promedio. SQL tiene funciones estadisticas que te permiten medir dispersion, encontrar percentiles y detectar patrones.
| Comando | Descripcion |
|---|---|
| STDDEV(col) | Desviacion estandar muestral. Mide que tan dispersos estan los datos respecto al promedio. |
| VARIANCE(col) | Varianza muestral. Es el cuadrado de la desviacion estandar. |
| PERCENTILE_CONT(p) WITHIN GROUP (ORDER BY col) | Percentil continuo (interpola entre valores). p va de 0 a 1. 0.5 = mediana. |
| PERCENTILE_DISC(p) WITHIN GROUP (ORDER BY col) | Percentil discreto: devuelve un valor real de los datos (el mas cercano al percentil). |
| MODE() WITHIN GROUP (ORDER BY col) | El valor que mas se repite (moda). |
Que significan estas medidas
El promedio (AVG) te dice el centro de los datos. La desviacion estandar (STDDEV) te dice que tan dispersos estan. Si el promedio de salarios es $50,000 y la desviacion es $5,000, la mayoria gana entre $45,000 y $55,000. Si la desviacion es $20,000, los salarios son muy variados. La mediana es el valor del medio cuando ordenas los datos: la mitad esta arriba y la mitad abajo.
Resumen estadistico de salarios
SELECT departamento, COUNT(*) AS empleados, ROUND(AVG(salario), 2) AS promedio, ROUND(STDDEV(salario), 2) AS desviacion_std, MIN(salario) AS minimo, MAX(salario) AS maximo, MAX(salario) - MIN(salario) AS rangoFROM empleadosGROUP BY departamentoHAVING COUNT(*) > 1ORDER BY promedio DESC;Mediana y percentiles
-- Mediana y cuartiles del precio de productosSELECT ROUND(PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY precio)::NUMERIC, 2) AS percentil_25, ROUND(PERCENTILE_CONT(0.50) WITHIN GROUP (ORDER BY precio)::NUMERIC, 2) AS mediana, ROUND(PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY precio)::NUMERIC, 2) AS percentil_75, ROUND(AVG(precio), 2) AS promedioFROM productos;Mediana vs promedio
La mediana (PERCENTILE_CONT(0.5)) es muchas veces mejor que el promedio para describir datos, porque no se ve afectada por valores extremos. Si tienes un producto de $1,300 y el resto cuesta entre $12 y $90, el promedio sube a ~$160 pero la mediana se mantiene representativa en ~$45.
Tambien puedes calcular percentiles por grupo:
-- Mediana del precio por categoriaSELECT categoria, COUNT(*) AS productos, ROUND(AVG(precio), 2) AS promedio, ROUND( PERCENTILE_CONT(0.50) WITHIN GROUP (ORDER BY precio)::NUMERIC, 2 ) AS medianaFROM productosGROUP BY categoriaORDER BY mediana DESC;Moda
-- Categoria mas comun entre los productosSELECT MODE() WITHIN GROUP (ORDER BY categoria) AS categoria_mas_comunFROM productos;
-- Ciudad mas comun entre los clientesSELECT MODE() WITHIN GROUP (ORDER BY ciudad) AS ciudad_mas_comunFROM clientes;STDDEV como funcion de ventana
Las funciones estadisticas tambien funcionan como funciones de ventana. Esto es util para detectar valores atipicos:
-- Detectar pedidos con total inusual para cada clienteSELECT c.nombre, p.id AS pedido_id, p.total, ROUND(AVG(p.total) OVER (PARTITION BY c.id), 2) AS promedio_cliente, ROUND(STDDEV(p.total) OVER (PARTITION BY c.id), 2) AS stddev_clienteFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idORDER BY c.nombre, p.total DESC;Si un pedido esta a mas de 2 desviaciones estandar del promedio del cliente, probablemente es un valor atipico.
FILTER: agregacion condicional
Ya conoces el truco de usar CASE WHEN dentro de una funcion de agregacion para contar o sumar condicionalmente. PostgreSQL tiene una forma mas elegante: la clausula FILTER.
-- Forma clasica con CASE WHENSELECT c.nombre, COUNT(*) AS total_pedidos, COUNT(CASE WHEN p.estado = 'completado' THEN 1 END) AS completados, COUNT(CASE WHEN p.estado = 'pendiente' THEN 1 END) AS pendientesFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombre;
-- Forma con FILTER (mas legible)SELECT c.nombre, COUNT(*) AS total_pedidos, COUNT(*) FILTER (WHERE p.estado = 'completado') AS completados, COUNT(*) FILTER (WHERE p.estado = 'pendiente') AS pendientes, ROUND(AVG(p.total) FILTER (WHERE p.estado = 'completado'), 2) AS promedio_completadosFROM clientes cINNER JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombreORDER BY total_pedidos DESC;FILTER funciona con cualquier funcion de agregacion: COUNT, SUM, AVG, MIN, MAX, etc.
FILTER es de PostgreSQL
La clausula FILTER es una extension de PostgreSQL, no es SQL estandar. Si alguna vez necesitas migrar a MySQL o SQL Server, tendras que volver al CASE WHEN. Pero en PostgreSQL, FILTER es mas legible y ligeramente mas eficiente.
Patrones practicos para analisis de datos
Porcentaje del total por grupo
¿Que porcentaje de ventas representa cada producto dentro de su categoria?
SELECT pr.categoria, pr.nombre, SUM(dp.cantidad) AS vendidos, ROUND( SUM(dp.cantidad)::NUMERIC / SUM(SUM(dp.cantidad)) OVER (PARTITION BY pr.categoria) * 100, 1 ) AS pct_de_categoriaFROM productos prINNER JOIN detalle_pedidos dp ON pr.id = dp.producto_idGROUP BY pr.categoria, pr.nombreORDER BY pr.categoria, vendidos DESC;El truco: SUM(SUM(dp.cantidad)) OVER (PARTITION BY pr.categoria) es una funcion de ventana sobre una agregacion. Primero SUM(dp.cantidad) calcula el total por producto (GROUP BY), y luego SUM(...) OVER (PARTITION BY categoria) suma esos totales dentro de cada categoria.
Diferencia con el promedio del grupo
¿Cuanto gana cada empleado por encima o debajo del promedio de su departamento?
SELECT nombre, departamento, salario, ROUND(AVG(salario) OVER (PARTITION BY departamento), 2) AS promedio_depto, salario - ROUND(AVG(salario) OVER (PARTITION BY departamento), 2) AS diferenciaFROM empleadosORDER BY departamento, diferencia DESC;Reutilizar ventanas con WINDOW
Si repites la misma clausula OVER varias veces, puedes definirla una sola vez con WINDOW:
SELECT nombre, departamento, salario, AVG(salario) OVER w AS promedio, MIN(salario) OVER w AS minimo, MAX(salario) OVER w AS maximo, salario - AVG(salario) OVER w AS diferenciaFROM empleadosWINDOW w AS (PARTITION BY departamento)ORDER BY departamento, salario DESC;WINDOW hace tu consulta mas legible
Ademas de evitar repeticion, WINDOW reduce errores: si necesitas cambiar la particion, la cambias en un solo lugar. PostgreSQL tambien puede optimizar mejor la consulta cuando detecta que varias funciones usan la misma ventana.
Rendimiento de funciones de ventana
Sorting interno
Cada clausula OVER(ORDER BY ...) distinta puede requerir una operacion de ordenamiento interna con costo O(n log n). Si tu consulta tiene 5 funciones de ventana con ORDER BY diferentes, PostgreSQL podria hacer 5 ordenamientos separados. Tips para optimizar:
- Reutiliza la misma ventana con
WINDOWcuando sea posible: PostgreSQL ordena una sola vez. - Un indice en las columnas del
PARTITION BYyORDER BYpuede evitar el sorting. - Con tablas grandes (millones de filas), revisa el plan de ejecucion con
EXPLAIN ANALYZE.
Ejercicios
Ejercicio 1: Muestra cada producto con su nombre, precio, categoria y el precio promedio de su categoria (usando una funcion de ventana). Agrega una columna que diga ‘Por encima’ o ‘Por debajo’ segun si el producto supera o no el promedio.
Ver solucion
SELECT nombre, categoria, precio, ROUND(AVG(precio) OVER (PARTITION BY categoria), 2) AS promedio_categoria, CASE WHEN precio >= AVG(precio) OVER (PARTITION BY categoria) THEN 'Por encima' ELSE 'Por debajo' END AS comparacionFROM productosORDER BY categoria, precio DESC;Ejercicio 2: Rankea a los empleados por salario dentro de cada departamento usando DENSE_RANK. Muestra nombre, departamento, salario y el ranking.
Ver solucion
SELECT nombre, departamento, salario, DENSE_RANK() OVER ( PARTITION BY departamento ORDER BY salario DESC ) AS rankingFROM empleadosORDER BY departamento, ranking;Ejercicio 3: Calcula las ventas totales por mes para 2024. Para cada mes, muestra el total, el total del mes anterior (con LAG) y la diferencia absoluta entre ambos.
Ver solucion
WITH ventas_mes AS ( SELECT DATE_TRUNC('month', fecha) AS mes, SUM(total) AS total_mes FROM pedidos WHERE fecha >= '2024-01-01' AND fecha < '2025-01-01' GROUP BY DATE_TRUNC('month', fecha))SELECT TO_CHAR(mes, 'YYYY-MM') AS mes, ROUND(total_mes, 2) AS total_mes, ROUND(LAG(total_mes) OVER (ORDER BY mes), 2) AS mes_anterior, ROUND(ABS(total_mes - LAG(total_mes) OVER (ORDER BY mes)), 2) AS diferenciaFROM ventas_mesORDER BY mes;Ejercicio 4: Muestra los pedidos ordenados por fecha con una columna que acumule la suma total de todos los pedidos hasta esa fecha (running total).
Ver solucion
SELECT id, fecha, total, SUM(total) OVER (ORDER BY fecha, id) AS acumuladoFROM pedidosORDER BY fecha, id;Agregamos id al ORDER BY para desempatar pedidos del mismo dia y obtener un acumulado determinista.
Ejercicio 5: Calcula la mediana, el percentil 25 y el percentil 75 de los salarios de los empleados. Luego, en una segunda consulta, calcula los mismos valores pero separados por departamento.
Ver solucion
-- GlobalSELECT ROUND(PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY salario)::NUMERIC, 2) AS p25, ROUND(PERCENTILE_CONT(0.50) WITHIN GROUP (ORDER BY salario)::NUMERIC, 2) AS mediana, ROUND(PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY salario)::NUMERIC, 2) AS p75FROM empleados;
-- Por departamentoSELECT departamento, COUNT(*) AS empleados, ROUND(PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY salario)::NUMERIC, 2) AS p25, ROUND(PERCENTILE_CONT(0.50) WITHIN GROUP (ORDER BY salario)::NUMERIC, 2) AS mediana, ROUND(PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY salario)::NUMERIC, 2) AS p75FROM empleadosGROUP BY departamentoORDER BY mediana DESC;Ejercicio 6: Para cada categoria de productos, muestra: la cantidad total de unidades vendidas, la cantidad vendida en pedidos completados y la cantidad en pedidos pendientes. Usa la clausula FILTER.
Ver solucion
SELECT pr.categoria, SUM(dp.cantidad) AS total_vendidas, SUM(dp.cantidad) FILTER (WHERE pe.estado = 'completado') AS en_completados, SUM(dp.cantidad) FILTER (WHERE pe.estado = 'pendiente') AS en_pendientes, SUM(dp.cantidad) FILTER (WHERE pe.estado = 'enviado') AS en_enviadosFROM productos prINNER JOIN detalle_pedidos dp ON pr.id = dp.producto_idINNER JOIN pedidos pe ON dp.pedido_id = pe.idGROUP BY pr.categoriaORDER BY total_vendidas DESC;Ejercicio 7 (Desafio): Para cada cliente que haya hecho al menos un pedido, muestra su nombre, gasto total, ranking general por gasto (con RANK) y que porcentaje del gasto total de la empresa representa.
Ver solucion
WITH gasto_cliente AS ( SELECT c.nombre, SUM(p.total) AS gasto_total FROM clientes c INNER JOIN pedidos p ON c.id = p.cliente_id GROUP BY c.id, c.nombre)SELECT nombre, gasto_total, RANK() OVER (ORDER BY gasto_total DESC) AS ranking, ROUND( gasto_total / SUM(gasto_total) OVER() * 100, 2 ) AS porcentaje_empresaFROM gasto_clienteORDER BY ranking;Ejercicio 8 (Desafio): Identifica los meses donde las ventas cayeron respecto al mes anterior (variacion negativa). Muestra el mes, las ventas del mes, las del mes anterior y la variacion porcentual. Ordena por la peor caida primero.
Ver solucion
WITH ventas_mes AS ( SELECT DATE_TRUNC('month', fecha) AS mes, SUM(total) AS total_mes FROM pedidos GROUP BY DATE_TRUNC('month', fecha)),con_variacion AS ( SELECT TO_CHAR(mes, 'YYYY-MM') AS mes, ROUND(total_mes, 2) AS total_mes, ROUND(LAG(total_mes) OVER (ORDER BY mes), 2) AS mes_anterior, ROUND( (total_mes - LAG(total_mes) OVER (ORDER BY mes)) / LAG(total_mes) OVER (ORDER BY mes) * 100, 2 ) AS variacion_pct FROM ventas_mes)SELECT *FROM con_variacionWHERE variacion_pct < 0ORDER BY variacion_pct ASC;Ejercicio 9: Crea un reporte con ROLLUP que muestre las unidades vendidas por categoria, con un subtotal por categoria y un total general.
Ver solucion
SELECT COALESCE(pr.categoria, '** TOTAL **') AS categoria, SUM(dp.cantidad) AS unidades_vendidas, ROUND(SUM(dp.cantidad * dp.precio_unitario), 2) AS ingresosFROM detalle_pedidos dpJOIN productos pr ON dp.producto_id = pr.idGROUP BY ROLLUP(pr.categoria)ORDER BY ingresos DESC;Ejercicio 10: Crea una tabla pivote que muestre para cada categoria de producto, cuantas unidades se vendieron en cada estado de pedido (completado, enviado, pendiente) como columnas separadas.
Ver solucion
SELECT pr.categoria, SUM(dp.cantidad) FILTER (WHERE pe.estado = 'completado') AS completados, SUM(dp.cantidad) FILTER (WHERE pe.estado = 'enviado') AS enviados, SUM(dp.cantidad) FILTER (WHERE pe.estado = 'pendiente') AS pendientes, SUM(dp.cantidad) AS totalFROM detalle_pedidos dpJOIN productos pr ON dp.producto_id = pr.idJOIN pedidos pe ON dp.pedido_id = pe.idGROUP BY pr.categoriaORDER BY total DESC;Ejercicio 11 (Desafio): Para cada empleado, muestra su nombre, salario, y en que percentil se encuentra dentro de su departamento (usa PERCENT_RANK). Ademas, muestra quien es el mejor pagado de su departamento (usa FIRST_VALUE).
Ver solucion
SELECT nombre, departamento, salario, ROUND(PERCENT_RANK() OVER ( PARTITION BY departamento ORDER BY salario )::NUMERIC, 2) AS percentil, FIRST_VALUE(nombre) OVER ( PARTITION BY departamento ORDER BY salario DESC ) AS mejor_pagado_deptoFROM empleadosORDER BY departamento, salario DESC;Metadatos: Explorando la estructura
Cuando te conectas a una base de datos nueva — ya sea en un proyecto de ciencia de datos, en un trabajo nuevo, o en una base de datos legacy — lo primero que necesitas saber es: que tablas hay, que columnas tienen y que tipo de datos guardan. PostgreSQL almacena toda esa informacion en tablas especiales que puedes consultar con SQL normal.
Base de datos de practica
Todos los ejemplos de este modulo se ejecutan sobre la base de datos tienda que creamos en el Modulo 2. Si aun no la tienes configurada, ve al Modulo 2 primero.
Atajos rapidos: psql y DBeaver
Antes de escribir consultas, vale la pena conocer los atajos que ya tienes disponibles.
En psql (terminal)
\dt -- listar todas las tablas\d productos -- ver estructura de una tabla (columnas, tipos, constraints)\d+ productos -- igual pero con mas detalle (tamano, comentarios)\dn -- listar esquemas\df -- listar funcionesEn DBeaver (interfaz grafica)
En el panel de navegacion (izquierda), expande tu conexion → base de datos tienda → esquema public → Tables. Ahi ves todas las tablas. Haciendo click en una tabla puedes ver sus columnas, tipos, constraints, foreign keys, indices y mas.
¿Por que aprender las consultas SQL entonces?
Los atajos de psql y DBeaver son rapidos para explorar, pero las consultas SQL te dan mucho mas control: puedes filtrar, combinar resultados, buscar en toda la base de datos y automatizar. Ademas, funcionan desde cualquier cliente SQL.
information_schema: el estandar SQL
information_schema es un esquema especial definido por el estandar SQL. Existe en PostgreSQL, MySQL, SQL Server y otras bases de datos. Si aprendes a usarlo, tus consultas de metadatos seran portables.
Listar todas las tablas
SELECT table_name, table_typeFROM information_schema.tablesWHERE table_schema = 'public'ORDER BY table_name;Resultado:
table_name | table_type-----------------+------------ clientes | BASE TABLE detalle_pedidos | BASE TABLE empleados | BASE TABLE pedidos | BASE TABLE productos | BASE TABLEFiltramos por table_schema = 'public' porque ahi viven las tablas que creamos nosotros. Sin ese filtro verias tambien las tablas internas de PostgreSQL.
Ver columnas de una tabla
SELECT column_name, data_type, is_nullable, column_defaultFROM information_schema.columnsWHERE table_name = 'productos'ORDER BY ordinal_position;Resultado:
column_name | data_type | is_nullable | column_default----------------+-------------------+-------------+--------------------------- id | integer | NO | nextval('productos_id_seq') nombre | character varying | NO | NULL precio | numeric | NO | NULL categoria | character varying | YES | NULL stock | integer | YES | 0 fecha_creacion | date | YES | CURRENT_DATEordinal_position es el orden en que fueron definidas las columnas. is_nullable te dice si la columna acepta NULL.
Tipos de datos mas comunes en PostgreSQL
Cuando explores columnas vas a encontrar estos tipos de datos frecuentemente. Aqui tienes una referencia rapida:
| Comando | Descripcion |
|---|---|
| INTEGER / INT | Numeros enteros (-2 mil millones a 2 mil millones). Ej: stock, cantidad |
| SERIAL | Entero auto-incremental. Se usa para IDs (PRIMARY KEY) |
| NUMERIC(p,s) / DECIMAL | Numeros exactos con decimales. Ej: precio DECIMAL(10,2) = hasta 10 digitos, 2 decimales |
| VARCHAR(n) | Texto de longitud variable con limite. Ej: nombre VARCHAR(100) |
| TEXT | Texto de longitud ilimitada. Ej: descripciones largas, comentarios |
| BOOLEAN | Verdadero (TRUE) o falso (FALSE). Ej: activo, verificado |
| DATE | Fecha sin hora (YYYY-MM-DD). Ej: fecha_registro, fecha_nacimiento |
| TIMESTAMP | Fecha + hora (YYYY-MM-DD HH:MI:SS). Ej: created_at, updated_at |
| TIMESTAMPTZ | Timestamp con zona horaria. Recomendado cuando trabajas con usuarios en distintos paises |
| JSONB | Datos JSON binario, permite consultas dentro del JSON. Muy usado en apps modernas |
| UUID | Identificador unico universal (128 bits). Alternativa a SERIAL para IDs |
Documentacion oficial
PostgreSQL soporta muchos mas tipos de datos (arrays, rangos, geometricos, red, etc.). Consulta la documentacion oficial de tipos de datos para la referencia completa.
Vistas mas utiles de information_schema
| Comando | Descripcion |
|---|---|
| information_schema.tables | Tablas y vistas de la base de datos (nombre, tipo, esquema) |
| information_schema.columns | Columnas de cada tabla (nombre, tipo, nullable, default, posicion) |
| information_schema.table_constraints | Restricciones: PRIMARY KEY, FOREIGN KEY, UNIQUE, CHECK |
| information_schema.key_column_usage | Que columnas participan en cada constraint (PK, FK, UNIQUE) |
| information_schema.referential_constraints | Detalle de foreign keys: a que tabla y constraint referencian |
Encontrar columnas por tipo de dato
Supongamos que quieres saber que columnas de tipo texto (character varying) hay en toda la base de datos:
SELECT table_name, column_name, character_maximum_lengthFROM information_schema.columnsWHERE table_schema = 'public' AND data_type = 'character varying'ORDER BY table_name, ordinal_position;Resultado:
table_name | column_name | character_maximum_length------------+-------------+------------------------- clientes | nombre | 100 clientes | email | 100 clientes | ciudad | 50 empleados | nombre | 100 empleados | departamento| 50 pedidos | estado | 20 productos | nombre | 100 productos | categoria | 50Ver restricciones de una tabla
SELECT tc.constraint_name, tc.constraint_type, kcu.column_nameFROM information_schema.table_constraints tcJOIN information_schema.key_column_usage kcu ON tc.constraint_name = kcu.constraint_nameWHERE tc.table_name = 'pedidos';Resultado:
constraint_name | constraint_type | column_name--------------------------+-----------------+------------ pedidos_pkey | PRIMARY KEY | id pedidos_cliente_id_fkey | FOREIGN KEY | cliente_idEsto te dice que la tabla pedidos tiene una PRIMARY KEY en id y una FOREIGN KEY en cliente_id.
pg_catalog: las tablas internas de PostgreSQL
pg_catalog es el catalogo interno de PostgreSQL. Es mas detallado que information_schema pero es especifico de PostgreSQL — no funciona en MySQL ni SQL Server.
Portabilidad
Si necesitas que tus consultas funcionen en distintas bases de datos, usa information_schema. Usa pg_catalog cuando necesites informacion extra que solo PostgreSQL proporciona (tamanos, OIDs, estadisticas internas).
Tablas principales de pg_catalog
| Comando | Descripcion |
|---|---|
| pg_class | Tablas, indices, secuencias y vistas (nombre, tipo, tamano, OID) |
| pg_attribute | Columnas de cada tabla (nombre, tipo OID, posicion, nullable) |
| pg_namespace | Esquemas de la base de datos (public, pg_catalog, etc.) |
| pg_description | Comentarios agregados con COMMENT ON a tablas y columnas |
| pg_constraint | Constraints: PK, FK, UNIQUE, CHECK con detalle interno |
| pg_type | Todos los tipos de datos disponibles en PostgreSQL |
Listar tablas con pg_catalog
SELECT relname AS tabla, reltuples::INTEGER AS filas_estimadasFROM pg_classWHERE relkind = 'r' -- 'r' = tabla regular AND relnamespace = 'public'::regnamespaceORDER BY relname;Resultado:
tabla | filas_estimadas-----------------+---------------- clientes | 10 detalle_pedidos | 24 empleados | 10 pedidos | 15 productos | 15Filas estimadas vs reales
reltuples es una estimacion que PostgreSQL mantiene internamente para el planificador de consultas. Puede no ser exacta si la tabla cambio despues del ultimo ANALYZE. Para el conteo exacto necesitas SELECT COUNT(*).
Consultas practicas utiles
Estas son consultas que vas a usar frecuentemente en tu trabajo diario.
Tamano de tablas
SELECT relname AS tabla, pg_size_pretty(pg_total_relation_size(oid)) AS tamano_total, pg_size_pretty(pg_relation_size(oid)) AS tamano_datos, pg_size_pretty(pg_indexes_size(oid)) AS tamano_indicesFROM pg_classWHERE relkind = 'r' AND relnamespace = 'public'::regnamespaceORDER BY pg_total_relation_size(oid) DESC;Resultado:
tabla | tamano_total | tamano_datos | tamano_indices-----------------+--------------+--------------+---------------- detalle_pedidos | 32 kB | 8192 bytes | 16 kB productos | 32 kB | 8192 bytes | 16 kB pedidos | 32 kB | 8192 bytes | 16 kB empleados | 32 kB | 8192 bytes | 16 kB clientes | 32 kB | 8192 bytes | 16 kB¿Por que importa el tamano?
Con datos pequenos como los nuestros, todas las tablas son diminutas. Pero en produccion, esta consulta te ayuda a identificar tablas que crecieron demasiado, que necesitan particionamiento o que tienen indices ocupando mas espacio que los datos.
Ver las foreign keys y sus relaciones
Esta consulta te muestra como se conectan las tablas entre si:
SELECT tc.table_name AS tabla_origen, kcu.column_name AS columna_fk, ccu.table_name AS tabla_destino, ccu.column_name AS columna_destinoFROM information_schema.table_constraints tcJOIN information_schema.key_column_usage kcu ON tc.constraint_name = kcu.constraint_nameJOIN information_schema.constraint_column_usage ccu ON tc.constraint_name = ccu.constraint_nameWHERE tc.constraint_type = 'FOREIGN KEY' AND tc.table_schema = 'public'ORDER BY tc.table_name;Resultado:
tabla_origen | columna_fk | tabla_destino | columna_destino------------------+-------------+---------------+----------------- detalle_pedidos | pedido_id | pedidos | id detalle_pedidos | producto_id | productos | id empleados | jefe_id | empleados | id pedidos | cliente_id | clientes | idEste resultado es basicamente el diagrama de relaciones de tu base de datos, pero generado automaticamente.
Buscar una columna por nombre
Cuando llegas a una base de datos con muchas tablas y necesitas encontrar donde esta cierta informacion:
SELECT table_name, column_name, data_typeFROM information_schema.columnsWHERE table_schema = 'public' AND column_name LIKE '%fecha%'ORDER BY table_name;Resultado:
table_name | column_name | data_type------------+-------------------+----------- clientes | fecha_registro | date empleados | fecha_contratacion| date pedidos | fecha | date productos | fecha_creacion | dateBusqueda flexible
Cambia '%fecha%' por cualquier patron: '%id%' para encontrar claves, '%email%' para campos de correo, '%precio%' para valores monetarios. Usa ILIKE en vez de LIKE si quieres busqueda sin importar mayusculas/minusculas.
Contar columnas de cada tabla
SELECT table_name, (SELECT COUNT(*) FROM information_schema.columns c WHERE c.table_name = t.table_name AND c.table_schema = 'public') AS num_columnasFROM information_schema.tables tWHERE table_schema = 'public' AND table_type = 'BASE TABLE'ORDER BY table_name;Resultado:
table_name | num_columnas-----------------+-------------- clientes | 5 detalle_pedidos | 5 empleados | 6 pedidos | 5 productos | 6Esto te da una vision rapida de la complejidad de cada tabla.
COMMENT ON: documentar tu base de datos
PostgreSQL permite agregar comentarios a tablas, columnas, funciones y otros objetos. Estos comentarios quedan almacenados en la base de datos y son visibles para cualquier persona que se conecte.
Agregar comentarios
COMMENT ON TABLE productos IS 'Catalogo de productos de la tienda';COMMENT ON TABLE clientes IS 'Clientes registrados en el sistema';COMMENT ON TABLE pedidos IS 'Pedidos realizados por los clientes';
COMMENT ON COLUMN productos.precio IS 'Precio unitario en pesos, sin IVA';COMMENT ON COLUMN productos.stock IS 'Unidades disponibles en bodega';COMMENT ON COLUMN pedidos.estado IS 'Valores posibles: pendiente, enviado, completado';Consultar comentarios de tablas
SELECT c.relname AS tabla, obj_description(c.oid) AS comentarioFROM pg_class cWHERE c.relkind = 'r' AND c.relnamespace = 'public'::regnamespaceORDER BY c.relname;Resultado (despues de agregar los comentarios):
tabla | comentario-----------------+-------------------------------------- clientes | Clientes registrados en el sistema detalle_pedidos | NULL empleados | NULL pedidos | Pedidos realizados por los clientes productos | Catalogo de productos de la tiendaConsultar comentarios de columnas
SELECT a.attname AS columna, col_description(a.attrelid, a.attnum) AS comentarioFROM pg_attribute aJOIN pg_class c ON a.attrelid = c.oidWHERE c.relname = 'productos' AND a.attnum > 0 AND NOT a.attisdroppedORDER BY a.attnum;Resultado:
columna | comentario----------------+------------------------------------ id | NULL nombre | NULL precio | Precio unitario en pesos, sin IVA categoria | NULL stock | Unidades disponibles en bodega fecha_creacion | NULLBuena practica
Documentar tu base de datos con COMMENT ON es un habito excelente. Ayuda a que otros miembros del equipo (y tu yo del futuro) entiendan la estructura sin tener que adivinar que significa cada columna.
Patron completo: radiografia de una tabla
Esta consulta combina toda la informacion que hemos visto en una sola vista. Es tu “navaja suiza” para explorar cualquier tabla:
SELECT c.column_name AS columna, c.data_type AS tipo, CASE WHEN c.character_maximum_length IS NOT NULL THEN c.data_type || '(' || c.character_maximum_length || ')' ELSE c.data_type END AS tipo_completo, c.is_nullable AS acepta_null, c.column_default AS valor_default, CASE WHEN pk.column_name IS NOT NULL THEN 'PK' WHEN fk.column_name IS NOT NULL THEN 'FK -> ' || fk.ref_table ELSE '' END AS constraint_info, col_description( (SELECT oid FROM pg_class WHERE relname = c.table_name), c.ordinal_position ) AS comentarioFROM information_schema.columns cLEFT JOIN ( SELECT kcu.column_name FROM information_schema.table_constraints tc JOIN information_schema.key_column_usage kcu ON tc.constraint_name = kcu.constraint_name WHERE tc.table_name = 'pedidos' AND tc.constraint_type = 'PRIMARY KEY') pk ON c.column_name = pk.column_nameLEFT JOIN ( SELECT kcu.column_name, ccu.table_name AS ref_table FROM information_schema.table_constraints tc JOIN information_schema.key_column_usage kcu ON tc.constraint_name = kcu.constraint_name JOIN information_schema.constraint_column_usage ccu ON tc.constraint_name = ccu.constraint_name WHERE tc.table_name = 'pedidos' AND tc.constraint_type = 'FOREIGN KEY') fk ON c.column_name = fk.column_nameWHERE c.table_name = 'pedidos' AND c.table_schema = 'public'ORDER BY c.ordinal_position;Resultado:
columna | tipo | tipo_completo | acepta_null | valor_default | constraint_info | comentario------------+---------+---------------------+-------------+-----------------------+-------------------+------------------------------------------ id | integer | integer | NO | nextval(...) | PK | NULL cliente_id | integer | integer | YES | NULL | FK -> clientes | NULL fecha | date | date | YES | CURRENT_DATE | | NULL total | numeric | numeric | YES | NULL | | NULL estado | character varying | character varying(20)| YES | 'pendiente' | | Valores posibles: pendiente, enviado, completadoGuardala como favorita
Puedes guardar esta consulta en DBeaver (File → Save As o Ctrl+Shift+S) y cambiar solo el nombre de la tabla ('pedidos') cada vez que necesites explorar una tabla nueva. Es la forma mas rapida de entender una tabla desconocida.
¿Que sigue?
Ya sabes como explorar la estructura de cualquier base de datos PostgreSQL. En la seccion de Ejercicios integradores vas a poner en practica todo lo que aprendiste a lo largo del curso, combinando consultas de distintos modulos para resolver problemas mas complejos.
Ejercicios
Ejercicio 1: Usa information_schema.tables para listar todas las tablas de la base de datos tienda. Muestra el nombre y el tipo de tabla.
Ver solucion
SELECT table_name, table_typeFROM information_schema.tablesWHERE table_schema = 'public'ORDER BY table_name;Ejercicio 2: Consulta todas las columnas de la tabla detalle_pedidos mostrando: nombre de columna, tipo de dato, si acepta NULL y el valor por defecto. Ordena por la posicion original de las columnas.
Ver solucion
SELECT column_name, data_type, is_nullable, column_defaultFROM information_schema.columnsWHERE table_name = 'detalle_pedidos' AND table_schema = 'public'ORDER BY ordinal_position;Ejercicio 3: Encuentra todas las columnas que son FOREIGN KEY en la base de datos tienda. Muestra la tabla de origen, la columna FK, la tabla de destino y la columna de destino.
Ver solucion
SELECT tc.table_name AS tabla_origen, kcu.column_name AS columna_fk, ccu.table_name AS tabla_destino, ccu.column_name AS columna_destinoFROM information_schema.table_constraints tcJOIN information_schema.key_column_usage kcu ON tc.constraint_name = kcu.constraint_nameJOIN information_schema.constraint_column_usage ccu ON tc.constraint_name = ccu.constraint_nameWHERE tc.constraint_type = 'FOREIGN KEY' AND tc.table_schema = 'public'ORDER BY tc.table_name;Ejercicio 4: Calcula el tamano total de cada tabla en la base de datos, mostrando el resultado en formato legible (KB, MB). Ordena de mayor a menor tamano.
Ver solucion
SELECT relname AS tabla, pg_size_pretty(pg_total_relation_size(oid)) AS tamano_total, pg_size_pretty(pg_relation_size(oid)) AS tamano_datos, pg_size_pretty(pg_indexes_size(oid)) AS tamano_indicesFROM pg_classWHERE relkind = 'r' AND relnamespace = 'public'::regnamespaceORDER BY pg_total_relation_size(oid) DESC;Ejercicio 5: Agrega comentarios descriptivos a las 5 tablas de la base de datos y luego consultalos. Cada comentario debe describir brevemente que informacion almacena la tabla.
Ver solucion
-- Agregar comentariosCOMMENT ON TABLE productos IS 'Catalogo de productos de la tienda';COMMENT ON TABLE clientes IS 'Clientes registrados en el sistema';COMMENT ON TABLE pedidos IS 'Pedidos realizados por los clientes';COMMENT ON TABLE detalle_pedidos IS 'Lineas de detalle de cada pedido (productos y cantidades)';COMMENT ON TABLE empleados IS 'Empleados de la tienda con jerarquia de jefes';
-- Consultar comentariosSELECT c.relname AS tabla, obj_description(c.oid) AS comentarioFROM pg_class cWHERE c.relkind = 'r' AND c.relnamespace = 'public'::regnamespaceORDER BY c.relname;Ejercicio 6 (Desafio): Construye una consulta “radiografia” para la tabla empleados que muestre: nombre de columna, tipo de dato completo (incluyendo longitud para VARCHAR), si acepta NULL, valor por defecto, y si la columna es PK o FK (indicando la tabla referenciada).
Ver solucion
SELECT c.column_name AS columna, CASE WHEN c.character_maximum_length IS NOT NULL THEN c.data_type || '(' || c.character_maximum_length || ')' ELSE c.data_type END AS tipo_completo, c.is_nullable AS acepta_null, c.column_default AS valor_default, CASE WHEN pk.column_name IS NOT NULL THEN 'PK' WHEN fk.column_name IS NOT NULL THEN 'FK -> ' || fk.ref_table ELSE '' END AS constraint_infoFROM information_schema.columns cLEFT JOIN ( SELECT kcu.column_name FROM information_schema.table_constraints tc JOIN information_schema.key_column_usage kcu ON tc.constraint_name = kcu.constraint_name WHERE tc.table_name = 'empleados' AND tc.constraint_type = 'PRIMARY KEY') pk ON c.column_name = pk.column_nameLEFT JOIN ( SELECT kcu.column_name, ccu.table_name AS ref_table FROM information_schema.table_constraints tc JOIN information_schema.key_column_usage kcu ON tc.constraint_name = kcu.constraint_name JOIN information_schema.constraint_column_usage ccu ON tc.constraint_name = ccu.constraint_name WHERE tc.table_name = 'empleados' AND tc.constraint_type = 'FOREIGN KEY') fk ON c.column_name = fk.column_nameWHERE c.table_name = 'empleados' AND c.table_schema = 'public'ORDER BY c.ordinal_position;Normalizacion de bases de datos
Hasta ahora trabajamos con una base de datos ya disenada (tienda). Pero en la vida real, muchas veces tu tienes que disenar la estructura de las tablas. ¿Como decides que columnas van en que tabla? ¿Cuando crear una tabla nueva en lugar de agregar columnas? La respuesta es la normalizacion.
¿Por que esto importa para ciencia de datos?
Aunque como analista de datos rara vez disenas bases de datos desde cero, entender normalizacion te ayuda a: (1) comprender por que la BD tiene la estructura que tiene, (2) escribir mejores JOINs al saber como se relacionan las tablas, y (3) detectar problemas de calidad de datos causados por mala normalizacion.
¿Que es la normalizacion?
La normalizacion es un proceso de organizar las columnas y tablas de una base de datos para:
- Eliminar datos duplicados (redundancia)
- Evitar anomalias al insertar, actualizar o eliminar datos
- Asegurar consistencia en toda la base de datos
Imagina que tienes toda la informacion de pedidos en una sola tabla:
pedido_id │ fecha │ cliente_nombre │ cliente_email │ cliente_ciudad │ producto_nombre │ precio │ cantidad───────────┼────────────┼────────────────┼───────────────────┼────────────────┼─────────────────┼────────┼───────── 1 │ 2024-01-15 │ Maria Garcia │ maria@email.com │ Santiago │ Laptop Pro 15 │1299.99 │ 1 1 │ 2024-01-15 │ Maria Garcia │ maria@email.com │ Santiago │ Mouse Inalamb. │ 29.99 │ 3 2 │ 2024-01-20 │ Carlos Lopez │ carlos@email.com │ Valparaiso │ Teclado Mecanico│ 89.99 │ 1 3 │ 2024-02-01 │ Maria Garcia │ maria@email.com │ Santiago │ Silla Ergonomica│ 299.99 │ 1El nombre, email y ciudad de Maria aparecen 3 veces. Esto genera problemas.
Las anomalias: por que la redundancia es peligrosa
Anomalia de actualizacion
Si Maria cambia su email, necesitas actualizarlo en cada fila donde aparece. Si olvidas una, tienes datos inconsistentes:
pedido_id │ cliente_nombre │ cliente_email───────────┼────────────────┼─────────────────── 1 │ Maria Garcia │ maria_new@email.com ← actualizado 3 │ Maria Garcia │ maria@email.com ← olvidaste esta!¿Cual es el email correcto? No se sabe.
Anomalia de insercion
Si quieres agregar un nuevo cliente que aun no ha hecho pedidos, no puedes, porque necesitas un pedido_id para insertar la fila. El cliente no puede existir sin un pedido.
Anomalia de eliminacion
Si eliminas el unico pedido de Carlos Lopez, pierdes toda la informacion del cliente: su nombre, email y ciudad desaparecen.
La solucion
La normalizacion resuelve las tres anomalias separando la informacion en tablas independientes conectadas por claves. Exactamente lo que hace nuestra base de datos tienda: clientes, productos y pedidos estan en tablas separadas.
Claves: la base de la normalizacion
Antes de hablar de formas normales, necesitas entender dos conceptos fundamentales:
Clave primaria (Primary Key)
Una columna (o conjunto de columnas) que identifica de forma unica cada fila de la tabla:
-- El id identifica unicamente cada clienteCREATE TABLE clientes ( id SERIAL PRIMARY KEY, -- clave primaria nombre VARCHAR(100), email VARCHAR(100));Clave foranea (Foreign Key)
Una columna que hace referencia a la clave primaria de otra tabla. Crea la relacion entre tablas:
-- cliente_id referencia a clientes.idCREATE TABLE pedidos ( id SERIAL PRIMARY KEY, cliente_id INTEGER REFERENCES clientes(id), -- clave foranea fecha DATE, total DECIMAL(10,2));Dependencia funcional
Decimos que la columna B depende funcionalmente de la columna A si, dado un valor de A, siempre se obtiene el mismo valor de B. Se escribe A → B.
En nuestra tabla clientes:
id → nombre(dado un id, siempre obtienes el mismo nombre)id → email(dado un id, siempre obtienes el mismo email)id → ciudad(dado un id, siempre obtienes la misma ciudad)
Este concepto es la base de todas las formas normales.
Primera Forma Normal (1FN)
Una tabla esta en 1FN si:
- Cada columna tiene un solo valor (valores atomicos, no listas ni conjuntos)
- Cada fila es unica (tiene una clave primaria)
- No hay grupos repetidos de columnas
Ejemplo que viola 1FN
cliente_id │ nombre │ telefonos────────────┼──────────────┼────────────────────── 1 │ Maria Garcia │ 555-1234, 555-5678 ← dos valores en una columna! 2 │ Carlos Lopez │ 555-8888La columna telefonos tiene multiples valores en una sola celda. Esto hace imposible buscar por un telefono especifico.
Solucion: separar en tabla aparte
CREATE TABLE clientes ( id SERIAL PRIMARY KEY, nombre VARCHAR(100));
CREATE TABLE telefonos ( id SERIAL PRIMARY KEY, cliente_id INTEGER REFERENCES clientes(id), telefono VARCHAR(20)); -- clientes -- telefonos id │ nombre id │ cliente_id │ telefono────┼────────── ───┼────────────┼────────── 1 │ Maria Garcia 1 │ 1 │ 555-1234 2 │ Carlos Lopez 2 │ 1 │ 555-5678 3 │ 2 │ 555-8888Ahora puedes buscar WHERE telefono = '555-1234' facilmente.
Nuestra BD tienda ya cumple 1FN
Todas las tablas de tienda tienen valores atomicos y claves primarias. No hay columnas con listas de valores.
Segunda Forma Normal (2FN)
Una tabla esta en 2FN si:
- Esta en 1FN
- Cada columna no-clave depende de toda la clave primaria (no solo de una parte)
Esto solo aplica cuando la clave primaria es compuesta (formada por dos o mas columnas).
Ejemplo que viola 2FN
Imagina una tabla de detalle de pedidos mal disenada:
pedido_id │ producto_id │ cantidad │ precio_unitario │ nombre_producto │ categoria───────────┼─────────────┼──────────┼─────────────────┼─────────────────┼─────────── 1 │ 1 │ 1 │ 1299.99 │ Laptop Pro 15 │ Electronica 1 │ 2 │ 3 │ 29.99 │ Mouse Inalamb. │ Electronica 2 │ 3 │ 1 │ 89.99 │ Teclado Mecanico│ ElectronicaLa clave primaria es (pedido_id, producto_id). Pero:
nombre_productodepende solo deproducto_id(no necesitapedido_id)categoriadepende solo deproducto_id
Esto viola 2FN: hay columnas que dependen de parte de la clave.
Solucion: separar en dos tablas
-- Detalle solo guarda lo que depende de AMBAS clavesCREATE TABLE detalle_pedidos ( pedido_id INTEGER REFERENCES pedidos(id), producto_id INTEGER REFERENCES productos(id), cantidad INTEGER, precio_unitario DECIMAL(10,2), PRIMARY KEY (pedido_id, producto_id));
-- Productos guarda lo que depende solo del productoCREATE TABLE productos ( id SERIAL PRIMARY KEY, nombre VARCHAR(100), categoria VARCHAR(50));Asi es nuestra BD tienda
Nuestra tabla detalle_pedidos solo guarda pedido_id, producto_id, cantidad y precio_unitario. El nombre y la categoria del producto estan en la tabla productos. Cumple 2FN.
Tercera Forma Normal (3FN)
Una tabla esta en 3FN si:
- Esta en 2FN
- Ninguna columna no-clave depende de otra columna no-clave (no hay dependencias transitivas)
Ejemplo que viola 3FN
empleado_id │ nombre │ departamento │ ubicacion_depto─────────────┼───────────┼──────────────┼──────────────── 1 │ Sofia │ Gerencia │ Piso 5 2 │ Juan │ Ventas │ Piso 2 3 │ Valentina │ Ventas │ Piso 2 4 │ Miguel │ Tecnologia │ Piso 3ubicacion_depto depende de departamento, no directamente de empleado_id. La cadena es:
empleado_id → departamento → ubicacion_depto
Esto es una dependencia transitiva: si cambia la ubicacion de Ventas, hay que actualizarla en multiples filas.
Solucion: tabla separada para departamentos
CREATE TABLE departamentos ( id SERIAL PRIMARY KEY, nombre VARCHAR(50), ubicacion VARCHAR(50));
CREATE TABLE empleados ( id SERIAL PRIMARY KEY, nombre VARCHAR(100), departamento_id INTEGER REFERENCES departamentos(id), salario DECIMAL(10,2));Ahora la ubicacion se guarda una sola vez en la tabla departamentos.
Resumen de formas normales
| Comando | Descripcion |
|---|---|
| 1FN | Valores atomicos (una celda = un valor). No hay listas ni arrays en una columna. Cada fila es unica. |
| 2FN | Toda columna no-clave depende de TODA la clave primaria (no solo de una parte). Aplica a claves compuestas. |
| 3FN | No hay dependencias transitivas: cada columna no-clave depende directamente de la clave primaria, no de otra columna no-clave. |
¿Existen mas formas normales?
Si. Existen la BCNF (Boyce-Codd), 4FN y 5FN. Pero en la practica, llegar a 3FN es suficiente para la gran mayoria de bases de datos. Las formas superiores abordan situaciones muy especificas que rara vez se encuentran en el dia a dia.
Nuestra BD tienda: analisis de normalizacion
Veamos como nuestra base de datos cumple con las formas normales:
productos(id, nombre, precio, categoria, stock, fecha_creacion) → 1FN ✓ valores atomicos, id es PK → 2FN ✓ clave simple (id), todo depende de id → 3FN ✓ ninguna columna depende de otra columna no-clave
clientes(id, nombre, email, ciudad, fecha_registro) → 1FN ✓ → 2FN ✓ → 3FN ✓
pedidos(id, cliente_id, fecha, total, estado) → 1FN ✓ → 2FN ✓ → 3FN ✓ (total podria calcularse de detalle_pedidos, pero es un atajo aceptable)
detalle_pedidos(id, pedido_id, producto_id, cantidad, precio_unitario) → 1FN ✓ → 2FN ✓ precio_unitario depende del momento de la compra, no solo del producto → 3FN ✓
empleados(id, nombre, departamento, salario, fecha_contratacion, jefe_id) → 1FN ✓ → 2FN ✓ → 3FN ⚠ departamento como texto podria separarse en una tabla departamentosNormalizacion pragmatica
La tabla empleados tiene departamento como texto en lugar de una referencia a una tabla departamentos. En un sistema real, esto podria generar inconsistencias (alguien escribe “Tecnologia” y otro “tecnologia”). Sin embargo, para un curso introductorio, esta simplificacion es aceptable. En produccion, normalizarias esto.
Desnormalizacion: cuando romper las reglas
A veces, la normalizacion estricta genera consultas con demasiados JOINs que son lentas. En esos casos, se desnormaliza intencionalmente para mejorar el rendimiento.
Cuando desnormalizar
- Consultas de lectura muy frecuentes donde los JOINs son costosos
- Reportes y dashboards que necesitan respuesta rapida
- Data warehouses (almacenes de datos) para analitica
- Campos calculados que se consultan constantemente (ej:
totalen pedidos)
Ejemplo: el campo total en pedidos
En nuestra BD, pedidos.total es un dato desnormalizado: podria calcularse sumando cantidad * precio_unitario de detalle_pedidos. Pero almacenarlo evita recalcular el total cada vez que se consulta:
-- Sin desnormalizacion: calcular el total cada vezSELECT p.id, p.fecha, SUM(dp.cantidad * dp.precio_unitario) AS totalFROM pedidos pJOIN detalle_pedidos dp ON p.id = dp.pedido_idGROUP BY p.id, p.fecha;
-- Con desnormalizacion: leer directamenteSELECT id, fecha, total FROM pedidos;La segunda consulta es mucho mas rapida y simple.
Ejemplo: nombre de categoria como texto
En productos, categoria es un VARCHAR en lugar de un categoria_id con tabla aparte. Esto es una desnormalizacion consciente:
| Comando | Descripcion |
|---|---|
| Normalizado | productos.categoria_id → categorias(id, nombre). Requiere JOIN para mostrar el nombre. |
| Desnormalizado | productos.categoria = 'Electronica'. No requiere JOIN, pero riesgo de inconsistencia. |
Desnormalizar con conciencia
La desnormalizacion es una decision deliberada basada en el analisis de rendimiento. Nunca desnormalices por pereza o por no saber normalizar. Primero normaliza correctamente, y luego desnormaliza donde el rendimiento lo justifique, documentando la razon.
Disenar una tabla normalizada: paso a paso
Si necesitas crear una nueva estructura, sigue estos pasos:
- Lista todas las entidades (sustantivos: cliente, producto, pedido, etc.)
- Lista los atributos de cada entidad (columnas)
- Identifica las claves primarias (¿que identifica unicamente a cada registro?)
- Identifica las relaciones (¿que entidades se conectan entre si?)
- Aplica 1FN: ¿hay columnas con multiples valores? → separar en tabla
- Aplica 2FN: ¿hay columnas que dependen de parte de la clave? → mover a otra tabla
- Aplica 3FN: ¿hay dependencias transitivas? → crear tabla intermedia
- Evalua desnormalizacion: ¿hay consultas criticas que se benefician de redundancia controlada?
Ejercicios
Ejercicio 1: Identifica que forma normal viola esta tabla y explica como la normalizarias:
orden_id │ cliente │ email │ productos──────────┼─────────┼────────────────┼────────────────────────── 1 │ Maria │ maria@mail.com │ Laptop, Mouse, Teclado 2 │ Carlos │ carlos@mail.com│ Monitor 3 │ Maria │ maria@mail.com │ SillaVer solucion
Viola 1FN: la columna productos tiene multiples valores en una celda (“Laptop, Mouse, Teclado”).
Tambien hay redundancia: Maria aparece dos veces con su email repetido (potencial anomalia de actualizacion).
Normalizacion:
-- Separar en 3 tablasCREATE TABLE clientes ( id SERIAL PRIMARY KEY, nombre VARCHAR(100), email VARCHAR(100));
CREATE TABLE ordenes ( id SERIAL PRIMARY KEY, cliente_id INTEGER REFERENCES clientes(id), fecha DATE);
CREATE TABLE detalle_ordenes ( id SERIAL PRIMARY KEY, orden_id INTEGER REFERENCES ordenes(id), producto VARCHAR(100));Ahora cada producto tiene su propia fila y los datos del cliente estan en un solo lugar.
Ejercicio 2: Mira la tabla empleados de nuestra BD. ¿Cumple estrictamente con 3FN? Si no, ¿como la normalizarias? Escribe el SQL para crear la estructura normalizada.
Ver solucion
La tabla empleados tiene departamento como texto. Si el departamento tuviera mas atributos (ubicacion, gerente, presupuesto), seria una dependencia transitiva: id → departamento → ubicacion_depto.
Normalizacion estricta:
CREATE TABLE departamentos ( id SERIAL PRIMARY KEY, nombre VARCHAR(50) NOT NULL UNIQUE, ubicacion VARCHAR(100));
CREATE TABLE empleados_normalizado ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, departamento_id INTEGER REFERENCES departamentos(id), salario DECIMAL(10,2), fecha_contratacion DATE, jefe_id INTEGER REFERENCES empleados_normalizado(id));
-- Poblar departamentosINSERT INTO departamentos (nombre) VALUES ('Gerencia'), ('Ventas'), ('Tecnologia'), ('Soporte');
-- Migrar empleadosINSERT INTO empleados_normalizado (id, nombre, departamento_id, salario, fecha_contratacion, jefe_id)SELECT e.id, e.nombre, d.id, e.salario, e.fecha_contratacion, e.jefe_idFROM empleados eJOIN departamentos d ON e.departamento = d.nombre;Ejercicio 3: ¿Por que detalle_pedidos guarda precio_unitario si ese dato ya existe en productos.precio? ¿Es redundancia o tiene una razon valida?
Ver solucion
No es redundancia innecesaria, es una desnormalizacion con una razon muy valida: el precio de un producto puede cambiar con el tiempo.
Si detalle_pedidos solo guardara producto_id y obtuviera el precio de productos, entonces al subir el precio de un producto, todos los pedidos historicos mostrarian el precio nuevo, no el que realmente se pago.
precio_unitario en detalle_pedidos captura el precio en el momento de la compra. Es un dato historico que no debe cambiar aunque el precio actual del producto cambie.
Este patron se llama snapshot de precio y es una practica estandar en sistemas de ventas.
Ejercicio 4: Disena una tabla para un sistema de biblioteca que almacene: libros, autores (un libro puede tener varios autores) y prestamos. Aplica al menos 3FN.
Ver solucion
-- AutoresCREATE TABLE autores ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, nacionalidad VARCHAR(50));
-- LibrosCREATE TABLE libros ( id SERIAL PRIMARY KEY, titulo VARCHAR(200) NOT NULL, isbn VARCHAR(20) UNIQUE, anio_publicacion INTEGER, genero VARCHAR(50));
-- Relacion muchos-a-muchos: un libro puede tener varios autoresCREATE TABLE libro_autores ( libro_id INTEGER REFERENCES libros(id), autor_id INTEGER REFERENCES autores(id), PRIMARY KEY (libro_id, autor_id));
-- Socios de la bibliotecaCREATE TABLE socios ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, email VARCHAR(100));
-- PrestamosCREATE TABLE prestamos ( id SERIAL PRIMARY KEY, libro_id INTEGER REFERENCES libros(id), socio_id INTEGER REFERENCES socios(id), fecha_prestamo DATE DEFAULT CURRENT_DATE, fecha_devolucion DATE, estado VARCHAR(20) DEFAULT 'prestado');Justificacion:
- 1FN: Un libro con varios autores no se resuelve con una columna “autores” (lista), sino con la tabla intermedia
libro_autores. - 2FN:
libro_autorestiene clave compuesta y no hay dependencias parciales. - 3FN: No hay dependencias transitivas. El genero depende del libro, la nacionalidad del autor.
Ejercicio 5: Consulta la BD tienda y verifica que no hay datos inconsistentes. Busca si algun producto tiene una categoria que no sea ‘Electronica’, ‘Muebles’ o ‘Accesorios’. ¿Que restriccion le falta a la tabla para prevenir esto?
Ver solucion
-- Verificar categorias existentesSELECT DISTINCT categoria FROM productos ORDER BY categoria;
-- Buscar categorias inesperadasSELECT * FROM productosWHERE categoria NOT IN ('Electronica', 'Muebles', 'Accesorios');La tabla productos no tiene una restriccion que limite las categorias validas. Para prevenirlo, podrias:
-- Opcion 1: restriccion CHECKALTER TABLE productosADD CONSTRAINT chk_categoriaCHECK (categoria IN ('Electronica', 'Muebles', 'Accesorios'));
-- Opcion 2: tabla de categorias (normalizacion)CREATE TABLE categorias ( id SERIAL PRIMARY KEY, nombre VARCHAR(50) NOT NULL UNIQUE);
-- Y cambiar productos.categoria por productos.categoria_id con FKLa opcion 2 (normalizar) es mejor si las categorias pueden crecer o tener mas atributos. La opcion 1 (CHECK) es mas simple si las categorias son fijas y pocas.
Ejercicio 6 (Desafio): Tienes esta tabla desnormalizada de un e-commerce. Identificar las anomalias, normalizar a 3FN y escribir el SQL para crear las tablas:
venta_id │ fecha │ cliente │ email │ ciudad │ producto │ categoria │ precio │ cantidad │ vendedor │ comision_pctVer solucion
Anomalias:
- Actualizacion: cambiar email de un cliente requiere actualizar multiples filas
- Insercion: no puedes registrar un producto sin una venta
- Eliminacion: borrar la unica venta de un cliente borra toda su informacion
Normalizacion a 3FN:
CREATE TABLE clientes_norm ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, email VARCHAR(100) UNIQUE, ciudad VARCHAR(50));
CREATE TABLE categorias_norm ( id SERIAL PRIMARY KEY, nombre VARCHAR(50) NOT NULL UNIQUE);
CREATE TABLE productos_norm ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, categoria_id INTEGER REFERENCES categorias_norm(id), precio DECIMAL(10,2) NOT NULL);
CREATE TABLE vendedores ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL, comision_pct DECIMAL(5,2));
CREATE TABLE ventas ( id SERIAL PRIMARY KEY, fecha DATE DEFAULT CURRENT_DATE, cliente_id INTEGER REFERENCES clientes_norm(id), vendedor_id INTEGER REFERENCES vendedores(id));
CREATE TABLE detalle_ventas ( id SERIAL PRIMARY KEY, venta_id INTEGER REFERENCES ventas(id), producto_id INTEGER REFERENCES productos_norm(id), cantidad INTEGER NOT NULL, precio_unitario DECIMAL(10,2) NOT NULL -- snapshot del precio al momento);Entidades identificadas: clientes, categorias, productos, vendedores, ventas, detalle_ventas. Cada una solo contiene los atributos que dependen directamente de su clave primaria.
Modelo dimensional: hechos y dimensiones
En el modulo anterior aprendiste a normalizar una base de datos para evitar redundancia. Pero las bases de datos normalizadas estan optimizadas para escribir datos (insertar, actualizar), no para analizarlos. Cuando necesitas hacer analisis sobre grandes volumenes de datos, necesitas una estructura diferente: el modelo dimensional.
¿Donde se usa esto?
El modelo dimensional es la base de los data warehouses (almacenes de datos) y herramientas de Business Intelligence como Tableau, Power BI y Looker. Si trabajas en ciencia de datos o analitica, vas a encontrarte con este modelo constantemente.
OLTP vs OLAP: dos mundos diferentes
Las bases de datos se usan para dos propositos muy distintos:
| Comando | Descripcion |
|---|---|
| OLTP (Online Transaction Processing) | Operaciones del dia a dia: insertar pedidos, actualizar stock, registrar clientes. Muchas escrituras pequenas y rapidas. Estructura normalizada (3FN). |
| OLAP (Online Analytical Processing) | Analisis y reportes: ventas por mes, tendencias, comparaciones. Lecturas masivas sobre grandes volumenes. Estructura desnormalizada (modelo dimensional). |
Nuestra BD tienda es OLTP: esta normalizada para registrar transacciones. Pero si quisieras analizar las ventas de los ultimos 3 anos cruzando datos de productos, clientes, tiempo y vendedores, la estructura normalizada requiere muchos JOINs y es lenta para volumen.
El modelo dimensional reorganiza esos mismos datos para hacer el analisis rapido y natural.
Tablas de hechos y dimensiones
El modelo dimensional se basa en dos tipos de tablas:
Tabla de hechos (Fact table)
Contiene los eventos medibles del negocio: ventas, pedidos, transacciones, clics. Cada fila es un evento y tiene:
- Claves foraneas que apuntan a las tablas de dimensiones
- Medidas (metricas numericas): cantidad vendida, monto, duracion, etc.
-- Tabla de hechos: cada fila es una linea de ventaCREATE TABLE fact_ventas ( venta_id INTEGER, fecha_id INTEGER, -- FK a dim_fecha producto_id INTEGER, -- FK a dim_producto cliente_id INTEGER, -- FK a dim_cliente -- Medidas (lo que quieres analizar) cantidad INTEGER, monto DECIMAL(10,2), descuento DECIMAL(10,2), costo DECIMAL(10,2));Tabla de dimensiones (Dimension table)
Contiene las descripciones y contexto de los hechos: quien compro, que producto, cuando, donde. Son tablas anchas con muchos atributos descriptivos:
-- Dimension de producto: describe cada productoCREATE TABLE dim_producto ( producto_id INTEGER PRIMARY KEY, nombre VARCHAR(100), categoria VARCHAR(50), subcategoria VARCHAR(50), marca VARCHAR(50), precio_lista DECIMAL(10,2));
-- Dimension de cliente: describe cada clienteCREATE TABLE dim_cliente ( cliente_id INTEGER PRIMARY KEY, nombre VARCHAR(100), email VARCHAR(100), ciudad VARCHAR(50), region VARCHAR(50), segmento VARCHAR(50) -- 'Premium', 'Regular', 'Nuevo');
-- Dimension de fecha: describe cada diaCREATE TABLE dim_fecha ( fecha_id INTEGER PRIMARY KEY, fecha DATE, dia INTEGER, mes INTEGER, trimestre INTEGER, anio INTEGER, nombre_mes VARCHAR(20), nombre_dia VARCHAR(20), es_fin_de_semana BOOLEAN);La dimension de fecha es especial
La tabla dim_fecha siempre existe en un modelo dimensional. Se pre-carga con todos los dias de un rango (ej: 2020-2030) y tiene columnas calculadas como el nombre del mes, trimestre, si es feriado, etc. Esto permite agrupar facilmente por cualquier periodo sin funciones como EXTRACT.
Esquema estrella (Star Schema)
El esquema estrella es la forma mas comun de organizar un modelo dimensional. La tabla de hechos esta en el centro, rodeada por las dimensiones:
dim_fecha │ │ fecha_id │ dim_cliente ──── fact_ventas ──── dim_producto cliente_id │ producto_id │ │ vendedor_id │ dim_vendedorSe llama “estrella” porque visualmente la tabla de hechos es el centro y las dimensiones son las puntas.
Ventajas del esquema estrella
- Consultas simples: maximo 1 JOIN por dimension
- Rendimiento: pocas tablas, JOINs directos, facil de optimizar
- Intuitivo: los usuarios de negocio entienden la estructura facilmente
Esquema copo de nieve (Snowflake Schema)
Es una variacion donde las dimensiones estan normalizadas: en lugar de una tabla dim_producto con todos los atributos, tienes dim_producto → dim_categoria → dim_subcategoria.
dim_fecha │ dim_cliente ──── fact_ventas ──── dim_producto ──── dim_categoria │ dim_vendedor ──── dim_region| Comando | Descripcion |
|---|---|
| Esquema estrella | Dimensiones desnormalizadas (anchas). Menos JOINs, mas rapido para consultas. Es el mas usado. |
| Esquema copo de nieve | Dimensiones normalizadas. Ahorra espacio pero requiere mas JOINs. Menos comun en la practica. |
En la practica, usa estrella
El esquema estrella es el estandar de la industria. El ahorro de espacio del copo de nieve rara vez justifica la complejidad adicional de los JOINs. Las herramientas de BI estan optimizadas para trabajar con esquemas estrella.
Transformando tienda a modelo dimensional
Veamos como convertiria nuestra BD tienda (OLTP) a un modelo dimensional (OLAP):
Paso 1: Identificar los hechos
El evento medible principal es la venta de productos. Cada linea de detalle_pedidos es un hecho.
Paso 2: Identificar las dimensiones
- Producto: nombre, categoria, precio
- Cliente: nombre, ciudad
- Fecha: datos temporales del pedido
- Estado del pedido: completado, enviado, pendiente
Paso 3: Crear las tablas dimensionales
-- Dimension fecha (pre-cargada)CREATE TABLE dim_fecha ( fecha_id INTEGER PRIMARY KEY, fecha DATE NOT NULL, dia INTEGER, mes INTEGER, trimestre INTEGER, anio INTEGER, nombre_mes VARCHAR(20), dia_semana VARCHAR(20), es_fin_de_semana BOOLEAN);
-- Cargar fechas para 2024INSERT INTO dim_fechaSELECT (EXTRACT(YEAR FROM d) * 10000 + EXTRACT(MONTH FROM d) * 100 + EXTRACT(DAY FROM d))::INTEGER AS fecha_id, d AS fecha, EXTRACT(DAY FROM d)::INTEGER AS dia, EXTRACT(MONTH FROM d)::INTEGER AS mes, EXTRACT(QUARTER FROM d)::INTEGER AS trimestre, EXTRACT(YEAR FROM d)::INTEGER AS anio, TO_CHAR(d, 'Month') AS nombre_mes, TO_CHAR(d, 'Day') AS dia_semana, EXTRACT(DOW FROM d) IN (0, 6) AS es_fin_de_semanaFROM generate_series('2024-01-01'::DATE, '2024-12-31'::DATE, '1 day') AS d;
-- Dimension productoCREATE TABLE dim_producto ASSELECT id AS producto_id, nombre, categoria, precio AS precio_listaFROM productos;
-- Dimension clienteCREATE TABLE dim_cliente ASSELECT id AS cliente_id, nombre, email, ciudadFROM clientes;Paso 4: Crear la tabla de hechos
CREATE TABLE fact_ventas ASSELECT dp.id AS venta_id, (EXTRACT(YEAR FROM pe.fecha) * 10000 + EXTRACT(MONTH FROM pe.fecha) * 100 + EXTRACT(DAY FROM pe.fecha))::INTEGER AS fecha_id, dp.producto_id, pe.cliente_id, pe.estado, dp.cantidad, dp.precio_unitario, dp.cantidad * dp.precio_unitario AS monto_totalFROM detalle_pedidos dpJOIN pedidos pe ON dp.pedido_id = pe.id;Paso 5: Consultar el modelo dimensional
Ahora las consultas analiticas son simples y directas:
-- Ventas por categoria y mesSELECT dp.categoria, df.nombre_mes, df.anio, SUM(fv.monto_total) AS total_ventas, SUM(fv.cantidad) AS unidadesFROM fact_ventas fvJOIN dim_producto dp ON fv.producto_id = dp.producto_idJOIN dim_fecha df ON fv.fecha_id = df.fecha_idGROUP BY dp.categoria, df.nombre_mes, df.anio, df.mesORDER BY df.anio, df.mes;
-- Top clientes por ciudad y trimestreSELECT dc.ciudad, df.trimestre, dc.nombre, SUM(fv.monto_total) AS gasto_totalFROM fact_ventas fvJOIN dim_cliente dc ON fv.cliente_id = dc.cliente_idJOIN dim_fecha df ON fv.fecha_id = df.fecha_idGROUP BY dc.ciudad, df.trimestre, dc.nombreORDER BY dc.ciudad, df.trimestre, gasto_total DESC;Nota sobre el rendimiento
Con 15 productos y 15 pedidos, no vas a notar diferencia de rendimiento. La ventaja del modelo dimensional se manifiesta con millones de filas, donde la estructura desnormalizada y los JOINs simples marcan una diferencia enorme.
Tipos de tablas de hechos
No todas las tablas de hechos son iguales. Existen tres tipos principales:
| Comando | Descripcion |
|---|---|
| Hechos transaccionales | Un registro por evento/transaccion. Es el mas comun. Ejemplo: cada linea de venta. |
| Hechos periodicos (snapshot) | Un registro por periodo fijo. Ejemplo: stock al final de cada dia, saldo al cierre de mes. |
| Hechos acumulativos | Registro que se actualiza en el tiempo. Ejemplo: un pedido que pasa por estados (creado → enviado → entregado) con fechas. |
Nuestra fact_ventas es transaccional: cada fila es una linea de venta individual.
Un ejemplo de hechos periodicos seria:
-- Snapshot diario de stockCREATE TABLE fact_stock_diario ( fecha_id INTEGER, producto_id INTEGER, stock_al_cierre INTEGER, unidades_vendidas_dia INTEGER, unidades_recibidas_dia INTEGER);Slowly Changing Dimensions (SCD)
Un problema comun: ¿que pasa cuando los datos de una dimension cambian? Si un cliente se muda de Santiago a Valparaiso, ¿actualizas la dimension y pierdes el historial?
| Comando | Descripcion |
|---|---|
| SCD Tipo 1: Sobreescribir | Simplemente actualizas el valor. Se pierde el historial. Util cuando no importa la historia (ej: corregir un error). |
| SCD Tipo 2: Nueva fila | Creas una nueva fila con los datos nuevos y marcas la anterior como inactiva. Preserva el historial completo. |
| SCD Tipo 3: Nueva columna | Agregas una columna 'valor_anterior'. Solo guarda el cambio mas reciente, no el historial completo. |
SCD Tipo 2: el mas usado
-- Dimension cliente con historial (SCD Tipo 2)CREATE TABLE dim_cliente_scd2 ( cliente_sk SERIAL PRIMARY KEY, -- surrogate key (clave sintetica) cliente_id INTEGER, -- clave natural (id original) nombre VARCHAR(100), ciudad VARCHAR(50), fecha_inicio DATE, -- desde cuando es valido fecha_fin DATE, -- hasta cuando (NULL = activo) es_actual BOOLEAN DEFAULT TRUE); cliente_sk │ cliente_id │ nombre │ ciudad │ fecha_inicio │ fecha_fin │ es_actual────────────┼────────────┼──────────────┼─────────────┼──────────────┼────────────┼────────── 1 │ 1 │ Maria Garcia │ Santiago │ 2024-01-01 │ 2024-06-30 │ FALSE 2 │ 1 │ Maria Garcia │ Valparaiso │ 2024-07-01 │ NULL │ TRUE- Para analisis actual: filtrar con
WHERE es_actual = TRUE - Para analisis historico: hacer JOIN por rango de fechas
Surrogate keys
En el modelo dimensional, las dimensiones SCD Tipo 2 usan una surrogate key (clave sintetica auto-incremental) como PK en lugar de la clave natural. Esto permite tener multiples filas para el mismo cliente (una por cada version historica).
Medidas: aditivas, semi-aditivas y no aditivas
Las medidas (metricas) en la tabla de hechos se clasifican segun como se pueden agregar:
| Comando | Descripcion |
|---|---|
| Aditivas | Se pueden sumar en todas las dimensiones. Ejemplo: monto de venta, cantidad. SUM siempre tiene sentido. |
| Semi-aditivas | Se pueden sumar en algunas dimensiones pero no en otras. Ejemplo: saldo de cuenta (puedes sumar por cliente, pero no por tiempo). |
| No aditivas | No se pueden sumar. Ejemplo: porcentaje de descuento, precio unitario. Requieren AVG, MAX o calculo especial. |
-- Ejemplo: medidas aditivas (se pueden sumar libremente)SELECT dp.categoria, SUM(fv.monto_total) AS ventas_totales, -- aditiva: OK sumar SUM(fv.cantidad) AS unidades_totales -- aditiva: OK sumarFROM fact_ventas fvJOIN dim_producto dp ON fv.producto_id = dp.producto_idGROUP BY dp.categoria;
-- Ejemplo: medida no aditiva (NO sumar, usar AVG)SELECT dp.categoria, ROUND(AVG(fv.precio_unitario), 2) AS precio_promedio -- no aditivaFROM fact_ventas fvJOIN dim_producto dp ON fv.producto_id = dp.producto_idGROUP BY dp.categoria;Modelo dimensional vs normalizado: resumen
| Comando | Descripcion |
|---|---|
| Proposito | Normalizado: transacciones (OLTP). Dimensional: analisis (OLAP). |
| Estructura | Normalizado: muchas tablas, sin redundancia. Dimensional: pocas tablas, redundancia controlada. |
| JOINs | Normalizado: muchos, complejos. Dimensional: pocos, simples (estrella). |
| Escritura | Normalizado: rapido y seguro. Dimensional: mas lento (transformaciones ETL). |
| Lectura/analisis | Normalizado: puede ser lento. Dimensional: optimizado para grandes volumenes. |
| Usuarios | Normalizado: desarrolladores. Dimensional: analistas, herramientas BI. |
No es uno u otro
En la practica, las empresas tienen ambos: una base OLTP normalizada para las operaciones diarias, y un data warehouse dimensional para analitica. Un proceso llamado ETL (Extract, Transform, Load) copia y transforma los datos del OLTP al warehouse periodicamente.
Ejercicios
Ejercicio 1: Usando la BD tienda, crea una dimension de fecha (dim_fecha) con los campos: fecha_id, fecha, dia, mes, trimestre, anio, nombre_mes. Cargala con todas las fechas de 2024.
Ver solucion
CREATE TABLE dim_fecha ( fecha_id INTEGER PRIMARY KEY, fecha DATE NOT NULL, dia INTEGER, mes INTEGER, trimestre INTEGER, anio INTEGER, nombre_mes VARCHAR(20));
INSERT INTO dim_fechaSELECT (EXTRACT(YEAR FROM d) * 10000 + EXTRACT(MONTH FROM d) * 100 + EXTRACT(DAY FROM d))::INTEGER, d, EXTRACT(DAY FROM d)::INTEGER, EXTRACT(MONTH FROM d)::INTEGER, EXTRACT(QUARTER FROM d)::INTEGER, EXTRACT(YEAR FROM d)::INTEGER, TO_CHAR(d, 'Month')FROM generate_series('2024-01-01'::DATE, '2024-12-31'::DATE, '1 day') AS d;
-- VerificarSELECT * FROM dim_fecha LIMIT 10;SELECT COUNT(*) FROM dim_fecha; -- deberia dar 366 (2024 es bisiesto)Ejercicio 2: Crea una tabla de hechos fact_ventas a partir de detalle_pedidos y pedidos. Debe incluir: venta_id, fecha_id (formato YYYYMMDD), producto_id, cliente_id, cantidad, precio_unitario y monto_total.
Ver solucion
CREATE TABLE fact_ventas ASSELECT dp.id AS venta_id, (EXTRACT(YEAR FROM pe.fecha) * 10000 + EXTRACT(MONTH FROM pe.fecha) * 100 + EXTRACT(DAY FROM pe.fecha))::INTEGER AS fecha_id, dp.producto_id, pe.cliente_id, dp.cantidad, dp.precio_unitario, dp.cantidad * dp.precio_unitario AS monto_totalFROM detalle_pedidos dpJOIN pedidos pe ON dp.pedido_id = pe.id;
-- VerificarSELECT COUNT(*) FROM fact_ventas;SELECT * FROM fact_ventas LIMIT 5;Ejercicio 3: Usando el modelo dimensional creado en los ejercicios anteriores, escribe una consulta que muestre las ventas totales por categoria y por trimestre. Compara la complejidad con la misma consulta usando el modelo OLTP original.
Ver solucion
-- Con modelo dimensional (simple y directo)SELECT dp.categoria, df.trimestre, SUM(fv.monto_total) AS total_ventas, SUM(fv.cantidad) AS unidadesFROM fact_ventas fvJOIN dim_producto dp ON fv.producto_id = dp.producto_idJOIN dim_fecha df ON fv.fecha_id = df.fecha_idGROUP BY dp.categoria, df.trimestreORDER BY dp.categoria, df.trimestre;
-- Con modelo OLTP (mas JOINs y funciones)SELECT pr.categoria, EXTRACT(QUARTER FROM pe.fecha) AS trimestre, SUM(det.cantidad * det.precio_unitario) AS total_ventas, SUM(det.cantidad) AS unidadesFROM detalle_pedidos detJOIN pedidos pe ON det.pedido_id = pe.idJOIN productos pr ON det.producto_id = pr.idGROUP BY pr.categoria, EXTRACT(QUARTER FROM pe.fecha)ORDER BY pr.categoria, trimestre;Ambas dan el mismo resultado, pero la version dimensional:
- Usa
df.trimestredirectamente (sin EXTRACT) - El monto ya esta precalculado en
fact_ventas - Con millones de filas, la diferencia de rendimiento es significativa
Ejercicio 4: ¿Cual de estas medidas es aditiva, semi-aditiva o no aditiva? Justifica.
- (a) Cantidad vendida
- (b) Precio unitario
- (c) Stock al cierre del dia
- (d) Monto total de venta
- (e) Porcentaje de descuento
Ver solucion
-
(a) Cantidad vendida → Aditiva. Puedes sumar cantidades por producto, por cliente, por tiempo. Siempre tiene sentido: “vendimos 50 unidades en enero + 60 en febrero = 110 en el bimestre”.
-
(b) Precio unitario → No aditiva. Sumar precios no tiene sentido. Debes usar AVG (precio promedio) o no agregar.
-
(c) Stock al cierre del dia → Semi-aditiva. Puedes sumar stock de diferentes productos (stock total), pero NO sumar stock de diferentes dias (el stock de lunes + martes no es el stock real). Usa LAST o MAX por tiempo.
-
(d) Monto total de venta → Aditiva. Puedes sumar montos por cualquier dimension.
-
(e) Porcentaje de descuento → No aditiva. Sumar porcentajes no tiene sentido. Usa AVG ponderado si necesitas un descuento “promedio”.
Ejercicio 5: Disena un modelo dimensional (estrella) para un hospital que necesita analizar: numero de consultas medicas, duracion promedio de consultas, e ingresos por consulta. Las dimensiones son: medico, paciente, diagnostico y fecha. Escribe el SQL para crear las tablas.
Ver solucion
-- Dimension medicoCREATE TABLE dim_medico ( medico_id INTEGER PRIMARY KEY, nombre VARCHAR(100), especialidad VARCHAR(50), departamento VARCHAR(50));
-- Dimension pacienteCREATE TABLE dim_paciente ( paciente_id INTEGER PRIMARY KEY, nombre VARCHAR(100), fecha_nacimiento DATE, genero VARCHAR(20), ciudad VARCHAR(50), prevision VARCHAR(50) -- 'FONASA', 'Isapre', etc.);
-- Dimension diagnosticoCREATE TABLE dim_diagnostico ( diagnostico_id INTEGER PRIMARY KEY, codigo_cie10 VARCHAR(10), nombre VARCHAR(200), categoria VARCHAR(100), es_cronico BOOLEAN);
-- Dimension fecha (igual que antes)CREATE TABLE dim_fecha_hospital ( fecha_id INTEGER PRIMARY KEY, fecha DATE, dia INTEGER, mes INTEGER, trimestre INTEGER, anio INTEGER, nombre_mes VARCHAR(20), es_fin_de_semana BOOLEAN);
-- Tabla de hechos: cada fila es una consulta medicaCREATE TABLE fact_consultas ( consulta_id INTEGER PRIMARY KEY, fecha_id INTEGER REFERENCES dim_fecha_hospital(fecha_id), medico_id INTEGER REFERENCES dim_medico(medico_id), paciente_id INTEGER REFERENCES dim_paciente(paciente_id), diagnostico_id INTEGER REFERENCES dim_diagnostico(diagnostico_id), -- Medidas duracion_minutos INTEGER, -- aditiva costo_consulta DECIMAL(10,2), -- aditiva medicamentos_recetados INTEGER -- aditiva);
-- Ejemplo de consulta analiticaSELECT dm.especialidad, df.trimestre, COUNT(*) AS total_consultas, ROUND(AVG(fc.duracion_minutos), 1) AS duracion_promedio, SUM(fc.costo_consulta) AS ingresos_totalesFROM fact_consultas fcJOIN dim_medico dm ON fc.medico_id = dm.medico_idJOIN dim_fecha_hospital df ON fc.fecha_id = df.fecha_idGROUP BY dm.especialidad, df.trimestreORDER BY dm.especialidad, df.trimestre;Ejercicio 6 (Desafio): Implementa un SCD Tipo 2 para la dimension de clientes. Crea la tabla dim_cliente_historico con surrogate key, campos de vigencia (fecha_inicio, fecha_fin) y flag es_actual. Luego simula que Maria Garcia se muda de Santiago a Valparaiso: inserta la nueva version y actualiza la anterior.
Ver solucion
-- Crear dimension con historialCREATE TABLE dim_cliente_historico ( cliente_sk SERIAL PRIMARY KEY, cliente_id INTEGER NOT NULL, nombre VARCHAR(100), email VARCHAR(100), ciudad VARCHAR(50), fecha_inicio DATE NOT NULL, fecha_fin DATE, es_actual BOOLEAN DEFAULT TRUE);
-- Cargar version inicial desde la BD OLTPINSERT INTO dim_cliente_historico (cliente_id, nombre, email, ciudad, fecha_inicio)SELECT id, nombre, email, ciudad, '2024-01-01'FROM clientes;
-- VerificarSELECT * FROM dim_cliente_historico WHERE cliente_id = 1;-- Maria Garcia, Santiago, fecha_inicio=2024-01-01, es_actual=TRUE
-- Simular cambio: Maria se muda a Valparaiso el 2024-07-01BEGIN;
-- 1. Cerrar la version anteriorUPDATE dim_cliente_historicoSET fecha_fin = '2024-06-30', es_actual = FALSEWHERE cliente_id = 1 AND es_actual = TRUE;
-- 2. Insertar nueva versionINSERT INTO dim_cliente_historico (cliente_id, nombre, email, ciudad, fecha_inicio)VALUES (1, 'Maria Garcia', 'maria@email.com', 'Valparaiso', '2024-07-01');
COMMIT;
-- Verificar el historialSELECT * FROM dim_cliente_historico WHERE cliente_id = 1 ORDER BY fecha_inicio; cliente_sk │ cliente_id │ nombre │ ciudad │ fecha_inicio │ fecha_fin │ es_actual────────────┼────────────┼──────────────┼─────────────┼──────────────┼────────────┼────────── 1 │ 1 │ Maria Garcia │ Santiago │ 2024-01-01 │ 2024-06-30 │ FALSE 11 │ 1 │ Maria Garcia │ Valparaiso │ 2024-07-01 │ NULL │ TRUEPara consultar ventas de Maria usando la ciudad correcta en cada momento:
SELECT dc.ciudad, SUM(fv.monto_total) AS totalFROM fact_ventas fvJOIN dim_fecha df ON fv.fecha_id = df.fecha_idJOIN dim_cliente_historico dc ON fv.cliente_id = dc.cliente_id AND df.fecha BETWEEN dc.fecha_inicio AND COALESCE(dc.fecha_fin, '9999-12-31')WHERE dc.cliente_id = 1GROUP BY dc.ciudad;Transacciones: BEGIN, COMMIT y ROLLBACK
Cuando ejecutas un INSERT, UPDATE o DELETE, PostgreSQL lo aplica inmediatamente. Pero que pasa si necesitas hacer varias operaciones que dependen entre si? Si la primera funciona pero la segunda falla, tus datos quedan en un estado inconsistente. Las transacciones resuelven exactamente este problema.
Que es una transaccion?
Una transaccion es un grupo de operaciones SQL que se ejecutan como una unidad. O se aplican todas o no se aplica ninguna. No hay estados intermedios.
Piensa en un pedido de nuestra tienda. Procesar un pedido requiere varias operaciones:
1. Insertar el pedido en la tabla pedidos2. Insertar cada producto en detalle_pedidos3. Actualizar el stock de cada producto
Si el paso 3 falla (por ejemplo, no hay suficiente stock),NO queremos que los pasos 1 y 2 se queden en la base de datos.Necesitamos deshacer todo.Sin transacciones, si falla el paso 3, te quedarias con un pedido registrado pero sin el stock actualizado. Con transacciones, si algo falla, todo se revierte automaticamente.
BEGIN, COMMIT y ROLLBACK
Estas son las tres sentencias fundamentales:
| Comando | Descripcion |
|---|---|
| BEGIN | Inicia una transaccion. Todo lo que ejecutes despues queda 'en espera' hasta que confirmes o reviertas. |
| COMMIT | Confirma la transaccion. Todos los cambios se aplican de forma permanente a la base de datos. |
| ROLLBACK | Revierte la transaccion. Todos los cambios desde el BEGIN se deshacen como si nunca hubieran ocurrido. |
Ejemplo basico
-- Iniciar la transaccionBEGIN;
-- Insertar un nuevo pedidoINSERT INTO pedidos (cliente_id, fecha, total, estado)VALUES (1, CURRENT_DATE, 299.99, 'pendiente');
-- Ver que el pedido ya existe (dentro de la transaccion)SELECT * FROM pedidos WHERE total = 299.99;
-- Si todo esta bien, confirmarCOMMIT;
-- Ahora el pedido es permanenteY si algo sale mal:
BEGIN;
-- Intentamos actualizar preciosUPDATE productos SET precio = precio * 0.8WHERE categoria = 'Electronica';
-- Ups! No queriamos aplicar 20% de descuento...-- Deshacemos TODO lo que hicimos desde BEGINROLLBACK;
-- Los precios quedan exactamente como estaban antesPaso a paso: que ocurre internamente
BEGIN; │ ├─ PostgreSQL marca el inicio de la transaccion. │ Los cambios se escriben en un "log" temporal. │ ├─ INSERT INTO pedidos ... │ → El pedido existe para TI, pero otros usuarios │ aun no lo ven (aislamiento). │ ├─ UPDATE productos SET stock = stock - 1 ... │ → El stock cambia para TI, pero otros ven │ el valor original. │ └─ COMMIT; ← Aqui PostgreSQL hace permanentes │ todos los cambios de golpe. │ Ahora todos los usuarios los ven. │ └─ (Si hubieramos hecho ROLLBACK, PostgreSQL descarta el log y todo queda como antes)Autocommit
Por defecto, PostgreSQL funciona en modo autocommit: cada sentencia SQL individual es su propia transaccion. Cuando ejecutas UPDATE productos SET precio = 99 WHERE id = 1; sin BEGIN, PostgreSQL hace automaticamente BEGIN → UPDATE → COMMIT. Por eso los cambios son inmediatos. Cuando usas BEGIN explicitamente, desactivas el autocommit hasta el COMMIT o ROLLBACK.
Transacciones e integridad de datos
Las transacciones no son solo una conveniencia — son la herramienta fundamental para mantener la integridad de tu base de datos. Sin ellas, cualquier fallo a mitad de una operacion puede dejar tus datos en un estado corrupto e irrecuperable.
Que puede salir mal sin transacciones?
Veamos escenarios reales con nuestra tienda:
Escenario 1: Pedido a medias Sin transaccion: INSERT INTO pedidos (...) → ✓ Pedido creado INSERT INTO detalle_pedidos (...) → ✓ Detalle creado UPDATE productos SET stock = stock - 5 → ✗ ERROR (conexion se cayo)
Resultado: Hay un pedido registrado, pero el stock no se desconto. Se vendera stock que no existe. Los datos son INCONSISTENTES.
Escenario 2: Transferencia entre cuentas Sin transaccion: UPDATE cuentas SET saldo = saldo - 1000 WHERE id = 1 → ✓ Se desconto UPDATE cuentas SET saldo = saldo + 1000 WHERE id = 2 → ✗ ERROR
Resultado: Se desconto dinero de una cuenta pero no llego a la otra. El dinero "desaparecio". Los datos son INCONSISTENTES.
Escenario 3: Eliminacion con dependencias Sin transaccion: DELETE FROM detalle_pedidos WHERE pedido_id = 5 → ✓ Detalles borrados DELETE FROM pedidos WHERE id = 5 → ✗ ERROR
Resultado: Los detalles se eliminaron pero el pedido sigue. Pedido fantasma sin productos. Los datos son INCONSISTENTES.Con transacciones, ninguno de estos escenarios puede ocurrir. Si algo falla, todo se revierte automaticamente al estado anterior.
Restricciones y transacciones trabajan juntas
PostgreSQL verifica las restricciones de integridad (FOREIGN KEY, NOT NULL, UNIQUE, CHECK) dentro de la transaccion. Si una restriccion se viola, la operacion falla y puedes hacer ROLLBACK sin dano:
BEGIN;
-- Intentar insertar un pedido para un cliente que no existeINSERT INTO pedidos (cliente_id, fecha, total, estado)VALUES (9999, CURRENT_DATE, 100, 'pendiente');-- ERROR: insert or update on table "pedidos" violates-- foreign key constraint "pedidos_cliente_id_fkey"
-- La restriccion FOREIGN KEY protegio la integridad.-- Ningun dato quedo a medias.ROLLBACK;Regla de oro de integridad
Siempre que una operacion involucre mas de una tabla o mas de una sentencia que dependan entre si, usa una transaccion. Es la unica forma de garantizar que tus datos se mantengan consistentes ante cualquier fallo.
Propiedades ACID
Las transacciones garantizan cuatro propiedades conocidas como ACID:
| Comando | Descripcion |
|---|---|
| Atomicidad | Todo o nada. Si una operacion falla, se revierten todas. No hay estados parciales. |
| Consistencia | La BD pasa de un estado valido a otro estado valido. Las restricciones (NOT NULL, FOREIGN KEY, CHECK) se verifican. Nunca quedan datos a medias. |
| Aislamiento | Las transacciones concurrentes no se interfieren. Cada una ve una 'foto' consistente de los datos hasta que se confirme. |
| Durabilidad | Una vez que haces COMMIT, los datos sobreviven incluso a un corte de luz o un crash del servidor. PostgreSQL escribe en disco antes de confirmar. |
Estas propiedades son lo que diferencia una base de datos relacional de un simple archivo de texto. Sin ACID, no puedes confiar en que tus datos sean correctos.
Ejemplo practico: procesar un pedido
Este es el caso de uso mas comun de transacciones. Procesar un pedido involucra varias tablas que deben mantenerse consistentes:
BEGIN;
-- 1. Crear el pedidoINSERT INTO pedidos (cliente_id, fecha, total, estado)VALUES (3, CURRENT_DATE, 0, 'pendiente')RETURNING id;-- Supongamos que devuelve id = 25
-- 2. Agregar productos al detalleINSERT INTO detalle_pedidos (pedido_id, producto_id, cantidad, precio_unitario)VALUES (25, 1, 2, 299.99), -- 2 unidades del producto 1 (25, 5, 1, 49.99); -- 1 unidad del producto 5
-- 3. Actualizar stockUPDATE productos SET stock = stock - 2 WHERE id = 1;UPDATE productos SET stock = stock - 1 WHERE id = 5;
-- 4. Actualizar el total del pedidoUPDATE pedidosSET total = ( SELECT SUM(cantidad * precio_unitario) FROM detalle_pedidos WHERE pedido_id = 25)WHERE id = 25;
-- 5. Todo salio bien, confirmarCOMMIT;Si cualquier paso falla (por ejemplo, el producto no existe o el stock queda negativo), puedes hacer ROLLBACK y la base de datos queda exactamente como estaba antes.
Transacciones en produccion
En una aplicacion real, el codigo de tu programa (Python, Node.js, Java, etc.) captura errores y decide si hacer COMMIT o ROLLBACK. Nunca dejes transacciones abiertas sin cerrar: bloquean filas y degradan el rendimiento.
SAVEPOINT: Puntos de guardado parciales
A veces quieres revertir solo parte de una transaccion. Para eso existen los SAVEPOINT:
BEGIN;
-- Insertar pedidoINSERT INTO pedidos (cliente_id, fecha, total, estado)VALUES (2, CURRENT_DATE, 150.00, 'pendiente');
-- Crear punto de guardadoSAVEPOINT antes_de_stock;
-- Intentar actualizar stockUPDATE productos SET stock = stock - 100 WHERE id = 3;
-- Verificar que no quedo negativo-- (si quedo negativo, revertir solo la actualizacion de stock)ROLLBACK TO SAVEPOINT antes_de_stock;
-- El pedido sigue existiendo, pero el stock no se toco-- Podemos intentar con otra cantidadUPDATE productos SET stock = stock - 1 WHERE id = 3;
COMMIT;| Comando | Descripcion |
|---|---|
| SAVEPOINT nombre | Crea un punto de guardado dentro de la transaccion. |
| ROLLBACK TO SAVEPOINT nombre | Revierte todo lo hecho DESPUES del savepoint. La transaccion sigue activa. |
| RELEASE SAVEPOINT nombre | Elimina el savepoint (libera recursos). Los cambios permanecen. |
Puedes anidar savepoints:
BEGIN;
INSERT INTO pedidos (cliente_id, fecha, total, estado)VALUES (1, CURRENT_DATE, 500.00, 'pendiente');
SAVEPOINT sp1;
INSERT INTO detalle_pedidos (pedido_id, producto_id, cantidad, precio_unitario) VALUES (26, 1, 5, 299.99);
SAVEPOINT sp2;
UPDATE productos SET stock = stock - 5 WHERE id = 1; -- Si falla, podemos volver a sp2, sp1, o hacer ROLLBACK completo
ROLLBACK TO SAVEPOINT sp2; -- Solo se deshizo el UPDATE, el INSERT de detalle sigue
ROLLBACK TO SAVEPOINT sp1;-- Se deshizo el INSERT de detalle tambien, solo queda el pedido
COMMIT;Errores dentro de transacciones
En PostgreSQL, si ocurre un error dentro de una transaccion, esta queda en estado abortado. No puedes ejecutar mas sentencias hasta que hagas ROLLBACK:
BEGIN;
INSERT INTO pedidos (cliente_id, fecha, total, estado)VALUES (1, CURRENT_DATE, 100, 'pendiente');
-- Esto causa un error (supongamos que viola una restriccion)INSERT INTO detalle_pedidos (pedido_id, producto_id, cantidad, precio_unitario)VALUES (999, 999, 1, 10.00);-- ERROR: insert or update on table "detalle_pedidos" violates-- foreign key constraint
-- La transaccion esta en estado "abortado"-- Cualquier sentencia que ejecutes ahora dara:-- ERROR: current transaction is aborted
-- La UNICA opcion es ROLLBACKROLLBACK;SAVEPOINT para manejar errores
Si quieres manejar errores sin perder toda la transaccion, usa SAVEPOINT antes de operaciones riesgosas. Si falla, haz ROLLBACK TO SAVEPOINT y continua con otra estrategia.
Transacciones y bloqueos
Cuando modificas una fila dentro de una transaccion, PostgreSQL bloquea esa fila hasta que hagas COMMIT o ROLLBACK. Otros usuarios que intenten modificar la misma fila tendran que esperar.
-- Sesion A:BEGIN;UPDATE productos SET stock = stock - 1 WHERE id = 5;-- La fila id=5 esta bloqueada para escritura
-- Sesion B (al mismo tiempo):UPDATE productos SET stock = stock + 10 WHERE id = 5;-- Sesion B se QUEDA ESPERANDO hasta que Sesion A-- haga COMMIT o ROLLBACK
-- Sesion A:COMMIT;-- Ahora Sesion B puede continuarDeadlocks
Si la Sesion A bloquea la fila 1 y espera la fila 2, mientras la Sesion B bloquea la fila 2 y espera la fila 1, se produce un deadlock (bloqueo mutuo). PostgreSQL detecta deadlocks automaticamente y cancela una de las transacciones con un error. La solucion es siempre bloquear las filas en el mismo orden.
Niveles de aislamiento
PostgreSQL soporta cuatro niveles de aislamiento que controlan cuanto “ve” una transaccion de los cambios hechos por otras transacciones concurrentes:
| Comando | Descripcion |
|---|---|
| READ UNCOMMITTED | En PostgreSQL se comporta igual que READ COMMITTED (no permite lecturas sucias). |
| READ COMMITTED (default) | Cada sentencia ve los datos confirmados hasta ese momento. Si otra transaccion hizo COMMIT entre tus sentencias, veras los nuevos datos. |
| REPEATABLE READ | La transaccion ve una 'foto' de los datos al inicio. No importa si otros hacen COMMIT mientras tanto, siempre ves lo mismo. |
| SERIALIZABLE | El nivel mas estricto. Simula que las transacciones se ejecutan una despues de otra. PostgreSQL puede cancelar transacciones si detecta conflictos. |
-- Cambiar el nivel de aislamiento (debe ser lo primero despues de BEGIN)BEGIN;SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Ahora esta transaccion siempre vera la misma foto de los datosSELECT SUM(total) FROM pedidos WHERE estado = 'completado';-- ... otras operaciones ...-- Aunque otro usuario agregue pedidos completados mientras tanto,-- esta consulta siempre devuelve el mismo resultado
COMMIT;Nota
Para la mayoria de las aplicaciones, el nivel por defecto READ COMMITTED funciona bien. Usa REPEATABLE READ cuando necesites consistencia absoluta en lecturas (como generar reportes financieros). SERIALIZABLE es para casos muy especificos donde no puedes tolerar ninguna anomalia.
Patron practico: UPDATE seguro con verificacion
Un patron muy util es usar transacciones para verificar antes de confirmar:
BEGIN;
-- Verificar el estado actualSELECT id, nombre, stock FROM productos WHERE id = 3;
-- Actualizar solo si tiene suficiente stockUPDATE productos SET stock = stock - 5 WHERE id = 3 AND stock >= 5;
-- Verificar cuantas filas se actualizaron-- Si 0 filas, significa que no habia suficiente stock
-- Si todo esta bienCOMMIT;
-- Si algo no salio como esperabas-- ROLLBACK;Y para operaciones masivas peligrosas:
BEGIN;
-- Primero ver que vamos a eliminarSELECT COUNT(*) FROM pedidos WHERE estado = 'cancelado' AND fecha < '2024-01-01';-- Resultado: 47 filas
-- Si el numero parece correcto, eliminarDELETE FROM detalle_pedidosWHERE pedido_id IN ( SELECT id FROM pedidos WHERE estado = 'cancelado' AND fecha < '2024-01-01');
DELETE FROM pedidos WHERE estado = 'cancelado' AND fecha < '2024-01-01';
-- Verificar que todo quedo bienSELECT COUNT(*) FROM pedidos WHERE estado = 'cancelado' AND fecha < '2024-01-01';-- Resultado: 0 filas ✓
COMMIT;-- (o ROLLBACK si algo no cuadra)EXPLAIN ANALYZE seguro
Si quieres probar el plan de ejecucion de un DELETE o UPDATE sin aplicarlo realmente, envuelvelo en una transaccion que luego reviertes:
BEGIN;EXPLAIN ANALYZE DELETE FROM pedidos WHERE estado = 'cancelado';ROLLBACK; -- Los datos no se eliminaronEjercicios
Ejercicio 1: Escribe una transaccion que inserte un nuevo cliente y un pedido para ese cliente. Si la insercion del pedido falla, ambos cambios deben revertirse.
Ver solucion
BEGIN;
INSERT INTO clientes (nombre, email, ciudad)VALUES ('Daniela Rojas', 'daniela@email.com', 'Temuco');
-- Obtener el ID del nuevo cliente-- (asumiendo que es el ultimo insertado)INSERT INTO pedidos (cliente_id, fecha, total, estado)VALUES ( (SELECT id FROM clientes WHERE email = 'daniela@email.com'), CURRENT_DATE, 250.00, 'pendiente');
COMMIT;-- Si cualquier INSERT falla, ejecutar ROLLBACK en su lugarEjercicio 2: Crea una transaccion que aplique un 15% de descuento a todos los productos de la categoria ‘Muebles’. Usa un SELECT antes y despues del UPDATE para verificar los cambios. No hagas COMMIT todavia — termina con ROLLBACK para que los precios no cambien realmente.
Ver solucion
BEGIN;
-- Ver precios actualesSELECT nombre, precio, categoriaFROM productosWHERE categoria = 'Muebles'ORDER BY precio DESC;
-- Aplicar descuentoUPDATE productosSET precio = ROUND(precio * 0.85, 2)WHERE categoria = 'Muebles';
-- Verificar cambiosSELECT nombre, precio, categoriaFROM productosWHERE categoria = 'Muebles'ORDER BY precio DESC;
-- Revertir (no queremos aplicar el descuento realmente)ROLLBACK;Ejercicio 3: Escribe una transaccion con SAVEPOINT que intente actualizar el stock de dos productos. Si la segunda actualizacion dejaria el stock negativo, revierte solo esa operacion (con ROLLBACK TO SAVEPOINT), pero mantiene la primera.
Ver solucion
BEGIN;
-- Primera actualizacion (segura)UPDATE productos SET stock = stock - 1 WHERE id = 1;
-- Punto de guardadoSAVEPOINT antes_segundo_update;
-- Segunda actualizacion (podria dejar stock negativo)UPDATE productos SET stock = stock - 999 WHERE id = 2;
-- Verificar si quedo negativo-- (en una app real, esto lo haria el codigo del programa)SELECT id, nombre, stock FROM productos WHERE id = 2;
-- Si stock < 0, revertir solo la segunda operacionROLLBACK TO SAVEPOINT antes_segundo_update;
-- La primera actualizacion sigue en pieCOMMIT;Ejercicio 4: Simula el procesamiento completo de un pedido: insertar el pedido, agregar 2 productos al detalle, actualizar el stock de esos productos, y calcular el total del pedido. Todo dentro de una transaccion.
Ver solucion
BEGIN;
-- 1. Crear pedido (cliente_id = 2)INSERT INTO pedidos (cliente_id, fecha, total, estado)VALUES (2, CURRENT_DATE, 0, 'pendiente')RETURNING id;-- Supongamos que devuelve id = 30
-- 2. Agregar productosINSERT INTO detalle_pedidos (pedido_id, producto_id, cantidad, precio_unitario)VALUES (30, 3, 2, (SELECT precio FROM productos WHERE id = 3)), (30, 7, 1, (SELECT precio FROM productos WHERE id = 7));
-- 3. Actualizar stockUPDATE productos SET stock = stock - 2 WHERE id = 3;UPDATE productos SET stock = stock - 1 WHERE id = 7;
-- 4. Calcular y actualizar totalUPDATE pedidosSET total = ( SELECT SUM(cantidad * precio_unitario) FROM detalle_pedidos WHERE pedido_id = 30)WHERE id = 30;
-- 5. VerificarSELECT p.id, p.total, p.estado, dp.producto_id, dp.cantidad, dp.precio_unitarioFROM pedidos pJOIN detalle_pedidos dp ON p.id = dp.pedido_idWHERE p.id = 30;
-- 6. Confirmar (o ROLLBACK para practicar sin modificar datos)ROLLBACK;Ejercicio 5: Explica que pasa en cada paso de esta secuencia y cual es el estado final de los datos:
BEGIN;UPDATE productos SET precio = 999 WHERE id = 1;SAVEPOINT sp1;UPDATE productos SET precio = 0 WHERE id = 1;ROLLBACK TO SAVEPOINT sp1;COMMIT;Ver solucion
Paso a paso:
BEGIN— Inicia la transaccion.UPDATE ... precio = 999— El precio del producto 1 cambia a 999 (dentro de la transaccion).SAVEPOINT sp1— Se crea un punto de guardado. En este punto, precio = 999.UPDATE ... precio = 0— El precio cambia a 0 (dentro de la transaccion).ROLLBACK TO SAVEPOINT sp1— Se deshace todo lo hecho despues de sp1. El precio vuelve a 999.COMMIT— Se confirma la transaccion. El precio final es 999.
El UPDATE ... precio = 0 se descarto con el ROLLBACK TO SAVEPOINT, pero el UPDATE ... precio = 999 (que fue antes del savepoint) se mantuvo y se confirmo con COMMIT.
Vistas y vistas materializadas
Cuando tienes una consulta compleja que usas una y otra vez — un reporte de ventas, un listado de clientes VIP, un resumen de inventario — copiar y pegar ese SQL en cada lugar es tedioso y propenso a errores. Las vistas te permiten guardar esa consulta con un nombre y usarla como si fuera una tabla.
Que es una vista?
Una vista es una consulta SQL guardada con un nombre. No almacena datos; cada vez que la consultas, PostgreSQL ejecuta la consulta original y te devuelve el resultado actualizado.
Sin vista: Con vista: ┌──────────────────────────────┐ ┌──────────────────────┐ │ SELECT c.nombre, SUM(p.total)│ │ SELECT * FROM │ │ FROM clientes c │ → │ resumen_clientes; │ │ JOIN pedidos p ON ... │ │ │ │ GROUP BY c.nombre; │ │ (mismo resultado) │ └──────────────────────────────┘ └──────────────────────┘ (repetir en cada reporte) (escribir una vez)CREATE VIEW
CREATE VIEW nombre_vista AS SELECT ...;Creemos algunas vistas utiles con nuestra base de datos:
Vista: resumen de clientes
CREATE VIEW resumen_clientes ASSELECT c.id, c.nombre, c.ciudad, COUNT(p.id) AS total_pedidos, COALESCE(SUM(p.total), 0) AS gasto_total, MAX(p.fecha) AS ultimo_pedidoFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.id, c.nombre, c.ciudad;Ahora puedes usarla como si fuera una tabla:
-- Todos los clientes con su resumenSELECT * FROM resumen_clientes ORDER BY gasto_total DESC;
-- Filtrar clientes VIPSELECT nombre, ciudad, gasto_totalFROM resumen_clientesWHERE gasto_total > 1000;
-- Clientes que nunca compraronSELECT nombre, ciudadFROM resumen_clientesWHERE total_pedidos = 0;Vista: inventario con estado
CREATE VIEW inventario_estado ASSELECT p.id, p.nombre, p.categoria, p.precio, p.stock, COALESCE(SUM(dp.cantidad), 0) AS unidades_vendidas, CASE WHEN p.stock = 0 THEN 'Agotado' WHEN p.stock < 10 THEN 'Stock bajo' ELSE 'Disponible' END AS estado_stockFROM productos pLEFT JOIN detalle_pedidos dp ON p.id = dp.producto_idGROUP BY p.id, p.nombre, p.categoria, p.precio, p.stock;-- Productos con stock bajoSELECT nombre, categoria, stock, estado_stockFROM inventario_estadoWHERE estado_stock = 'Stock bajo'ORDER BY stock ASC;
-- Categoria con mas ventasSELECT categoria, SUM(unidades_vendidas) AS total_vendidoFROM inventario_estadoGROUP BY categoriaORDER BY total_vendido DESC;Vista: detalle completo de pedidos
CREATE VIEW detalle_pedidos_completo ASSELECT p.id AS pedido_id, p.fecha, p.estado, c.nombre AS cliente, c.ciudad, pr.nombre AS producto, pr.categoria, dp.cantidad, dp.precio_unitario, (dp.cantidad * dp.precio_unitario) AS subtotalFROM pedidos pINNER JOIN clientes c ON p.cliente_id = c.idINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idINNER JOIN productos pr ON dp.producto_id = pr.id;-- Ahora consultas de 4 tablas se vuelven simples:SELECT cliente, producto, cantidad, subtotalFROM detalle_pedidos_completoWHERE estado = 'completado'ORDER BY fecha DESC;
-- Ventas por categoriaSELECT categoria, SUM(subtotal) AS total_ventasFROM detalle_pedidos_completoWHERE estado = 'completado'GROUP BY categoriaORDER BY total_ventas DESC;Las vistas simplifican, no duplican
Una vista no copia los datos. Es solo un “atajo” a una consulta. Cuando insertas un nuevo pedido en la tabla pedidos, la vista detalle_pedidos_completo lo incluye automaticamente la proxima vez que la consultes.
Paso a paso: que ocurre cuando consultas una vista
Tu escribes: SELECT * FROM resumen_clientes WHERE ciudad = 'Santiago';
PostgreSQL hace: 1. Busca la definicion de resumen_clientes 2. Reemplaza la vista por su consulta original: SELECT * FROM ( SELECT c.id, c.nombre, c.ciudad, COUNT(p.id) AS total_pedidos, ... FROM clientes c LEFT JOIN pedidos p ON ... GROUP BY c.id, c.nombre, c.ciudad ) AS resumen_clientes WHERE ciudad = 'Santiago'; 3. Optimiza y ejecuta la consulta combinada 4. Te devuelve el resultadoPostgreSQL es inteligente: no ejecuta la consulta completa y luego filtra. Combina tu WHERE con la consulta de la vista y optimiza todo junto. En el ejemplo, filtra por ciudad = 'Santiago' antes de agrupar, lo que es mas eficiente.
Modificar y eliminar vistas
CREATE OR REPLACE VIEW
Si necesitas cambiar la definicion de una vista:
-- Modificar la vista (agrega email)CREATE OR REPLACE VIEW resumen_clientes ASSELECT c.id, c.nombre, c.email, -- nueva columna c.ciudad, COUNT(p.id) AS total_pedidos, COALESCE(SUM(p.total), 0) AS gasto_total, MAX(p.fecha) AS ultimo_pedidoFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.id, c.nombre, c.email, c.ciudad;Limitaciones de CREATE OR REPLACE
CREATE OR REPLACE VIEW solo permite agregar columnas al final. No puedes eliminar columnas existentes ni cambiar su tipo. Si necesitas hacer eso, debes hacer DROP VIEW primero y luego CREATE VIEW.
DROP VIEW
-- Eliminar vistaDROP VIEW resumen_clientes;
-- Eliminar solo si existe (sin error)DROP VIEW IF EXISTS resumen_clientes;
-- Si otras vistas dependen de esta, CASCADE las elimina tambienDROP VIEW resumen_clientes CASCADE;Vistas actualizables
En ciertos casos, puedes hacer INSERT, UPDATE y DELETE directamente sobre una vista, y los cambios se aplican a la tabla subyacente:
-- Vista simple sobre una sola tablaCREATE VIEW productos_electronica ASSELECT id, nombre, precio, stockFROM productosWHERE categoria = 'Electronica';
-- Esto funciona! Actualiza la tabla productosUPDATE productos_electronica SET precio = 599.99 WHERE id = 1;
-- Insertar a traves de la vistaINSERT INTO productos_electronica (nombre, precio, stock)VALUES ('Auriculares Pro', 89.99, 75);-- Nota: la columna categoria no se establece automaticamenteLas condiciones para que una vista sea actualizable:
| Comando | Descripcion |
|---|---|
| Una sola tabla | El FROM debe referenciar exactamente una tabla (sin JOINs). |
| Sin agregaciones | No puede usar GROUP BY, HAVING, DISTINCT ni funciones de agregacion. |
| Sin subconsultas en SELECT | Las columnas deben venir directamente de la tabla. |
| Sin LIMIT/OFFSET | No debe limitar las filas. |
WITH CHECK OPTION
Puedes agregar WITH CHECK OPTION al crear la vista para que PostgreSQL rechace inserciones o actualizaciones que no cumplan el filtro de la vista:
CREATE VIEW productos_electronica ASSELECT id, nombre, precio, stockFROM productosWHERE categoria = 'Electronica'WITH CHECK OPTION;
-- Esto falla porque categoria seria NULL, no 'Electronica':INSERT INTO productos_electronica (nombre, precio, stock)VALUES ('Silla Gamer', 299.99, 20);-- ERROR: new row violates check option for viewVistas materializadas
Una vista normal ejecuta la consulta cada vez que la consultas. Si la consulta es lenta (por ejemplo, resume millones de filas), esto puede ser un problema. Las vistas materializadas guardan el resultado en disco, como una tabla “cache”:
Vista normal: Vista materializada: ┌──────────────┐ ┌──────────────────┐ │ Consulta → │ Cada vez que │ Consulta → │ Una vez │ ejecuta la │ la usas │ guarda datos │ (al crear │ query │ │ en disco │ o refrescar) │ original │ │ │ └──────────────┘ └──────────────────┘ Siempre actualizada Rapida pero puede Puede ser lenta estar desactualizadaCrear y refrescar
-- Crear vista materializadaCREATE MATERIALIZED VIEW mv_ventas_por_categoria ASSELECT pr.categoria, COUNT(DISTINCT p.id) AS total_pedidos, SUM(dp.cantidad) AS unidades_vendidas, ROUND(SUM(dp.cantidad * dp.precio_unitario), 2) AS ingresosFROM pedidos pINNER JOIN detalle_pedidos dp ON p.id = dp.pedido_idINNER JOIN productos pr ON dp.producto_id = pr.idWHERE p.estado = 'completado'GROUP BY pr.categoria;-- Consultar (lee de disco, muy rapido)SELECT * FROM mv_ventas_por_categoria ORDER BY ingresos DESC;Los datos no se actualizan automaticamente. Debes refrescar manualmente:
-- Refrescar (recalcula toda la vista)REFRESH MATERIALIZED VIEW mv_ventas_por_categoria;
-- Refrescar sin bloquear lecturas (requiere un indice UNIQUE)REFRESH MATERIALIZED VIEW CONCURRENTLY mv_ventas_por_categoria;Cuando refrescar?
Depende de tu caso de uso. Algunas opciones:
- Manualmente despues de cargar datos nuevos
- Con un cron job cada hora/dia
- Con un trigger que refresque al insertar en la tabla base (cuidado: puede ser lento si se ejecuta con cada INSERT)
Indices en vistas materializadas
Como las vistas materializadas guardan datos en disco, puedes crear indices sobre ellas:
-- Indice unico (necesario para REFRESH CONCURRENTLY)CREATE UNIQUE INDEX idx_mv_ventas_cat ON mv_ventas_por_categoria(categoria);
-- Ahora puedes hacer REFRESH sin bloquear lecturasREFRESH MATERIALIZED VIEW CONCURRENTLY mv_ventas_por_categoria;Eliminar
DROP MATERIALIZED VIEW mv_ventas_por_categoria;DROP MATERIALIZED VIEW IF EXISTS mv_ventas_por_categoria;Cuando usar cada opcion
| Comando | Descripcion |
|---|---|
| Vista (VIEW) | Consultas frecuentes que quieres simplificar. Siempre datos actualizados. Sin costo de almacenamiento extra. |
| Vista materializada | Consultas lentas cuyos datos no necesitan estar al segundo. Reportes, dashboards, agregaciones pesadas. |
| CTE (WITH ...) | Consulta temporal que solo necesitas dentro de una query. No se guarda, no se reutiliza. |
| Subconsulta | Similar al CTE pero inline. Util para casos simples donde un CTE seria excesivo. |
Regla practica
Si copias y pegas la misma consulta en mas de 2 lugares → crea una vista. Si esa vista es lenta y no necesitas datos en tiempo real → convierte a vista materializada.
Ver vistas existentes
-- Listar todas las vistasSELECT table_name, table_typeFROM information_schema.tablesWHERE table_schema = 'public' AND table_type = 'VIEW'ORDER BY table_name;
-- Ver la definicion de una vistaSELECT pg_get_viewdef('resumen_clientes', true);
-- Listar vistas materializadasSELECT matviewname, definitionFROM pg_matviewsWHERE schemaname = 'public';
-- Comando rapido en psql\dv -- listar vistas\dm -- listar vistas materializadasEjercicios
Ejercicio 1: Crea una vista llamada empleados_con_jefe que muestre el nombre del empleado, su departamento, su salario y el nombre de su jefe. Para empleados sin jefe, debe mostrar ‘Sin jefe’.
Ver solucion
CREATE VIEW empleados_con_jefe ASSELECT e.id, e.nombre AS empleado, e.departamento, e.salario, COALESCE(j.nombre, 'Sin jefe') AS jefeFROM empleados eLEFT JOIN empleados j ON e.jefe_id = j.id;
-- Uso:SELECT * FROM empleados_con_jefe ORDER BY departamento, salario DESC;Ejercicio 2: Crea una vista llamada ventas_mensuales que muestre: mes (en formato YYYY-MM), total de pedidos, ingresos totales y ticket promedio. Solo incluye pedidos completados.
Ver solucion
CREATE VIEW ventas_mensuales ASSELECT TO_CHAR(fecha, 'YYYY-MM') AS mes, COUNT(*) AS total_pedidos, SUM(total) AS ingresos, ROUND(AVG(total), 2) AS ticket_promedioFROM pedidosWHERE estado = 'completado'GROUP BY TO_CHAR(fecha, 'YYYY-MM');
-- Uso:SELECT * FROM ventas_mensuales ORDER BY mes DESC;Ejercicio 3: Crea una vista materializada llamada mv_top_productos que muestre los 10 productos mas vendidos con: nombre, categoria, total de unidades vendidas e ingresos generados. Agrega un indice unico.
Ver solucion
CREATE MATERIALIZED VIEW mv_top_productos ASSELECT pr.id, pr.nombre, pr.categoria, SUM(dp.cantidad) AS unidades_vendidas, ROUND(SUM(dp.cantidad * dp.precio_unitario), 2) AS ingresosFROM productos prINNER JOIN detalle_pedidos dp ON pr.id = dp.producto_idINNER JOIN pedidos p ON dp.pedido_id = p.idWHERE p.estado = 'completado'GROUP BY pr.id, pr.nombre, pr.categoriaORDER BY unidades_vendidas DESCLIMIT 10;
-- Indice unicoCREATE UNIQUE INDEX idx_mv_top_prod ON mv_top_productos(id);
-- Uso:SELECT * FROM mv_top_productos;
-- Refrescar cuando cambien los datosREFRESH MATERIALIZED VIEW CONCURRENTLY mv_top_productos;Ejercicio 4: Usando la vista detalle_pedidos_completo (creada arriba en el modulo), escribe una consulta que muestre las ventas totales por ciudad y categoria. Ordena por ciudad y de mayor a menor venta.
Ver solucion
SELECT ciudad, categoria, SUM(subtotal) AS total_ventas, COUNT(*) AS lineas_vendidasFROM detalle_pedidos_completoWHERE estado = 'completado'GROUP BY ciudad, categoriaORDER BY ciudad, total_ventas DESC;Nota como la vista simplifica esta consulta: sin la vista, necesitarias 4 JOINs. Con la vista, es un simple SELECT ... GROUP BY sobre una sola “tabla”.
Ejercicio 5: Crea una vista actualizable llamada productos_accesorios que muestre id, nombre, precio y stock de los productos de la categoria ‘Accesorios’. Agrega WITH CHECK OPTION. Luego intenta: (a) actualizar el precio de un producto, (b) insertar un producto con categoria ‘Electronica’ y explica por que falla.
Ver solucion
CREATE VIEW productos_accesorios ASSELECT id, nombre, precio, stockFROM productosWHERE categoria = 'Accesorios'WITH CHECK OPTION;
-- (a) Esto funciona: actualiza en la tabla productosUPDATE productos_accesorios SET precio = precio * 0.9 WHERE stock > 50;
-- (b) Esto falla:INSERT INTO productos_accesorios (nombre, precio, stock)VALUES ('Cable HDMI', 15.99, 200);-- ERROR: new row violates check option for view "productos_accesorios"-- Porque la vista filtra por categoria = 'Accesorios', pero el INSERT-- no especifica la categoria (queda NULL), que no cumple el filtro.-- WITH CHECK OPTION impide insertar filas que no serian visibles en la vista.Bases de datos vectoriales con pgvector
Las bases de datos tradicionales son excelentes para buscar coincidencias exactas: “dame el producto con id 5” o “clientes en Santiago”. Pero que pasa cuando necesitas buscar por significado? Por ejemplo, “productos similares a auriculares” o “textos que hablen de tecnologia”. Para eso existen las bases de datos vectoriales, y PostgreSQL puede hacerlo gracias a pgvector.
Que son los vectores?
Un vector es simplemente una lista ordenada de numeros. En el contexto de datos, representan una posicion en un espacio multidimensional.
Ejemplo en 2 dimensiones (facil de visualizar):
"Auriculares Bluetooth" → [0.8, 0.3] (mucha tecnologia, poco hogar) "Laptop Pro" → [0.9, 0.2] (mucha tecnologia, poco hogar) "Mesa de Comedor" → [0.1, 0.9] (poca tecnologia, mucho hogar) "Lampara LED" → [0.4, 0.7] (algo de tecnologia, bastante hogar)
tecnologia ↑ 1.0 | • Laptop | • Auriculares 0.5 | | • Lampara | • Mesa 0.0 +-------------------→ hogar 0.0 0.5 1.0Productos cercanos en este espacio son similares en significado. “Auriculares” y “Laptop” estan cerca porque ambos son tecnologia.
Que son los embeddings?
En la practica, los vectores no se crean a mano. Se generan con modelos de inteligencia artificial llamados modelos de embeddings. Estos modelos convierten texto (o imagenes, audio, etc.) en vectores de cientos o miles de dimensiones.
Modelo de embeddings (ej: OpenAI, Sentence Transformers)
"Auriculares inalambricos" → [0.023, -0.841, 0.156, ..., 0.447] (1536 dimensiones) "Audifonos Bluetooth" → [0.019, -0.838, 0.161, ..., 0.442] (muy similar!) "Mesa de madera" → [0.712, 0.203, -0.445, ..., 0.089] (muy diferente)Modelos de embeddings populares
Cloud (APIs):
- OpenAI (
text-embedding-3-small): 1536 dimensiones - Google (
text-embedding-004): 768 dimensiones - Cohere (
embed-v3): 1024 dimensiones - Voyage AI (
voyage-3): 1024 dimensiones
Locales (puedes correrlos en tu maquina con Ollama):
- nomic-embed-text: 768 dimensiones — ligero y rapido
- mxbai-embed-large: 1024 dimensiones — buen balance calidad/velocidad
- snowflake-arctic-embed: 1024 dimensiones — alto rendimiento
- all-minilm (Sentence Transformers): 384 dimensiones — el mas liviano
No necesitas entrenar estos modelos. Solo les envias texto y te devuelven el vector.
Con Ollama puedes generar embeddings localmente sin depender de APIs externas:
ollama pull nomic-embed-textcurl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text", "prompt": "Auriculares Bluetooth"}'Para que sirve la busqueda vectorial?
La busqueda vectorial te permite encontrar elementos semanticamente similares, no solo coincidencias exactas de texto:
| Caso de uso | Busqueda tradicional | Busqueda vectorial |
|---|---|---|
| Productos similares | WHERE categoria = 'Electronica' | Productos con descripcion similar |
| Busqueda de texto | WHERE nombre LIKE '%auric%' | ”audifonos inalambricos” encuentra “Auriculares Bluetooth” |
| Recomendaciones | Reglas manuales complejas | Productos cercanos en el espacio vectorial |
| Deteccion de duplicados | Comparacion exacta | Textos con el mismo significado |
| RAG (IA generativa) | No aplica | Buscar contexto relevante para un LLM |
pgvector: vectores en PostgreSQL
pgvector es una extension de PostgreSQL que agrega soporte para almacenar y buscar vectores. No necesitas una base de datos separada — tus vectores conviven con tus datos relacionales.
Instalacion
Instalacion del servidor
pgvector debe estar instalado a nivel del servidor PostgreSQL antes de poder usar CREATE EXTENSION. Revisa las instrucciones segun tu sistema operativo.
Linux (Debian/Ubuntu):
sudo apt install postgresql-17-pgvectormacOS (Homebrew):
brew install pgvectorWindows:
Si instalaste PostgreSQL con el instalador de EDB, puedes compilar pgvector con Visual Studio, o usar Docker que es la opcion mas simple. Tambien puedes usar pgvector para Windows siguiendo las instrucciones del repositorio oficial.
Docker (cualquier sistema operativo):
docker run -e POSTGRES_PASSWORD=postgres -p 5432:5432 pgvector/pgvector:pg17Una vez instalado en el servidor, activa la extension dentro de tu base de datos:
CREATE EXTENSION IF NOT EXISTS vector;El tipo de dato vector
pgvector agrega el tipo vector(n) donde n es el numero de dimensiones:
-- Crear una tabla con una columna vectorialCREATE TABLE productos_embeddings ( id SERIAL PRIMARY KEY, producto_id INTEGER REFERENCES productos(id), descripcion TEXT, embedding vector(3) -- vector de 3 dimensiones (ejemplo simplificado));En produccion usarias vectores de 384, 768 o 1536 dimensiones, pero para aprender usaremos dimensiones pequenas.
Operaciones basicas
Insertar vectores
-- Los vectores se escriben como arrays entre corchetesINSERT INTO productos_embeddings (producto_id, descripcion, embedding)VALUES (1, 'Laptop de alta gama para profesionales', '[0.8, 0.2, 0.9]'), (2, 'Silla ergonomica para oficina', '[0.1, 0.9, 0.3]'), (3, 'Teclado mecanico para gaming', '[0.7, 0.3, 0.8]'), (4, 'Escritorio de madera ajustable', '[0.2, 0.8, 0.4]'), (5, 'Monitor curvo 4K', '[0.9, 0.2, 0.7]'), (6, 'Lampara de escritorio LED', '[0.3, 0.7, 0.5]');Consultar vectores
SELECT producto_id, descripcion, embeddingFROM productos_embeddings; producto_id | descripcion | embedding-------------+----------------------------------------+----------- 1 | Laptop de alta gama para profesionales | [0.8,0.2,0.9] 2 | Silla ergonomica para oficina | [0.1,0.9,0.3] 3 | Teclado mecanico para gaming | [0.7,0.3,0.8] ...Busqueda por similitud
El corazon de pgvector son los operadores de distancia. Cuanto menor la distancia entre dos vectores, mas similares son.
Operadores de distancia
| Operador | Tipo de distancia | Uso tipico |
|---|---|---|
<-> | Distancia euclidiana (L2) | Distancia geometrica directa |
<=> | Distancia coseno | Similitud de significado (el mas usado) |
<#> | Producto interno negativo | Cuando los vectores estan normalizados |
Ejemplo: encontrar productos similares
Supongamos que un usuario esta viendo la “Laptop de alta gama” con embedding [0.8, 0.2, 0.9]. Busquemos productos similares:
-- Encontrar los 3 productos mas similares a la LaptopSELECT producto_id, descripcion, embedding <=> '[0.8, 0.2, 0.9]' AS distanciaFROM productos_embeddingsWHERE producto_id != 1 -- excluir el producto mismoORDER BY distanciaLIMIT 3; producto_id | descripcion | distancia-------------+--------------------------------+-------------------- 3 | Teclado mecanico para gaming | 0.0134... 5 | Monitor curvo 4K | 0.0210... 6 | Lampara de escritorio LED | 0.2845...El teclado y el monitor son los mas similares a la laptop — ambos son tecnologia. La lampara esta mas lejos, y la silla y escritorio estarian aun mas lejos.
Distancia coseno vs euclidiana
La distancia coseno (<=>) mide el angulo entre vectores, ignorando su magnitud. Es ideal cuando te importa la direccion (significado) y no la escala. La distancia euclidiana (<->) mide la distancia directa en el espacio. Para busqueda semantica, usa coseno.
Combinando vectores con SQL tradicional
La ventaja de pgvector es que puedes combinar busqueda vectorial con todo el SQL que ya conoces:
Busqueda con filtros
-- Productos similares a "laptop" que ademas cuesten menos de $500-- y tengan stock disponibleSELECT p.nombre, p.precio, p.stock, pe.embedding <=> '[0.8, 0.2, 0.9]' AS similitudFROM productos_embeddings peJOIN productos p ON pe.producto_id = p.idWHERE p.precio < 500 AND p.stock > 0ORDER BY similitudLIMIT 5;Busqueda con agregacion
-- Categoria con productos mas similares a un vector de busquedaSELECT p.categoria, COUNT(*) AS total_similares, AVG(pe.embedding <=> '[0.8, 0.2, 0.9]') AS distancia_promedioFROM productos_embeddings peJOIN productos p ON pe.producto_id = p.idGROUP BY p.categoriaORDER BY distancia_promedioLIMIT 3;Indices para vectores
Sin un indice, pgvector compara tu vector contra todos los vectores de la tabla (busqueda exacta). Con millones de registros, esto es muy lento. Los indices vectoriales sacrifican un poco de precision por mucha velocidad.
IVFFlat (Inverted File Index)
Divide los vectores en grupos (listas) y solo busca en los grupos mas cercanos:
-- Crear un indice IVFFlatCREATE INDEX idx_embeddings_ivfflatON productos_embeddingsUSING ivfflat (embedding vector_cosine_ops)WITH (lists = 100); Sin indice: Busca en TODOS los vectores (exacto pero lento) Con IVFFlat: Busca solo en los clusters cercanos (rapido, ~99% precision)
┌──────────────────────────────────┐ │ ● ● ○ ○ ○ ○ │ │ ● ● ○ ○ ○ │ ● = cluster cercano (se busca) │ ● △ △ ○ │ ○ = otro cluster (se ignora) │ △ △ △ ○ ○ │ △ = otro cluster (se ignora) │ ★ △ ○ │ ★ = vector de busqueda └──────────────────────────────────┘Cuantas listas usar?
Una regla general: usa sqrt(n) listas, donde n es el numero de filas. Para 1 millon de vectores, usa ~1000 listas. Mas listas = mas rapido pero necesita mas memoria y puede perder precision.
HNSW (Hierarchical Navigable Small World)
Un indice mas moderno y generalmente mas preciso que IVFFlat:
-- Crear un indice HNSWCREATE INDEX idx_embeddings_hnswON productos_embeddingsUSING hnsw (embedding vector_cosine_ops)WITH (m = 16, ef_construction = 64);Comparacion de indices
| Caracteristica | IVFFlat | HNSW |
|---|---|---|
| Velocidad de busqueda | Rapida | Muy rapida |
| Precision | Buena (~95-99%) | Muy buena (~99%+) |
| Tiempo de creacion | Rapido | Lento |
| Uso de memoria | Bajo | Alto |
| Necesita datos previos | Si (para entrenar clusters) | No |
| Recomendado para | Datasets grandes, recursos limitados | Maxima calidad de busqueda |
Importante sobre IVFFlat
El indice IVFFlat requiere que la tabla ya tenga datos al momento de crearse, porque necesita calcular los centroides de los clusters. Si insertas muchos datos nuevos despues, considera recrear el indice. HNSW no tiene esta limitacion.
Ejemplo practico: busqueda semantica en la tienda
Veamos un escenario completo integrando pgvector con nuestra base de datos tienda. Imagina que quieres agregar busqueda inteligente de productos:
Paso 1: Crear la tabla de embeddings
CREATE EXTENSION IF NOT EXISTS vector;
-- Tabla para almacenar embeddings de productosCREATE TABLE producto_embeddings ( id SERIAL PRIMARY KEY, producto_id INTEGER REFERENCES productos(id) ON DELETE CASCADE, embedding vector(384), -- Sentence Transformers dimension created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, UNIQUE(producto_id));Paso 2: Insertar embeddings (simulados)
En produccion, generarias los embeddings con un modelo de IA. Aqui simulamos con vectores aleatorios para mostrar la mecanica:
-- Insertar embeddings simulados para los productos existentesINSERT INTO producto_embeddings (producto_id, embedding)SELECT id, -- En produccion: llamar API de embeddings con el nombre del producto -- Aqui generamos un vector aleatorio de 384 dimensiones ( SELECT array_agg(random())::vector(384) FROM generate_series(1, 384) )FROM productos;Paso 3: Crear indice
CREATE INDEX idx_producto_emb_hnswON producto_embeddingsUSING hnsw (embedding vector_cosine_ops);Paso 4: Buscar productos similares
-- Funcion para buscar productos similares a uno dado-- Dado el producto con id = 1, encontrar los 5 mas similaresSELECT p.id, p.nombre, p.precio, p.categoria, pe.embedding <=> query.embedding AS distanciaFROM producto_embeddings peJOIN productos p ON pe.producto_id = p.idCROSS JOIN ( SELECT embedding FROM producto_embeddings WHERE producto_id = 1) queryWHERE pe.producto_id != 1ORDER BY distanciaLIMIT 5;Paso 5: Busqueda por texto
-- En una aplicacion real, convertirias el texto del usuario a un embedding-- usando un modelo de IA, y luego buscarias los mas cercanos:
-- Pseudocodigo del flujo:-- 1. Usuario escribe: "necesito algo para escuchar musica"-- 2. Tu app convierte eso a un vector: get_embedding("necesito algo para escuchar musica")-- 3. Buscas en PostgreSQL:
-- SELECT p.nombre, p.precio-- FROM producto_embeddings pe-- JOIN productos p ON pe.producto_id = p.id-- ORDER BY pe.embedding <=> $1 -- $1 = vector del texto del usuario-- LIMIT 5;El embedding viene de tu aplicacion
pgvector no genera embeddings. Tu aplicacion (Python, Node.js, etc.) debe llamar a un modelo de embeddings y luego enviar el vector resultante a PostgreSQL. pgvector solo se encarga de almacenar y buscar eficientemente.
Buenas practicas
-
Elige la dimension correcta: Mas dimensiones = mas precision pero mas almacenamiento y busqueda mas lenta. 384 dimensiones suele ser un buen balance.
-
Siempre crea un indice: Sin indice, cada busqueda recorre toda la tabla. Con mas de unos miles de filas, es imprescindible.
-
Usa distancia coseno para texto: Para embeddings de texto, la distancia coseno (
<=>) es casi siempre la mejor opcion. -
Normaliza si puedes: Si tus vectores estan normalizados (longitud 1), el producto interno (
<#>) es equivalente al coseno pero mas rapido. -
Combina con filtros SQL: No hagas busqueda vectorial pura. Filtra primero por columnas tradicionales (categoria, precio, stock) para reducir el espacio de busqueda.
-
Monitorea con EXPLAIN ANALYZE: Los indices vectoriales tambien aparecen en EXPLAIN, asi que puedes verificar que se estan usando:
EXPLAIN ANALYZESELECT producto_idFROM producto_embeddingsORDER BY embedding <=> '[0.1, 0.2, ...]'::vector(384)LIMIT 10;Resumen
Base de datos vectorial con pgvector:
┌──────────────────────────────────────────────────────────────┐ │ PostgreSQL + pgvector │ │ │ │ ┌─────────────────────┐ ┌─────────────────────────────┐ │ │ │ Datos relacionales │ │ Datos vectoriales │ │ │ │ │ │ │ │ │ │ productos │ │ producto_embeddings │ │ │ │ ├─ id │◄──►│ ├─ producto_id │ │ │ │ ├─ nombre │ │ ├─ embedding vector(384) │ │ │ │ ├─ precio │ │ └─ (indice HNSW) │ │ │ │ └─ categoria │ │ │ │ │ └─────────────────────┘ └─────────────────────────────┘ │ │ │ │ Puedes hacer: │ │ • JOINs entre tablas normales y vectoriales │ │ • WHERE con filtros + ORDER BY distancia vectorial │ │ • GROUP BY, agregaciones sobre resultados de similitud │ │ • Todo el SQL que ya conoces! │ └──────────────────────────────────────────────────────────────┘| Comando | Descripcion |
|---|---|
| vector(n) | Tipo de dato para almacenar vectores de n dimensiones |
| Embeddings | Vectores generados por modelos de IA que capturan significado |
| <=> | Operador de distancia coseno (el mas usado para texto) |
| <-> | Operador de distancia euclidiana (L2) |
| <#> | Operador de producto interno negativo |
| IVFFlat | Indice por clusters, rapido de crear, buena precision |
| HNSW | Indice jerarquico, mejor precision, mas uso de memoria |
| pgvector | Extension de PostgreSQL para soporte vectorial |
Ejercicios
Ejercicio 1: Crea una tabla busqueda_clientes con columnas: id SERIAL, cliente_id (FK a clientes), bio TEXT, y bio_embedding vector(3). Inserta 4 registros con vectores inventados de 3 dimensiones.
Ver solucion
CREATE TABLE busqueda_clientes ( id SERIAL PRIMARY KEY, cliente_id INTEGER REFERENCES clientes(id), bio TEXT, bio_embedding vector(3));
INSERT INTO busqueda_clientes (cliente_id, bio, bio_embedding)VALUES (1, 'Amante de la tecnologia y gadgets', '[0.9, 0.2, 0.1]'), (2, 'Aficionado al diseno de interiores', '[0.1, 0.8, 0.7]'), (3, 'Gamer y desarrollador de software', '[0.8, 0.1, 0.3]'), (4, 'Decoracion y muebles modernos', '[0.2, 0.9, 0.6]');Ejercicio 2: Usando la tabla del ejercicio anterior, encuentra los 2 clientes mas similares al cliente con bio_embedding = '[0.85, 0.15, 0.2]' (un perfil tecnologico). Usa distancia coseno y muestra el nombre del cliente (JOIN con la tabla clientes).
Ver solucion
SELECT c.nombre, bc.bio, bc.bio_embedding <=> '[0.85, 0.15, 0.2]' AS distanciaFROM busqueda_clientes bcJOIN clientes c ON bc.cliente_id = c.idORDER BY distanciaLIMIT 2;Ejercicio 3: Crea un indice HNSW sobre la columna bio_embedding de busqueda_clientes usando operaciones de distancia coseno. Luego verifica que el indice existe consultando pg_indexes.
Ver solucion
CREATE INDEX idx_bio_hnswON busqueda_clientesUSING hnsw (bio_embedding vector_cosine_ops);
-- VerificarSELECT indexname, indexdefFROM pg_indexesWHERE tablename = 'busqueda_clientes';Ejercicio 4: Escribe una consulta que combine busqueda vectorial con filtros tradicionales: encuentra clientes similares a '[0.9, 0.2, 0.1]' que ademas vivan en Santiago (usando JOIN con la tabla clientes).
Ver solucion
SELECT c.nombre, c.ciudad, bc.bio, bc.bio_embedding <=> '[0.9, 0.2, 0.1]' AS distanciaFROM busqueda_clientes bcJOIN clientes c ON bc.cliente_id = c.idWHERE c.ciudad = 'Santiago'ORDER BY distanciaLIMIT 3;Ejercicio 5: Limpia los objetos creados en los ejercicios. Elimina el indice, la tabla busqueda_clientes, y (si la creaste) la tabla producto_embeddings.
Ver solucion
-- Eliminar en orden (el indice se elimina con la tabla)DROP TABLE IF EXISTS busqueda_clientes;DROP TABLE IF EXISTS producto_embeddings;
-- Si quieres remover la extension (opcional, no recomendado si la usas)-- DROP EXTENSION vector;Ejercicios integradores
Estos ejercicios combinan todo lo que has aprendido a lo largo del curso. Estan organizados por nivel de dificultad para que vayas progresando. Intenta resolver cada uno por tu cuenta antes de mirar la solucion.
Prerequisito: base de datos de practica
Todos los ejercicios se ejecutan sobre la base de datos tienda creada en el Modulo 2. Si aun no la tienes configurada, ve al Modulo 2 y sigue los pasos para crear las tablas (productos, clientes, pedidos, detalle_pedidos, empleados) y cargar los datos de ejemplo. Si no recuerdas la estructura de las tablas, revisa el cheatsheet al final del curso.
Basico
Estos ejercicios integran los conceptos de los Modulos 1 al 5: SELECT, WHERE, ORDER BY, LIMIT, DISTINCT, BETWEEN, LIKE, IN e IS NULL. Solo trabajan con tablas individuales.
Ejercicio 1: Catalogo de productos por rango de precio
Lista los productos con precio entre $20 y $100. Muestra nombre, precio y categoria. Ordena por precio de mayor a menor.
Ver solucion
SELECT nombre, precio, categoriaFROM productosWHERE precio BETWEEN 20 AND 100ORDER BY precio DESC;Ejercicio 2: Buscar empleados por nombre
Encuentra todos los empleados cuyo nombre contiene la letra “a” (sin importar mayusculas/minusculas). Muestra nombre, departamento y salario. Ordena por salario de mayor a menor.
Pista
Usa ILIKE para busqueda case-insensitive con el patron %a%.
Ver solucion
SELECT nombre, departamento, salarioFROM empleadosWHERE nombre ILIKE '%a%'ORDER BY salario DESC;Ejercicio 3: Clientes fuera de las ciudades principales
Lista los clientes que no son de Santiago ni de Valparaiso. Muestra nombre, email y ciudad. Ordena alfabeticamente por nombre.
Ver solucion
-- Opcion 1: con NOT INSELECT nombre, email, ciudadFROM clientesWHERE ciudad NOT IN ('Santiago', 'Valparaiso')ORDER BY nombre;
-- Opcion 2: con ANDSELECT nombre, email, ciudadFROM clientesWHERE ciudad != 'Santiago' AND ciudad != 'Valparaiso'ORDER BY nombre;Ejercicio 4: Pedidos mas caros completados
Muestra los 5 pedidos con mayor total que tengan estado ‘completado’. Incluye id, fecha, total y estado.
Ver solucion
SELECT id, fecha, total, estadoFROM pedidosWHERE estado = 'completado'ORDER BY total DESCLIMIT 5;Ejercicio 5: Directores y ciudades unicas
Resuelve estas dos consultas:
(a) Encuentra los empleados que no tienen jefe (son directores). Muestra nombre, departamento y salario.
(b) Lista todas las ciudades unicas donde hay clientes registrados, ordenadas alfabeticamente.
Ver solucion
-- (a) Empleados sin jefeSELECT nombre, departamento, salarioFROM empleadosWHERE jefe_id IS NULL;
-- (b) Ciudades unicasSELECT DISTINCT ciudadFROM clientesORDER BY ciudad;Intermedio
Estos ejercicios integran conceptos de los Modulos 1 al 9: funciones de agregacion, GROUP BY, HAVING, JOIN, subconsultas, CTEs, y funciones de texto/fecha/condiciones.
Ejercicio 6: Clientes sin pedidos
Encuentra todos los clientes que nunca han realizado un pedido. Muestra su nombre y email.
Pista
Piensa en un LEFT JOIN donde la tabla derecha no tiene coincidencia, o usa NOT EXISTS.
Ver solucion
-- Opcion 1: LEFT JOIN + IS NULLSELECT c.nombre, c.emailFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_idWHERE p.id IS NULL;
-- Opcion 2: NOT EXISTSSELECT c.nombre, c.emailFROM clientes cWHERE NOT EXISTS ( SELECT 1 FROM pedidos p WHERE p.cliente_id = c.id);
-- Opcion 3: NOT IN (menos eficiente con tablas grandes)SELECT nombre, emailFROM clientesWHERE id NOT IN (SELECT cliente_id FROM pedidos);La opcion 2 con NOT EXISTS suele ser la mas eficiente en tablas grandes.
Ejercicio 7: Productos por encima del promedio
Lista los productos cuyo precio es mayor al precio promedio de su misma categoria. Muestra nombre, categoria, precio y el precio promedio de la categoria.
Pista
Necesitas una subconsulta correlacionada o un JOIN con una subconsulta que calcule el promedio por categoria.
Ver solucion
SELECT p.nombre, p.categoria, p.precio, cat_avg.promedioFROM productos pJOIN ( SELECT categoria, AVG(precio) AS promedio FROM productos GROUP BY categoria) cat_avg ON p.categoria = cat_avg.categoriaWHERE p.precio > cat_avg.promedioORDER BY p.categoria, p.precio DESC;Ejercicio 8: Resumen mensual de pedidos
Genera un resumen de pedidos por mes del ano 2024. Muestra el mes (como numero), la cantidad de pedidos, el total facturado y el promedio por pedido. Ordena por mes.
Ver solucion
SELECT EXTRACT(MONTH FROM fecha) AS mes, COUNT(*) AS cantidad_pedidos, SUM(total) AS total_facturado, ROUND(AVG(total), 2) AS promedio_por_pedidoFROM pedidosWHERE fecha >= '2024-01-01' AND fecha < '2025-01-01'GROUP BY EXTRACT(MONTH FROM fecha)ORDER BY mes;Ejercicio 9: Top 5 productos mas vendidos
Encuentra los 5 productos mas vendidos (por cantidad total). Muestra el nombre del producto, la cantidad total vendida y el ingreso total generado.
Ver solucion
SELECT p.nombre, SUM(dp.cantidad) AS total_vendido, SUM(dp.cantidad * dp.precio_unitario) AS ingreso_totalFROM productos pJOIN detalle_pedidos dp ON p.id = dp.producto_idGROUP BY p.nombreORDER BY total_vendido DESCLIMIT 5;Ejercicio 10: Clientes por ciudad con filtro
Muestra las ciudades que tienen mas de 3 clientes registrados, junto con la cantidad de clientes en cada una. Ordena de mayor a menor.
Ver solucion
SELECT ciudad, COUNT(*) AS total_clientesFROM clientesGROUP BY ciudadHAVING COUNT(*) > 3ORDER BY total_clientes DESC;Ejercicio 11: Clientes VIP
Un cliente VIP es aquel que ha gastado mas de $5,000 en total O ha realizado mas de 10 pedidos. Lista los clientes VIP con su nombre, cantidad de pedidos, gasto total y la razon por la cual son VIP (puede ser ‘gasto alto’, ‘muchos pedidos’ o ‘ambos’).
Pista
Usa un CASE para determinar la razon. Primero haz el JOIN y la agregacion, luego filtra con HAVING.
Ver solucion
SELECT c.nombre, COUNT(p.id) AS total_pedidos, SUM(p.total) AS gasto_total, CASE WHEN SUM(p.total) > 5000 AND COUNT(p.id) > 10 THEN 'ambos' WHEN SUM(p.total) > 5000 THEN 'gasto alto' WHEN COUNT(p.id) > 10 THEN 'muchos pedidos' END AS razon_vipFROM clientes cJOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombreHAVING SUM(p.total) > 5000 OR COUNT(p.id) > 10ORDER BY gasto_total DESC;Ejercicio 12: Productos que nunca se han vendido
Encuentra los productos que no aparecen en ningun detalle de pedido. Muestra nombre, precio y fecha de creacion. Ordena por fecha de creacion de mas antiguo a mas reciente.
Ver solucion
SELECT p.nombre, p.precio, p.fecha_creacionFROM productos pLEFT JOIN detalle_pedidos dp ON p.id = dp.producto_idWHERE dp.id IS NULLORDER BY p.fecha_creacion ASC;Ejercicio 13: Pedidos con muchos productos
Encuentra los pedidos que contienen mas de 5 productos diferentes. Muestra el id del pedido, la fecha, el nombre del cliente, la cantidad de productos diferentes y el total del pedido.
Ver solucion
SELECT p.id AS pedido_id, p.fecha, c.nombre AS cliente, COUNT(DISTINCT dp.producto_id) AS productos_diferentes, p.totalFROM pedidos pJOIN clientes c ON p.cliente_id = c.idJOIN detalle_pedidos dp ON p.id = dp.pedido_idGROUP BY p.id, p.fecha, c.nombre, p.totalHAVING COUNT(DISTINCT dp.producto_id) > 5ORDER BY productos_diferentes DESC;Ejercicio 14: Empleados que ganan mas que su jefe
Usando la tabla empleados con la columna jefe_id (que referencia a otro empleado), encuentra los empleados que ganan mas que su jefe. Muestra el nombre del empleado, su salario, el nombre del jefe y el salario del jefe.
Ver solucion
SELECT e.nombre AS empleado, e.salario AS salario_empleado, j.nombre AS jefe, j.salario AS salario_jefeFROM empleados eJOIN empleados j ON e.jefe_id = j.idWHERE e.salario > j.salarioORDER BY (e.salario - j.salario) DESC;Avanzado
Estos ejercicios integran todos los conceptos del curso (Modulos 1 al 13): window functions, CTEs recursivas, optimizacion, DML, metadatos y analisis estadistico.
Ejercicio 15: Ranking de clientes por ciudad
Para cada ciudad, muestra los 3 clientes que mas han gastado. Incluye el nombre del cliente, la ciudad y el total gastado.
Pista
Necesitas funciones de ventana. ROW_NUMBER() o RANK() particionado por ciudad.
Ver solucion
WITH clientes_gasto AS ( SELECT c.nombre, c.ciudad, SUM(p.total) AS total_gastado, ROW_NUMBER() OVER (PARTITION BY c.ciudad ORDER BY SUM(p.total) DESC) AS ranking FROM clientes c JOIN pedidos p ON c.id = p.cliente_id GROUP BY c.nombre, c.ciudad)SELECT nombre, ciudad, total_gastado, rankingFROM clientes_gastoWHERE ranking <= 3ORDER BY ciudad, ranking;Ejercicio 16: Variacion de ventas mes a mes
Calcula las ventas totales por mes en 2024 y muestra la diferencia porcentual respecto al mes anterior. Muestra mes, total del mes, total del mes anterior y el porcentaje de cambio.
Pista
Usa LAG() como funcion de ventana para acceder al valor del mes anterior.
Ver solucion
WITH ventas_mensuales AS ( SELECT EXTRACT(MONTH FROM fecha)::INTEGER AS mes, SUM(total) AS total_mes FROM pedidos WHERE fecha >= '2024-01-01' AND fecha < '2025-01-01' GROUP BY EXTRACT(MONTH FROM fecha) ORDER BY mes)SELECT mes, total_mes, LAG(total_mes) OVER (ORDER BY mes) AS mes_anterior, ROUND( (total_mes - LAG(total_mes) OVER (ORDER BY mes)) / LAG(total_mes) OVER (ORDER BY mes) * 100, 2 ) AS variacion_porcentualFROM ventas_mensuales;Ejercicio 17: Analisis de cohortes simplificado
Agrupa a los clientes por el mes en que hicieron su primer pedido (cohorte). Para cada cohorte, muestra cuantos clientes tiene y cuanto gastaron en total en su primer mes vs. los meses siguientes.
Pista
Primero identifica el primer pedido de cada cliente con MIN(). Luego clasifica los pedidos como “primer mes” o “meses siguientes”.
Ver solucion
WITH primer_pedido AS ( SELECT cliente_id, DATE_TRUNC('month', MIN(fecha)) AS cohorte FROM pedidos GROUP BY cliente_id),pedidos_clasificados AS ( SELECT pp.cohorte, p.cliente_id, p.total, CASE WHEN DATE_TRUNC('month', p.fecha) = pp.cohorte THEN 'primer_mes' ELSE 'meses_siguientes' END AS periodo FROM pedidos p JOIN primer_pedido pp ON p.cliente_id = pp.cliente_id)SELECT TO_CHAR(cohorte, 'YYYY-MM') AS cohorte, COUNT(DISTINCT cliente_id) AS total_clientes, SUM(CASE WHEN periodo = 'primer_mes' THEN total ELSE 0 END) AS gasto_primer_mes, SUM(CASE WHEN periodo = 'meses_siguientes' THEN total ELSE 0 END) AS gasto_posteriorFROM pedidos_clasificadosGROUP BY cohorteORDER BY cohorte;Ejercicio 18: Productos frecuentemente comprados juntos
Encuentra pares de productos que se compran juntos en el mismo pedido con frecuencia. Muestra los nombres de ambos productos y cuantas veces aparecen en el mismo pedido. Solo muestra pares que aparezcan al menos 3 veces.
Pista
Necesitas un self-join de detalle_pedidos consigo misma, unida por pedido_id. Usa una condicion para evitar pares duplicados (producto A con B es lo mismo que B con A).
Ver solucion
SELECT p1.nombre AS producto_1, p2.nombre AS producto_2, COUNT(*) AS veces_juntosFROM detalle_pedidos dp1JOIN detalle_pedidos dp2 ON dp1.pedido_id = dp2.pedido_id AND dp1.producto_id < dp2.producto_id -- evita duplicados y auto-paresJOIN productos p1 ON dp1.producto_id = p1.idJOIN productos p2 ON dp2.producto_id = p2.idGROUP BY p1.nombre, p2.nombreHAVING COUNT(*) >= 3ORDER BY veces_juntos DESC;Ejercicio 19: Detectar pedidos anomalos
Un pedido es “anomalo” si su total es mas de 3 desviaciones estandar por encima del promedio de pedidos de ese mismo cliente. Encuentra estos pedidos y muestra el id del pedido, el cliente, el total del pedido, el promedio del cliente y cuantas desviaciones estandar representa.
Pista
Calcula promedio y desviacion estandar por cliente con funciones de ventana, luego filtra.
Ver solucion
WITH stats_cliente AS ( SELECT p.id AS pedido_id, c.nombre AS cliente, p.total, AVG(p.total) OVER (PARTITION BY p.cliente_id) AS promedio_cliente, STDDEV(p.total) OVER (PARTITION BY p.cliente_id) AS desviacion_cliente FROM pedidos p JOIN clientes c ON p.cliente_id = c.id)SELECT pedido_id, cliente, total, ROUND(promedio_cliente, 2) AS promedio, ROUND(desviacion_cliente, 2) AS desviacion, ROUND((total - promedio_cliente) / NULLIF(desviacion_cliente, 0), 2) AS desviaciones_sobre_mediaFROM stats_clienteWHERE desviacion_cliente > 0 AND (total - promedio_cliente) / desviacion_cliente > 3ORDER BY desviaciones_sobre_media DESC;Nota: usamos NULLIF(desviacion_cliente, 0) para evitar division por cero en caso de clientes con un solo pedido.
Ejercicio 20: Dashboard de resumen completo
Crea una consulta que genere un resumen ejecutivo con una sola consulta. Debe devolver una fila con:
- Total de clientes activos (que han hecho al menos un pedido)
- Total de ingresos del mes actual
- Total de ingresos del mes anterior
- Porcentaje de cambio entre ambos meses
- El producto mas vendido del mes actual (por cantidad)
- La ciudad con mas pedidos del mes actual
Pista
Usa multiples CTEs, una para cada metrica, y luego cruza los resultados con un CROSS JOIN.
Ver solucion
WITH clientes_activos AS ( SELECT COUNT(DISTINCT cliente_id) AS total FROM pedidos),ingresos_actual AS ( SELECT COALESCE(SUM(total), 0) AS total FROM pedidos WHERE DATE_TRUNC('month', fecha) = DATE_TRUNC('month', CURRENT_DATE)),ingresos_anterior AS ( SELECT COALESCE(SUM(total), 0) AS total FROM pedidos WHERE DATE_TRUNC('month', fecha) = DATE_TRUNC('month', CURRENT_DATE) - INTERVAL '1 month'),producto_top AS ( SELECT p.nombre FROM detalle_pedidos dp JOIN productos p ON dp.producto_id = p.id JOIN pedidos pe ON dp.pedido_id = pe.id WHERE DATE_TRUNC('month', pe.fecha) = DATE_TRUNC('month', CURRENT_DATE) GROUP BY p.nombre ORDER BY SUM(dp.cantidad) DESC LIMIT 1),ciudad_top AS ( SELECT c.ciudad FROM pedidos p JOIN clientes c ON p.cliente_id = c.id WHERE DATE_TRUNC('month', p.fecha) = DATE_TRUNC('month', CURRENT_DATE) GROUP BY c.ciudad ORDER BY COUNT(*) DESC LIMIT 1)SELECT ca.total AS clientes_activos, ia.total AS ingresos_mes_actual, ian.total AS ingresos_mes_anterior, CASE WHEN ian.total = 0 THEN NULL ELSE ROUND((ia.total - ian.total) / ian.total * 100, 2) END AS variacion_porcentual, pt.nombre AS producto_top, ct.ciudad AS ciudad_topFROM clientes_activos caCROSS JOIN ingresos_actual iaCROSS JOIN ingresos_anterior ianCROSS JOIN producto_top ptCROSS JOIN ciudad_top ct;Ejercicio 21: Optimiza esta consulta
La siguiente consulta es funcional pero lenta. Reescribela para que sea mas eficiente y sugiere los indices necesarios:
SELECT *FROM clientes cWHERE (SELECT SUM(p.total) FROM pedidos p WHERE p.cliente_id = c.id AND EXTRACT(YEAR FROM p.fecha) = 2024) > 1000ORDER BY (SELECT SUM(p.total) FROM pedidos p WHERE p.cliente_id = c.id AND EXTRACT(YEAR FROM p.fecha) = 2024) DESC;Pista
La subconsulta se ejecuta dos veces por cada cliente (una en WHERE, otra en ORDER BY). Ademas, usa EXTRACT() sobre una columna que deberia estar indexada.
Ver solucion
-- Consulta optimizada: subconsulta solo una vez con CTE, sin funciones en columnasWITH gasto_2024 AS ( SELECT cliente_id, SUM(total) AS gasto_total FROM pedidos WHERE fecha >= '2024-01-01' AND fecha < '2025-01-01' GROUP BY cliente_id HAVING SUM(total) > 1000)SELECT c.nombre, c.email, c.ciudad, g.gasto_totalFROM clientes cJOIN gasto_2024 g ON c.id = g.cliente_idORDER BY g.gasto_total DESC;
-- Indices recomendados:CREATE INDEX idx_pedidos_fecha ON pedidos(fecha);CREATE INDEX idx_pedidos_cliente_fecha ON pedidos(cliente_id, fecha);Mejoras realizadas:
- CTE calcula el gasto una sola vez en lugar de dos subconsultas por fila.
- Rango de fechas en vez de EXTRACT() permite usar indices.
- HAVING filtra en la agregacion, no despues.
- Columnas especificas en vez de SELECT *.
Ejercicio 22: Jerarquia de empleados
Usando la tabla empleados, genera un reporte que muestre la jerarquia completa: para cada empleado, su nombre, el nombre de su jefe directo, y el departamento. Incluye a los empleados que no tienen jefe (son los directores). Ordena por departamento y luego por salario descendente.
Ver solucion
SELECT e.nombre AS empleado, e.departamento, e.salario, COALESCE(j.nombre, 'Sin jefe (Director)') AS jefe_directoFROM empleados eLEFT JOIN empleados j ON e.jefe_id = j.idORDER BY e.departamento, e.salario DESC;Version mas avanzada con CTE recursiva para mostrar todos los niveles:
WITH RECURSIVE jerarquia AS ( -- Caso base: empleados sin jefe (directores) SELECT id, nombre, departamento, salario, jefe_id, 1 AS nivel, nombre AS cadena_jerarquia FROM empleados WHERE jefe_id IS NULL
UNION ALL
-- Caso recursivo: empleados con jefe SELECT e.id, e.nombre, e.departamento, e.salario, e.jefe_id, j.nivel + 1, j.cadena_jerarquia || ' > ' || e.nombre FROM empleados e JOIN jerarquia j ON e.jefe_id = j.id)SELECT nombre, departamento, salario, nivel, cadena_jerarquiaFROM jerarquiaORDER BY cadena_jerarquia;Ejercicio 23: Analisis de stock critico
Identifica los productos cuyo stock es menor que la cantidad promedio vendida por mes en los ultimos 6 meses. Estos productos estan en riesgo de quedarse sin inventario. Muestra el nombre, stock actual, promedio mensual de ventas y para cuantos meses alcanza el stock.
Ver solucion
WITH ventas_mensuales AS ( SELECT dp.producto_id, EXTRACT(MONTH FROM pe.fecha) AS mes, EXTRACT(YEAR FROM pe.fecha) AS anio, SUM(dp.cantidad) AS vendido_en_mes FROM detalle_pedidos dp JOIN pedidos pe ON dp.pedido_id = pe.id WHERE pe.fecha >= CURRENT_DATE - INTERVAL '6 months' GROUP BY dp.producto_id, EXTRACT(MONTH FROM pe.fecha), EXTRACT(YEAR FROM pe.fecha)),promedio_mensual AS ( SELECT producto_id, ROUND(AVG(vendido_en_mes), 2) AS promedio_venta_mes FROM ventas_mensuales GROUP BY producto_id)SELECT p.nombre, p.stock AS stock_actual, pm.promedio_venta_mes, ROUND(p.stock / NULLIF(pm.promedio_venta_mes, 0), 1) AS meses_de_stockFROM productos pJOIN promedio_mensual pm ON p.id = pm.producto_idWHERE p.stock < pm.promedio_venta_mesORDER BY meses_de_stock ASC;Ejercicio 24: Migracion de estructura
Este ejercicio simula una migracion de base de datos. Realiza los siguientes pasos en orden, usando transacciones para seguridad:
- Agrega una columna
descuento DECIMAL(5,2) DEFAULT 0a la tablaproductos - Actualiza el descuento segun la categoria: ‘Electronica’ = 10%, ‘Muebles’ = 15%, ‘Accesorios’ = 5%
- Verifica los cambios con un SELECT
- Renombra la columna
descuentoadescuento_porcentaje - Finalmente, elimina la columna (para dejar la tabla como estaba)
Pista
Usa BEGIN y COMMIT para envolver toda la operacion en una transaccion. Si algo falla, puedes usar ROLLBACK para deshacer todo. Para el UPDATE por categoria, usa CASE.
Ver solucion
BEGIN;
-- 1. Agregar columnaALTER TABLE productosADD COLUMN descuento DECIMAL(5,2) DEFAULT 0;
-- 2. Actualizar descuento por categoriaUPDATE productosSET descuento = CASE categoria WHEN 'Electronica' THEN 10.00 WHEN 'Muebles' THEN 15.00 WHEN 'Accesorios' THEN 5.00 ELSE 0.00 END;
-- 3. VerificarSELECT nombre, categoria, precio, descuento, ROUND(precio * (1 - descuento / 100), 2) AS precio_con_descuentoFROM productosORDER BY categoria, nombre;
-- 4. Renombrar columnaALTER TABLE productosRENAME COLUMN descuento TO descuento_porcentaje;
-- 5. Verificar el renameSELECT nombre, descuento_porcentaje FROM productos LIMIT 3;
-- 6. Eliminar columna (dejar la tabla como estaba)ALTER TABLE productosDROP COLUMN descuento_porcentaje;
COMMIT;Este patron de agregar → modificar → renombrar → eliminar es comun en migraciones de bases de datos reales, donde necesitas transformar la estructura de forma segura y reversible.
Consejo final
Si terminaste todos los ejercicios, intenta ejecutar EXPLAIN ANALYZE en tus soluciones y piensa como podrias crear indices para mejorar el rendimiento. La optimizacion es un musculo que se entrena con practica.
Errores comunes y sus soluciones
Todos cometemos errores con SQL. La diferencia entre un principiante y alguien con experiencia no es que el segundo no cometa errores, sino que los reconoce mas rapido. Aqui tienes los errores mas comunes que vas a encontrar (o que ya encontraste) con sus soluciones.
1. Columna no encontrada (typos y alias incorrectos)
El error:
SELECT nmobre, precio FROM productos;ERROR: column "nmobre" does not existHINT: Perhaps you meant to reference the column "productos.nombre".Por que pasa: Un simple typo. Tambien pasa cuando usas un alias de tabla y te equivocas en la referencia:
SELECT c.nombre, p.totalFROM clientes AS cliJOIN pedidos AS ped ON cli.id = ped.cliente_id;-- Error: "c" no existe, definiste "cli"Como solucionarlo: Revisa la ortografia. Si usas alias, se consistente. PostgreSQL te da una pista (“Perhaps you meant…”), leela.
-- CorrectoSELECT cli.nombre, ped.totalFROM clientes AS cliJOIN pedidos AS ped ON cli.id = ped.cliente_id;Tip
Usa alias cortos pero descriptivos. c para clientes, p para pedidos, dp para detalle_pedidos. Y una vez que defines el alias, usa solo el alias, nunca mezcles con el nombre original de la tabla.
2. Funcion de agregacion sin GROUP BY
El error:
SELECT categoria, COUNT(*)FROM productos;ERROR: column "productos.categoria" must appear in the GROUP BY clauseor be used in an aggregate functionPor que pasa: Estas mezclando una columna normal (categoria) con una funcion de agregacion (COUNT(*)). SQL no sabe como combinar valores individuales con valores agregados sin un GROUP BY.
Piensalo asi: COUNT(*) devuelve UN numero. Pero categoria tiene muchos valores. Como los emparejas?
Como solucionarlo: Agrega GROUP BY con todas las columnas no agregadas:
SELECT categoria, COUNT(*)FROM productosGROUP BY categoria;3. Usar WHERE en vez de HAVING con agregados
El error:
SELECT categoria, AVG(precio) AS precio_promedioFROM productosGROUP BY categoriaWHERE AVG(precio) > 100;ERROR: syntax error at or near "WHERE"Por que pasa: WHERE filtra filas antes de la agregacion. No puedes usar funciones de agregacion en WHERE porque los grupos todavia no existen en ese momento. Es como intentar saber el promedio de la clase antes de recoger los examenes.
Como solucionarlo: Usa HAVING para filtrar despues de la agregacion:
SELECT categoria, AVG(precio) AS precio_promedioFROM productosGROUP BY categoriaHAVING AVG(precio) > 100;| Comando | Descripcion |
|---|---|
| WHERE | Filtra filas **antes** de agrupar. No permite funciones de agregacion. |
| HAVING | Filtra grupos **despues** de agrupar. Si permite funciones de agregacion. |
4. Olvidar la condicion de JOIN (producto cartesiano)
El error:
SELECT c.nombre, p.totalFROM clientes c, pedidos p;No da error, pero devuelve muchas mas filas de las esperadas. Si tienes 100 clientes y 1,000 pedidos, esta consulta devuelve 100,000 filas (cada cliente combinado con cada pedido).
Por que pasa: Sin una condicion de JOIN, SQL combina cada fila de una tabla con cada fila de la otra. Es un producto cartesiano y casi nunca es lo que quieres.
Como solucionarlo: Siempre usa JOIN explicito con la condicion ON:
-- CorrectoSELECT c.nombre, p.totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_id;Senal de alerta
Si una consulta devuelve muchas mas filas de las esperadas, lo primero que debes revisar es si olvidaste una condicion de JOIN o si tus JOINs estan generando duplicados.
5. UPDATE o DELETE sin WHERE
El error:
-- Querias actualizar UN producto...UPDATE productos SET precio = 99.99;-- UPDATE 15 ← actualizo TODOS los productos
-- Querias borrar UN pedido...DELETE FROM pedidos;-- DELETE 15 ← borro TODOS los pedidosPor que pasa: Sin WHERE, la operacion se aplica a toda la tabla. No hay mensaje de error ni confirmacion; SQL hace exactamente lo que le pediste. El unico indicio es el numero de filas afectadas (UPDATE 15 en vez de UPDATE 1), pero para ese momento ya es tarde.
Las consecuencias:
UPDATE tabla SET columna = valor;→ todas las filas ahora tienen el mismo valor. Perdiste los datos originales.DELETE FROM tabla;→ todas las filas eliminadas. La tabla queda vacia.- En ambos casos, si no estabas dentro de una transaccion, no hay forma de deshacer el cambio (salvo restaurar un backup).
Lo mismo aplica a DELETE con WHERE incorrecto:
-- Querias borrar pedidos pendientes de enero...DELETE FROM pedidos WHERE estado = 'pendiente';-- ...pero olvidaste la condicion de fecha. Borraste TODOS los pendientes.Como prevenirlo — la tecnica SELECT primero:
-- Paso 1: SIEMPRE verifica con SELECT que filas vas a afectarSELECT id, nombre, precio FROM productos WHERE id = 42;-- Resultado: 1 fila. Perfecto, es lo que espero.
-- Paso 2: Solo si el SELECT muestra lo correcto, ejecuta el UPDATEUPDATE productos SET precio = 99.99 WHERE id = 42;-- UPDATE 1 ← confirma que solo afecto 1 filaComo prevenirlo — transacciones:
BEGIN;
-- Ejecuta tu UPDATE o DELETEUPDATE productos SET precio = 99.99 WHERE id = 42;
-- Verifica el resultadoSELECT * FROM productos WHERE id = 42;
-- Si todo esta bien:COMMIT;
-- Si algo salio mal (ejecuta esto EN VEZ de COMMIT):-- ROLLBACK;Checklist antes de UPDATE/DELETE
- ¿Tiene WHERE? Si no, probablemente es un error.
- ¿El SELECT con el mismo WHERE devuelve las filas correctas? Ejecutalo primero.
- ¿Cuantas filas va a afectar? Si esperas 1 y afecta 1000, algo esta mal.
- ¿Estas en produccion? Usa
BEGIN/COMMIToROLLBACK. - ¿Tienes backup? Si la tabla es critica, verifica antes de ejecutar.
Truco: cuenta antes de modificar
Si no estas seguro de cuantas filas va a afectar tu UPDATE o DELETE, usa COUNT primero:
-- ¿Cuantas filas voy a modificar?SELECT COUNT(*) FROM productos WHERE categoria = 'Electronica';-- Resultado: 7. OK, son los que espero.
UPDATE productos SET precio = ROUND(precio * 1.10, 2)WHERE categoria = 'Electronica';-- UPDATE 7 ← coincide con el COUNT. Perfecto.6. Comparar con NULL usando = en vez de IS NULL
El error:
SELECT * FROM empleados WHERE jefe_id = NULL;Esta consulta no devuelve ninguna fila, aunque hay empleados sin jefe.
Por que pasa: En SQL, NULL no es un valor, es la ausencia de valor. Nada es “igual” a NULL, ni siquiera NULL mismo. La expresion NULL = NULL devuelve NULL (no TRUE).
Como solucionarlo: Usa IS NULL o IS NOT NULL:
-- Correcto: encontrar empleados sin jefeSELECT * FROM empleados WHERE jefe_id IS NULL;
-- Correcto: encontrar empleados CON jefeSELECT * FROM empleados WHERE jefe_id IS NOT NULL;Esto tambien aplica a las comparaciones con != o <>:
-- Esto NO devuelve filas donde jefe_id es NULLSELECT * FROM empleados WHERE jefe_id != 5;
-- Si quieres incluir los NULL, se explicito:SELECT * FROM empleados WHERE jefe_id != 5 OR jefe_id IS NULL;7. GROUP BY con columnas faltantes
El error:
SELECT c.nombre, c.email, c.ciudad, COUNT(p.id)FROM clientes cJOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombre;ERROR: column "c.email" must appear in the GROUP BY clauseor be used in an aggregate functionPor que pasa: Cada columna en el SELECT que no esta dentro de una funcion de agregacion debe aparecer en el GROUP BY. PostgreSQL es estricto con esto (otros motores como MySQL son mas permisivos, lo cual puede dar resultados impredecibles).
Como solucionarlo: Agrega todas las columnas no agregadas al GROUP BY:
SELECT c.nombre, c.email, c.ciudad, COUNT(p.id)FROM clientes cJOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombre, c.email, c.ciudad;O, si quieres agrupar solo por una columna pero mostrar las demas, asegurate de que las columnas extra dependan funcionalmente de la columna agrupada (por ejemplo, si agrupas por c.id que es PRIMARY KEY, PostgreSQL permite las demas columnas de esa tabla):
-- Esto SI funciona porque id es PRIMARY KEYSELECT c.id, c.nombre, c.email, c.ciudad, COUNT(p.id)FROM clientes cJOIN pedidos p ON c.id = p.cliente_idGROUP BY c.id;8. Referencia ambigua a columnas
El error:
SELECT id, nombre, totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_id;ERROR: column reference "id" is ambiguousPor que pasa: Ambas tablas tienen una columna llamada id. SQL no sabe si te refieres a clientes.id o pedidos.id.
Como solucionarlo: Califica siempre las columnas con el nombre o alias de la tabla cuando haces JOIN:
SELECT c.id, c.nombre, p.totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_id;Tip
Como regla, cuando tu consulta tiene mas de una tabla, siempre usa el alias de tabla como prefijo en todas las columnas. Aunque no sea ambigua, hace la consulta mucho mas legible.
9. Comparar strings con numeros
El error:
-- La columna 'precio' es NUMERIC, pero comparas con un stringSELECT * FROM productos WHERE precio = '100';En PostgreSQL esto funciona la mayoria de las veces porque hace conversion implicita. Pero puede fallar con tipos mas complejos o causar problemas de rendimiento:
-- Esto puede impedir el uso de indices y dar resultados inesperadosSELECT * FROM clientes WHERE id = '42abc';ERROR: invalid input syntax for type integer: "42abc"Por que pasa: PostgreSQL intenta convertir el string a numero, y si el string no es un numero valido, falla.
Como solucionarlo: Usa siempre el tipo de dato correcto:
-- Correcto: numeros sin comillasSELECT * FROM productos WHERE precio = 100;SELECT * FROM clientes WHERE id = 42;
-- Correcto: strings con comillas simplesSELECT * FROM clientes WHERE email = 'ana@mail.com';10. La trampa de rendimiento de OFFSET
El error:
-- Pagina 1: rapidoSELECT * FROM productos ORDER BY id LIMIT 20 OFFSET 0;
-- Pagina 500: lentoSELECT * FROM productos ORDER BY id LIMIT 20 OFFSET 10000;Por que pasa: OFFSET 10000 no “salta” magicamente a la fila 10,000. PostgreSQL lee y descarta las primeras 10,000 filas. Cuanto mayor es el OFFSET, mas trabajo desperdiciado. En tablas grandes, las paginas finales pueden ser muy lentas.
Como solucionarlo: Usa paginacion basada en cursor (keyset pagination):
-- En vez de OFFSET, usa WHERE con el ultimo valor visto-- Si la ultima fila de la pagina anterior tenia id = 10000:SELECT * FROM productosWHERE id > 10000ORDER BY idLIMIT 20;Esta tecnica es O(log n) con un indice en id, mientras que OFFSET es O(n).
Rendimiento
Para APIs con paginacion, prefiere siempre keyset pagination sobre OFFSET. La diferencia se hace enorme en tablas con millones de filas. Pagina 1 y pagina 50,000 tardan lo mismo con keyset pagination.
11. Usar SELECT * en produccion
El error:
SELECT * FROM clientes cJOIN pedidos p ON c.id = p.cliente_idJOIN detalle_pedidos dp ON p.id = dp.pedido_idJOIN productos pr ON dp.producto_id = pr.id;Por que pasa: Parece comodo, pero trae TODAS las columnas de TODAS las tablas. Problemas:
- Rendimiento: Transfiere muchos mas datos de los necesarios.
- Impide Index Only Scan: No puede usar solo el indice si necesita todas las columnas.
- Fragilidad: Si alguien agrega una columna a la tabla, tu aplicacion puede romperse.
- Confuso: Cuando dos tablas tienen columnas con el mismo nombre (como
id), no sabes cual es cual.
Como solucionarlo: Nombra siempre las columnas que necesitas:
SELECT c.nombre AS cliente, p.fecha, pr.nombre AS producto, dp.cantidad, dp.precio_unitarioFROM clientes cJOIN pedidos p ON c.id = p.cliente_idJOIN detalle_pedidos dp ON p.id = dp.pedido_idJOIN productos pr ON dp.producto_id = pr.id;12. No crear indices donde se necesitan
El error:
-- Esta consulta se ejecuta 1,000 veces por minuto en tu aplicacionSELECT * FROM pedidos WHERE cliente_id = 42 AND estado = 'pendiente';Y nunca creaste un indice en cliente_id ni en estado. Cada ejecucion hace un Sequential Scan completo.
Por que pasa: Los indices no se crean solos (excepto para PRIMARY KEY y UNIQUE). Si no los creas explicitamente, no existen.
Como detectarlo y solucionarlo:
-- Paso 1: Verificar que hay un Seq ScanEXPLAIN ANALYZE SELECT * FROM pedidosWHERE cliente_id = 42 AND estado = 'pendiente';
-- Paso 2: Crear el indice apropiadoCREATE INDEX idx_pedidos_cliente_estado ON pedidos(cliente_id, estado);
-- Paso 3: Verificar la mejoraEXPLAIN ANALYZE SELECT * FROM pedidosWHERE cliente_id = 42 AND estado = 'pendiente';Como encontrar indices faltantes
PostgreSQL puede decirte que tablas tienen mas Sequential Scans de los deseados:
SELECT relname AS tabla, seq_scan, idx_scan, seq_scan - idx_scan AS diferenciaFROM pg_stat_user_tablesWHERE seq_scan > idx_scanORDER BY diferencia DESC;Las tablas con muchos mas seq_scan que idx_scan son candidatas a necesitar indices.
13. Usar DISTINCT para “arreglar” duplicados
El error:
-- "Tengo duplicados, le pongo DISTINCT y listo"SELECT DISTINCT c.nombre, p.totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_idJOIN detalle_pedidos dp ON p.id = dp.pedido_id;Por que pasa: Si tu consulta devuelve duplicados inesperados, el problema casi siempre es un JOIN incorrecto o faltante, no la falta de DISTINCT. DISTINCT es como poner una curita sobre una herida que necesita puntos.
En este caso, hay duplicados porque cada pedido puede tener multiples detalles, y el JOIN multiplica las filas del pedido por cada detalle.
Como solucionarlo: Analiza por que hay duplicados y arregla la causa raiz:
-- Si quieres datos de clientes y pedidos (sin detalles), quita el JOIN extraSELECT c.nombre, p.totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_id;
-- Si necesitas datos de detalles, agrega GROUP BY o reformula la consultaSELECT c.nombre, p.total, SUM(dp.cantidad) AS items_totalesFROM clientes cJOIN pedidos p ON c.id = p.cliente_idJOIN detalle_pedidos dp ON p.id = dp.pedido_idGROUP BY c.nombre, p.total;Advertencia
Si te encuentras usando DISTINCT y no puedes explicar por que hay duplicados, detente. Revisa tus JOINs. El DISTINCT esconde el problema y ademas es costoso: PostgreSQL tiene que ordenar o hacer hash de todas las filas para eliminar duplicados.
Resumen rapido
| Comando | Descripcion |
|---|---|
| Column not found | Revisa typos y que los alias coincidan |
| Agregacion sin GROUP BY | Agrega GROUP BY con todas las columnas no agregadas |
| WHERE con agregados | Usa HAVING en vez de WHERE |
| Producto cartesiano | Agrega la condicion ON al JOIN |
| UPDATE/DELETE sin WHERE | Primero haz SELECT para verificar |
| Comparar con NULL | Usa IS NULL o IS NOT NULL |
| GROUP BY incompleto | Agrega todas las columnas del SELECT al GROUP BY |
| Columna ambigua | Prefija con el alias de tabla |
| Tipo de dato incorrecto | Numeros sin comillas, strings con comillas simples |
| OFFSET lento | Usa keyset pagination (WHERE id > ultimo) |
| SELECT * | Nombra las columnas que necesitas |
| Sin indices | Usa EXPLAIN y crea indices en columnas del WHERE y JOIN |
| DISTINCT innecesario | Arregla la causa raiz de los duplicados |
Cheatsheet de SQL
Referencia rapida de todo lo que aprendiste en el curso. Guardala para consultarla cuando necesites recordar sintaxis.
Estructura basica de SELECT
SELECT columnas -- Que columnas quieresFROM tabla -- De que tablaWHERE condicion -- Filtrar filas (antes de agrupar)GROUP BY columnas -- Agrupar filasHAVING condicion_agregada -- Filtrar grupos (despues de agrupar)ORDER BY columna [ASC|DESC] -- Ordenar resultadosLIMIT n -- Limitar cantidad de filasOFFSET n; -- Saltar filas (evitar en produccion)Orden de ejecucion (no es el orden en que lo escribes):
FROM/JOIN— Obtener tablasWHERE— Filtrar filasGROUP BY— AgruparHAVING— Filtrar gruposSELECT— Elegir columnasORDER BY— OrdenarLIMIT/OFFSET— Paginar
Operadores WHERE
| Comando | Descripcion |
|---|---|
| =, !=, <>, <, >, <=, >= | WHERE precio > 100 |
| BETWEEN ... AND ... | WHERE precio BETWEEN 10 AND 50 |
| IN (...) | WHERE ciudad IN ('Madrid', 'Lima') |
| NOT IN (...) | WHERE estado NOT IN ('cancelado') |
| LIKE / ILIKE | WHERE nombre LIKE 'Ana%' (ILIKE = sin mayusculas) |
| IS NULL / IS NOT NULL | WHERE jefe_id IS NULL |
| AND, OR, NOT | WHERE precio > 100 AND stock > 0 |
| EXISTS (subconsulta) | WHERE EXISTS (SELECT 1 FROM pedidos ...) |
JOINs
-- INNER JOIN: Solo filas con coincidencia en ambas tablas Tabla A Tabla B +-------+ +-------+ | | | | | [###|#####|###] | ### = resultado | | | | +-------+ +-------+
-- LEFT JOIN: Todas las filas de A + coincidencias de B Tabla A Tabla B +-------+ +-------+ | | | | |[######|#####|###] | ### = resultado | | | | +-------+ +-------+
-- RIGHT JOIN: Coincidencias de A + todas las filas de B Tabla A Tabla B +-------+ +-------+ | | | | | [###|#####|######]| ### = resultado | | | | +-------+ +-------+
-- FULL OUTER JOIN: Todas las filas de ambas tablas Tabla A Tabla B +-------+ +-------+ | | | | |[######|#####|######]| ### = resultado | | | | +-------+ +-------+-- INNER JOINSELECT c.nombre, p.totalFROM clientes cJOIN pedidos p ON c.id = p.cliente_id;
-- LEFT JOIN (incluye clientes sin pedidos)SELECT c.nombre, p.totalFROM clientes cLEFT JOIN pedidos p ON c.id = p.cliente_id;
-- Self JOIN (tabla consigo misma)SELECT e.nombre AS empleado, j.nombre AS jefeFROM empleados eLEFT JOIN empleados j ON e.jefe_id = j.id;Funciones de agregacion
| Comando | Descripcion |
|---|---|
| COUNT(*) | Cuenta todas las filas (incluyendo NULL) |
| COUNT(columna) | Cuenta filas donde la columna no es NULL |
| COUNT(DISTINCT columna) | Cuenta valores unicos no NULL |
| SUM(columna) | Suma de valores |
| AVG(columna) | Promedio (ignora NULL) |
| MIN(columna) | Valor minimo |
| MAX(columna) | Valor maximo |
SELECT categoria, COUNT(*) AS total, ROUND(AVG(precio), 2) AS precio_promedio, MIN(precio) AS mas_barato, MAX(precio) AS mas_caroFROM productosGROUP BY categoria;STRING_AGG (concatenar filas)
-- Combinar valores de multiples filas en un textoSELECT STRING_AGG(nombre, ', ' ORDER BY nombre) FROM empleados;
-- Agrupar por departamentoSELECT departamento, STRING_AGG(nombre, ', ') AS empleadosFROM empleados GROUP BY departamento;
-- Con DISTINCT para valores unicosSELECT STRING_AGG(DISTINCT ciudad, ' | ' ORDER BY ciudad) FROM clientes;Funciones de string
| Comando | Descripcion |
|---|---|
| UPPER('hola') | HOLA |
| LOWER('HOLA') | hola |
| LENGTH('hola') | 4 |
| TRIM(' hola ') | hola |
| CONCAT('a', 'b', 'c') | abc |
| 'hola' || ' mundo' | hola mundo |
| SUBSTRING('hola' FROM 1 FOR 2) | ho |
| REPLACE('hola', 'o', 'a') | hala |
| LEFT('hola', 2) | ho |
| RIGHT('hola', 2) | la |
Funciones de fecha
| Comando | Descripcion |
|---|---|
| CURRENT_DATE | Fecha de hoy (sin hora) |
| CURRENT_TIMESTAMP / NOW() | Fecha y hora actual |
| EXTRACT(YEAR FROM fecha) | Extrae el ano (tambien MONTH, DAY, etc.) |
| DATE_TRUNC('month', fecha) | Trunca al inicio del mes |
| AGE(fecha) | Intervalo desde fecha hasta hoy |
| fecha + INTERVAL '30 days' | Suma 30 dias a la fecha |
| TO_CHAR(fecha, 'DD/MM/YYYY') | Formatea fecha como texto |
-- Pedidos de los ultimos 30 diasSELECT * FROM pedidosWHERE fecha >= CURRENT_DATE - INTERVAL '30 days';
-- Agrupar por mesSELECT DATE_TRUNC('month', fecha) AS mes, COUNT(*)FROM pedidosGROUP BY DATE_TRUNC('month', fecha);Subconsultas
-- En WHERE (escalar)SELECT * FROM productosWHERE precio > (SELECT AVG(precio) FROM productos);
-- En WHERE (lista)SELECT * FROM clientesWHERE id IN (SELECT cliente_id FROM pedidos WHERE total > 500);
-- En FROM (tabla derivada)SELECT categoria, promedioFROM ( SELECT categoria, AVG(precio) AS promedio FROM productos GROUP BY categoria) AS subWHERE promedio > 100;
-- Subconsulta correlacionadaSELECT * FROM clientes cWHERE EXISTS ( SELECT 1 FROM pedidos p WHERE p.cliente_id = c.id AND p.total > 1000);CTEs (Common Table Expressions)
-- CTE basicoWITH pedidos_grandes AS ( SELECT cliente_id, SUM(total) AS gasto FROM pedidos GROUP BY cliente_id HAVING SUM(total) > 5000)SELECT c.nombre, pg.gastoFROM clientes cJOIN pedidos_grandes pg ON c.id = pg.cliente_id;
-- Multiples CTEsWITHventas AS ( SELECT producto_id, SUM(cantidad) AS total_vendido FROM detalle_pedidos GROUP BY producto_id),top_productos AS ( SELECT producto_id, total_vendido FROM ventas ORDER BY total_vendido DESC LIMIT 10)SELECT p.nombre, tp.total_vendidoFROM productos pJOIN top_productos tp ON p.id = tp.producto_id;
-- CTE recursiva (para jerarquias)WITH RECURSIVE jerarquia AS ( SELECT id, nombre, jefe_id, 1 AS nivel FROM empleados WHERE jefe_id IS NULL UNION ALL SELECT e.id, e.nombre, e.jefe_id, j.nivel + 1 FROM empleados e JOIN jerarquia j ON e.jefe_id = j.id)SELECT * FROM jerarquia ORDER BY nivel;Modificacion de datos
-- INSERTINSERT INTO productos (nombre, precio, categoria, stock)VALUES ('Laptop Pro', 1299.99, 'Electronica', 50);
-- INSERT multipleINSERT INTO productos (nombre, precio, categoria, stock) VALUES ('Mouse', 29.99, 'Electronica', 200), ('Teclado', 59.99, 'Electronica', 150);
-- UPDATEUPDATE productos SET precio = precio * 0.9WHERE categoria = 'Electronica' AND stock > 100;
-- DELETE (siempre con WHERE!)DELETE FROM pedidos WHERE estado = 'cancelado' AND fecha < '2023-01-01';
-- INSERT con RETURNINGINSERT INTO clientes (nombre, email, ciudad)VALUES ('Ana', 'ana@email.com', 'Santiago')RETURNING id, nombre;
-- UPDATE con RETURNINGUPDATE productos SET precio = precio * 0.9WHERE categoria = 'Electronica'RETURNING id, nombre, precio;
-- Actualizar varios registros con valores distintos (CASE)UPDATE productosSET precio = CASE id WHEN 1 THEN 299.99 WHEN 2 THEN 149.50 WHEN 3 THEN 89.99 ENDWHERE id IN (1, 2, 3);
-- Actualizar varios registros con valores distintos (FROM VALUES)UPDATE productos SET precio = v.precioFROM (VALUES (1, 299.99), (2, 149.50), (3, 89.99)) AS v(id, precio)WHERE productos.id = v.id;Regla de oro: SELECT antes de UPDATE/DELETE
Siempre convierte tu UPDATE o DELETE en SELECT primero para verificar que filas vas a afectar. Un UPDATE o DELETE sin WHERE modifica toda la tabla.
ALTER TABLE
-- Agregar columnaALTER TABLE productos ADD COLUMN descripcion TEXT;ALTER TABLE productos ADD COLUMN activo BOOLEAN NOT NULL DEFAULT TRUE;
-- Eliminar columnaALTER TABLE productos DROP COLUMN descripcion;
-- Renombrar columnaALTER TABLE productos RENAME COLUMN stock TO cantidad_disponible;
-- Renombrar tablaALTER TABLE productos_backup RENAME TO productos_respaldo;
-- Cambiar tipo de datoALTER TABLE productos ALTER COLUMN nombre TYPE VARCHAR(200);
-- Agregar/quitar NOT NULLALTER TABLE productos ALTER COLUMN categoria SET NOT NULL;ALTER TABLE productos ALTER COLUMN categoria DROP NOT NULL;
-- Agregar/quitar DEFAULTALTER TABLE productos ALTER COLUMN stock SET DEFAULT 0;ALTER TABLE productos ALTER COLUMN stock DROP DEFAULT;DROP TABLE y CREATE TABLE
-- Eliminar tabla (error si no existe)DROP TABLE nombre_tabla;
-- Eliminar tabla (sin error si no existe)DROP TABLE IF EXISTS nombre_tabla;
-- Eliminar tabla y sus dependencias (foreign keys)DROP TABLE nombre_tabla CASCADE;
-- Crear tabla solo si no existeCREATE TABLE IF NOT EXISTS logs ( id SERIAL PRIMARY KEY, mensaje TEXT, fecha TIMESTAMP DEFAULT NOW());
-- SERIAL: columna auto-incremental (1, 2, 3, ...)CREATE TABLE ejemplo ( id SERIAL PRIMARY KEY, nombre VARCHAR(100) NOT NULL);
-- Copiar tabla completa (estructura + datos, sin restricciones)CREATE TABLE productos_backup AS SELECT * FROM productos;
-- Copiar solo algunas columnas/filasCREATE TABLE electronica ASSELECT nombre, precio FROM productos WHERE categoria = 'Electronica';
-- SELECT INTO (alternativa)SELECT * INTO productos_copia FROM productos WHERE stock > 50;Funciones de ventana (Window Functions)
-- Sintaxis basicafuncion() OVER ( PARTITION BY columna -- divide en grupos (opcional) ORDER BY columna -- ordena dentro del grupo (opcional))
-- Promedio por departamento (sin colapsar filas)SELECT nombre, departamento, salario, AVG(salario) OVER (PARTITION BY departamento) AS promedio_deptoFROM empleados;
-- Porcentaje del totalSELECT nombre, salario, ROUND(salario::NUMERIC / SUM(salario) OVER() * 100, 2) AS pctFROM empleados;| Comando | Descripcion |
|---|---|
| ROW_NUMBER() OVER(...) | Numero secuencial unico (1, 2, 3, 4...) |
| RANK() OVER(...) | Ranking con saltos en empates (1, 2, 2, 4...) |
| DENSE_RANK() OVER(...) | Ranking sin saltos (1, 2, 2, 3...) |
| NTILE(n) OVER(...) | Divide filas en n grupos iguales |
| LAG(col, n) OVER(...) | Valor de n filas antes |
| LEAD(col, n) OVER(...) | Valor de n filas despues |
| FIRST_VALUE(col) OVER(...) | Primer valor de la ventana |
| LAST_VALUE(col) OVER(...) | Ultimo valor (requiere ROWS UNBOUNDED FOLLOWING) |
| SUM(col) OVER(ORDER BY ...) | Suma acumulada (running total) |
| PERCENT_RANK() OVER(...) | Posicion relativa (0 a 1) |
| CUME_DIST() OVER(...) | Distribucion acumulada |
-- Patron Top-N por grupo (CTE + ROW_NUMBER)WITH ranking AS ( SELECT nombre, categoria, ROW_NUMBER() OVER (PARTITION BY categoria ORDER BY precio DESC) AS rn FROM productos)SELECT * FROM ranking WHERE rn <= 3;
-- LAG: comparar con fila anteriorSELECT fecha, total, LAG(total) OVER (ORDER BY fecha) AS anterior, total - LAG(total) OVER (ORDER BY fecha) AS diferenciaFROM pedidos;
-- Reutilizar ventana con WINDOWSELECT nombre, salario, AVG(salario) OVER w AS promedio, MIN(salario) OVER w AS minimoFROM empleadosWINDOW w AS (PARTITION BY departamento);Funciones estadisticas
| Comando | Descripcion |
|---|---|
| STDDEV(col) | Desviacion estandar (dispersion de datos) |
| VARIANCE(col) | Varianza (cuadrado de la desviacion estandar) |
| PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY col) | Mediana (percentil 50) |
| PERCENTILE_DISC(p) WITHIN GROUP (ORDER BY col) | Percentil discreto (valor real mas cercano) |
| MODE() WITHIN GROUP (ORDER BY col) | Valor mas frecuente (moda) |
-- Mediana y cuartilesSELECT PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY precio) AS p25, PERCENTILE_CONT(0.50) WITHIN GROUP (ORDER BY precio) AS mediana, PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY precio) AS p75FROM productos;FILTER (agregacion condicional, PostgreSQL)
-- Contar/sumar condicionalmente (mas legible que CASE WHEN)SELECT COUNT(*) AS total, COUNT(*) FILTER (WHERE estado = 'completado') AS completados, COUNT(*) FILTER (WHERE estado = 'pendiente') AS pendientes, AVG(total) FILTER (WHERE estado = 'completado') AS promedio_completadosFROM pedidos;GROUPING SETS, ROLLUP y CUBE
-- ROLLUP: subtotales jerarquicos + total generalSELECT COALESCE(categoria, '** TOTAL **') AS categoria, SUM(cantidad) AS unidadesFROM detalle_pedidos dp JOIN productos pr ON dp.producto_id = pr.idGROUP BY ROLLUP(pr.categoria);
-- CUBE: todas las combinaciones de subtotalesGROUP BY CUBE(categoria, estado)
-- GROUPING SETS: combinaciones especificasGROUP BY GROUPING SETS ((categoria, estado), (categoria), (estado), ())Tablas pivote (filas a columnas)
-- Ventas por cliente como columnas por mesSELECT c.nombre, SUM(CASE WHEN EXTRACT(MONTH FROM p.fecha) = 1 THEN p.total ELSE 0 END) AS enero, SUM(CASE WHEN EXTRACT(MONTH FROM p.fecha) = 2 THEN p.total ELSE 0 END) AS febreroFROM clientes c JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombre;
-- Version con FILTER (PostgreSQL)SELECT c.nombre, SUM(p.total) FILTER (WHERE EXTRACT(MONTH FROM p.fecha) = 1) AS enero, SUM(p.total) FILTER (WHERE EXTRACT(MONTH FROM p.fecha) = 2) AS febreroFROM clientes c JOIN pedidos p ON c.id = p.cliente_idGROUP BY c.nombre;Metadatos: explorar la estructura
-- Listar todas las tablasSELECT table_name FROM information_schema.tablesWHERE table_schema = 'public' ORDER BY table_name;
-- Ver columnas de una tablaSELECT column_name, data_type, is_nullable, column_defaultFROM information_schema.columnsWHERE table_name = 'productos' ORDER BY ordinal_position;
-- Ver foreign keysSELECT tc.table_name, kcu.column_name, ccu.table_name AS ref_tableFROM information_schema.table_constraints tcJOIN information_schema.key_column_usage kcu ON tc.constraint_name = kcu.constraint_nameJOIN information_schema.constraint_column_usage ccu ON tc.constraint_name = ccu.constraint_nameWHERE tc.constraint_type = 'FOREIGN KEY' AND tc.table_schema = 'public';
-- Tamano de tablasSELECT relname AS tabla, pg_size_pretty(pg_total_relation_size(oid)) AS tamanoFROM pg_class WHERE relkind = 'r' AND relnamespace = 'public'::regnamespaceORDER BY pg_total_relation_size(oid) DESC;
-- Buscar columna por nombreSELECT table_name, column_name, data_typeFROM information_schema.columnsWHERE table_schema = 'public' AND column_name LIKE '%fecha%';
-- Agregar comentario a tabla/columnaCOMMENT ON TABLE productos IS 'Catalogo de productos';COMMENT ON COLUMN productos.precio IS 'Precio sin IVA';Tipos de datos mas comunes
| Comando | Descripcion |
|---|---|
| INTEGER / INT | Numeros enteros. Ej: stock, cantidad |
| SERIAL | Entero auto-incremental para IDs |
| NUMERIC(p,s) / DECIMAL | Decimales exactos. Ej: DECIMAL(10,2) |
| VARCHAR(n) | Texto con limite. Ej: VARCHAR(100) |
| TEXT | Texto sin limite |
| BOOLEAN | TRUE / FALSE |
| DATE | Fecha (YYYY-MM-DD) |
| TIMESTAMP / TIMESTAMPTZ | Fecha + hora (con o sin zona horaria) |
| JSONB | JSON binario (permite consultas internas) |
| UUID | Identificador unico universal |
EXPLAIN: Guia rapida de lectura
EXPLAIN ANALYZE SELECT ...;| Comando | Descripcion |
|---|---|
| Seq Scan | Lee toda la tabla. Normal en tablas chicas, lento en grandes. |
| Index Scan | Usa un indice para encontrar filas. Rapido. |
| Index Only Scan | Todo esta en el indice, no va a la tabla. Lo mas rapido. |
| Bitmap Index Scan | Crea mapa de bits con el indice, luego lee paginas. |
| Nested Loop | Para cada fila de A, busca en B. Bueno con tablas chicas o indices. |
| Hash Join | Crea hash de tabla chica, recorre tabla grande. Bueno sin indice. |
| Merge Join | Ordena ambas tablas y las recorre en paralelo. |
| Sort | Ordena resultados (ORDER BY sin indice). |
| HashAggregate | Agrupacion usando tabla hash (GROUP BY). |
Que mirar en el plan:
Seq Scan on productos (cost=0.00..25.00 rows=1000 width=64) (actual time=0.01..0.32 rows=987 loops=1)- cost: Estimado por el planificador (inicio..total)
- rows: Filas estimadas vs. reales (actual)
- time: Tiempo real en milisegundos
- loops: Cuantas veces se ejecuto este nodo
Indices
-- Crear indice simpleCREATE INDEX idx_nombre ON tabla(columna);
-- Indice compuesto (orden importa)CREATE INDEX idx_nombre ON tabla(col1, col2);
-- Indice unicoCREATE UNIQUE INDEX idx_nombre ON tabla(columna);
-- Indice con INCLUDE (covering index)CREATE INDEX idx_nombre ON tabla(col_filtro) INCLUDE (col_select);
-- Indice parcial (solo algunas filas)CREATE INDEX idx_nombre ON tabla(columna) WHERE condicion;
-- Eliminar indiceDROP INDEX idx_nombre;
-- Ver indices existentesSELECT indexname, indexdefFROM pg_indexesWHERE tablename = 'mi_tabla';Cuando crear indices
- Columnas frecuentes en WHERE y JOIN ON
- Columnas en ORDER BY (si usas LIMIT)
- Columnas en GROUP BY con tablas grandes
- NO en tablas con pocas filas
- NO en columnas que se actualizan constantemente
Transacciones
-- Iniciar transaccionBEGIN;
-- Confirmar cambios (hacerlos permanentes)COMMIT;
-- Revertir cambios (deshacerlos todos)ROLLBACK;
-- Punto de guardado parcialSAVEPOINT nombre;ROLLBACK TO SAVEPOINT nombre;RELEASE SAVEPOINT nombre;
-- Nivel de aislamientoBEGIN;SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;Vistas
-- Crear vistaCREATE VIEW nombre AS SELECT ...;
-- Crear o reemplazarCREATE OR REPLACE VIEW nombre AS SELECT ...;
-- Eliminar vistaDROP VIEW IF EXISTS nombre;
-- Vista materializada (guarda datos en disco)CREATE MATERIALIZED VIEW nombre AS SELECT ...;
-- Refrescar datos de vista materializadaREFRESH MATERIALIZED VIEW nombre;
-- Refrescar sin bloquear lecturas (requiere indice UNIQUE)REFRESH MATERIALIZED VIEW CONCURRENTLY nombre;
-- Ver definicion de una vistaSELECT pg_get_viewdef('nombre_vista', true);
-- Listar vistas\dv -- en psql\dm -- vistas materializadas en psqlpgvector (bases de datos vectoriales)
-- Activar extensionCREATE EXTENSION IF NOT EXISTS vector;
-- Crear tabla con columna vectorialCREATE TABLE items ( id SERIAL PRIMARY KEY, embedding vector(384) -- 384 dimensiones);
-- Insertar vectoresINSERT INTO items (embedding) VALUES ('[0.1, 0.2, 0.3]');
-- Busqueda por similitud (distancia coseno, la mas usada)SELECT * FROM items ORDER BY embedding <=> '[0.1, 0.2, 0.3]' LIMIT 5;
-- Distancia euclidiana (L2)SELECT * FROM items ORDER BY embedding <-> '[0.1, 0.2, 0.3]' LIMIT 5;
-- Producto interno negativoSELECT * FROM items ORDER BY embedding <#> '[0.1, 0.2, 0.3]' LIMIT 5;
-- Indice HNSW (mejor precision)CREATE INDEX idx_hnsw ON itemsUSING hnsw (embedding vector_cosine_ops);
-- Indice IVFFlat (menos memoria)CREATE INDEX idx_ivf ON itemsUSING ivfflat (embedding vector_cosine_ops)WITH (lists = 100);Tablas de la base de datos de practica
-- productos-- id | nombre | precio | categoria | stock | fecha_creacion
-- clientes-- id | nombre | email | ciudad | fecha_registro
-- pedidos-- id | cliente_id | fecha | total | estado
-- detalle_pedidos-- id | pedido_id | producto_id | cantidad | precio_unitario
-- empleados-- id | nombre | departamento | salario | fecha_contratacion | jefe_id